FAANG Interview Prep
Foundations, Memory & Complexity
Big-O notation, time/space analysis, memory layoutRecursion Complete Guide
Base cases, call stack, tail recursion, memoizationArrays & Array ADT
Static/dynamic arrays, operations, amortized analysisStrings
Pattern matching, string algorithms, encoding, manipulationMatrices
2D arrays, sparse matrices, matrix operations, traversalsLinked Lists
Singly, doubly, circular lists, pointer manipulationStack
LIFO, push/pop, expression evaluation, backtrackingQueue
FIFO, circular queue, deque, priority queueTrees
Binary trees, traversals, expression trees, threaded treesBST & Balanced Trees
Search, insert, delete, AVL, red-black, B-treesHeaps, Sorting & Hashing
Min/max heaps, heapsort, hash tables, collision handlingGraphs, DP, Greedy & Backtracking
BFS, DFS, shortest paths, dynamic programming, optimizationString Fundamentals
Strings are one of the most common data types in programming and appear in nearly every FAANG interview. A string is a sequence of characters—understanding their internal representation and common operations is essential.
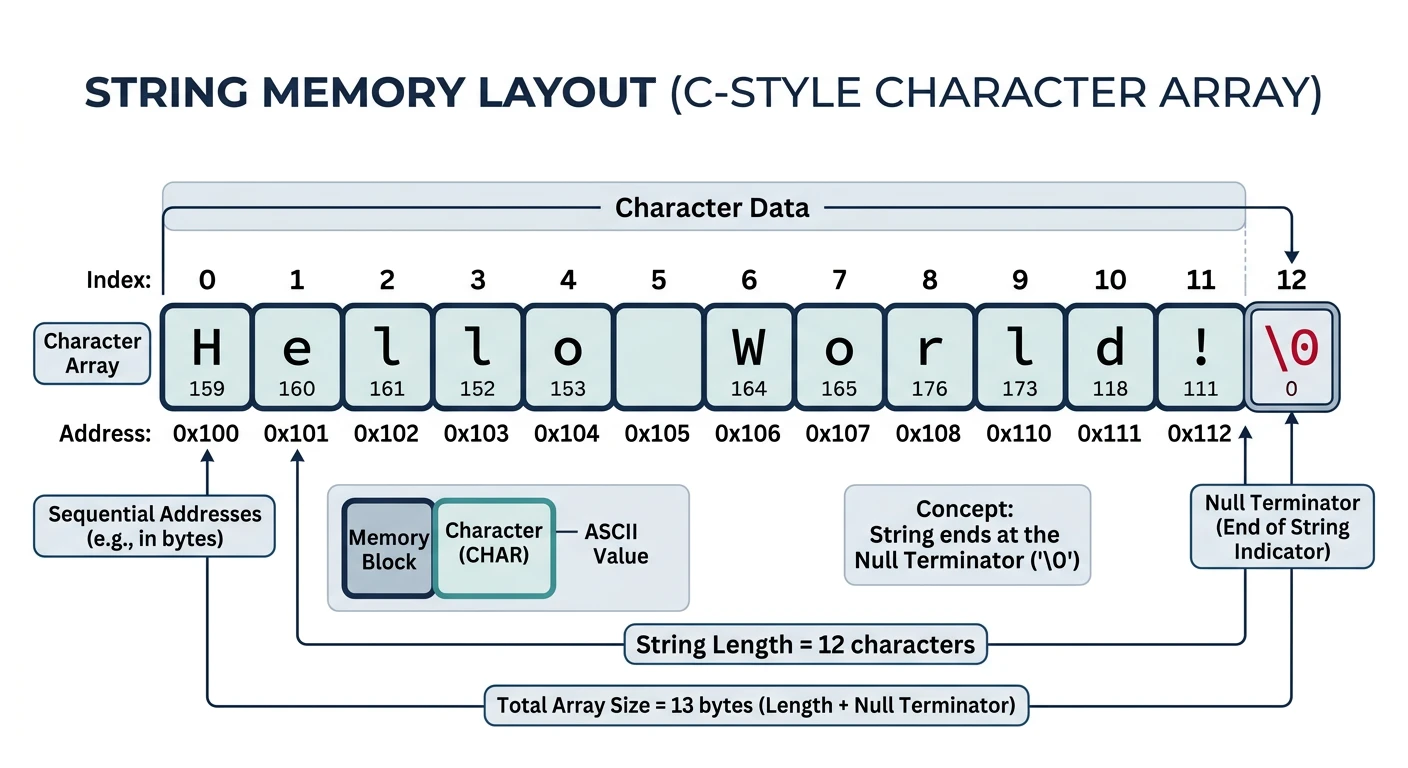
String Representation
Understanding how strings are stored in memory helps optimize string-heavy algorithms.
Basic String Operations
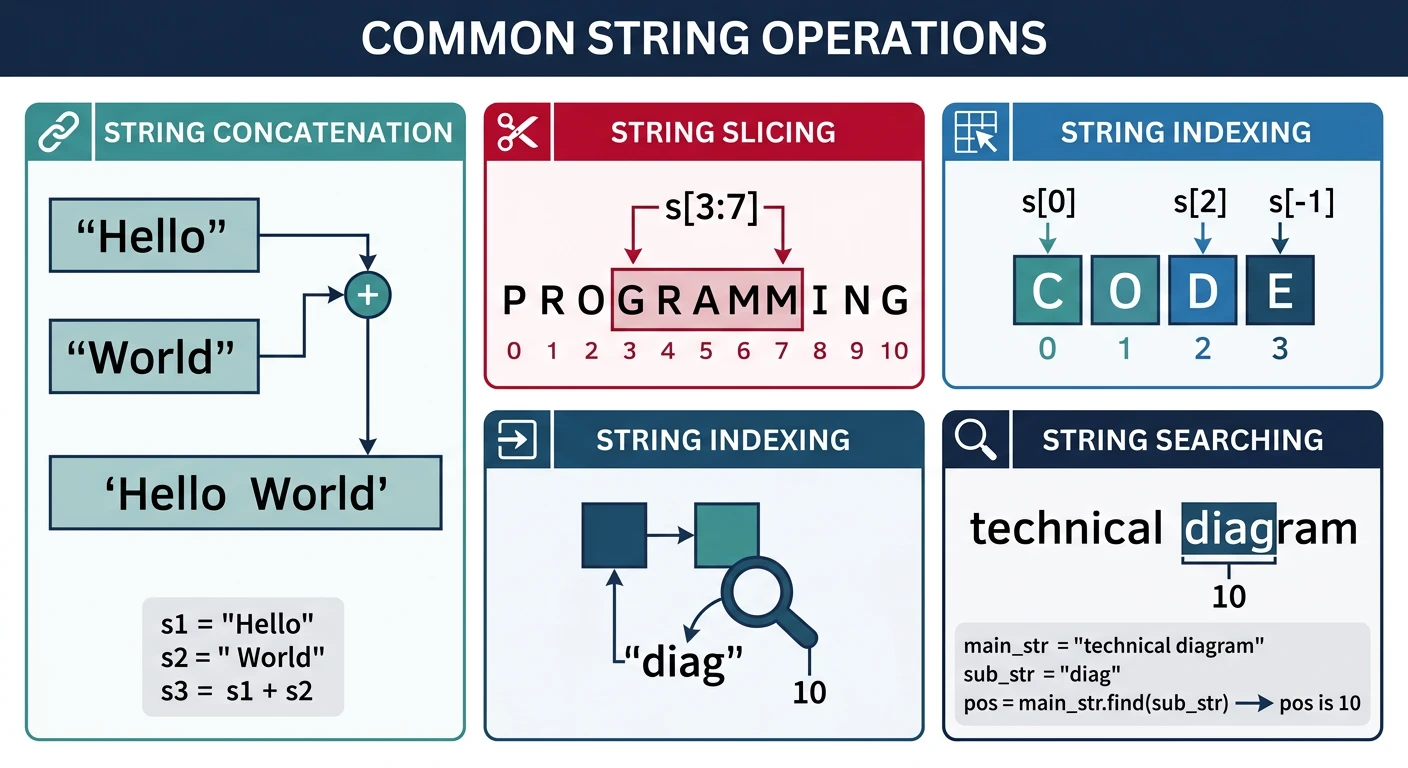
Efficient String Building
Pattern Matching Algorithms
Pattern matching—finding a pattern within a text—is a fundamental problem with applications in text editors, search engines, and bioinformatics.
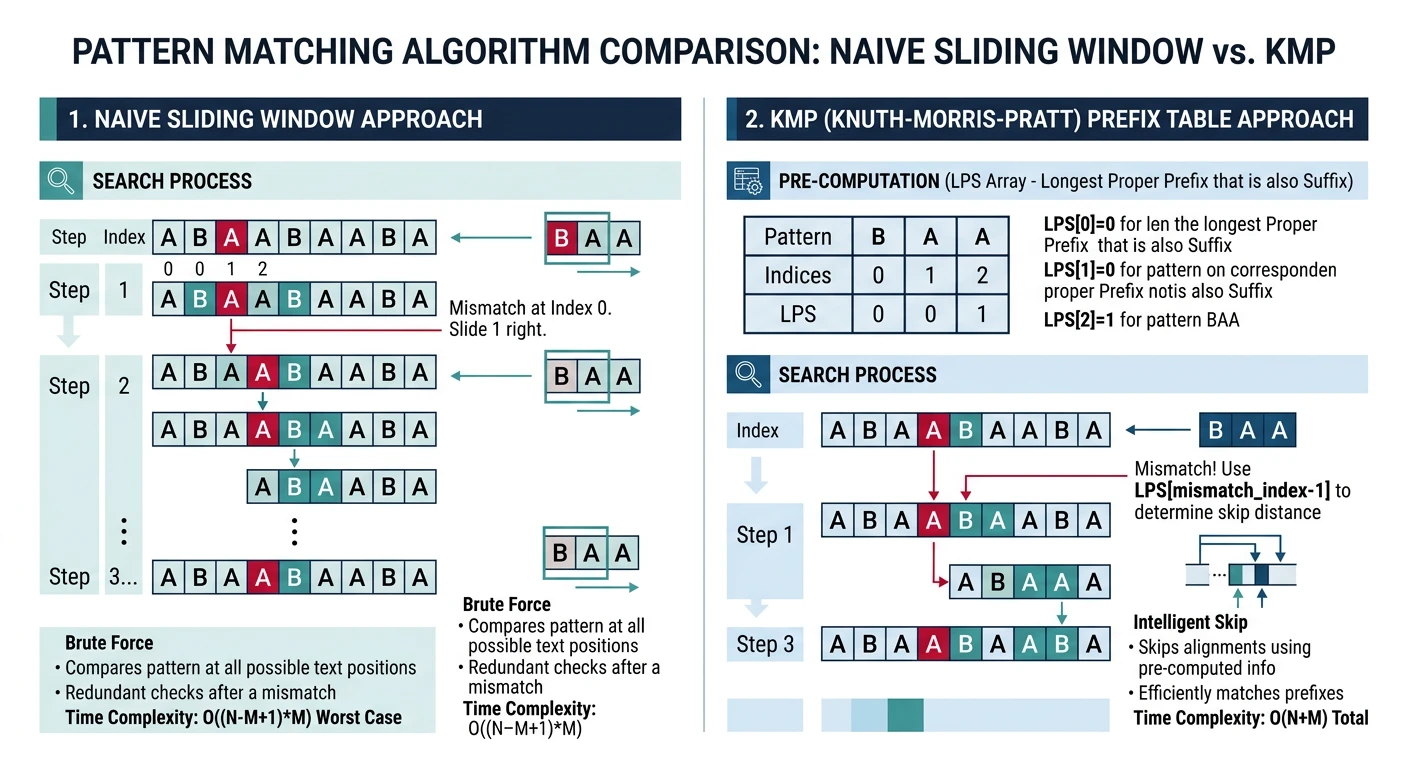
Naive (Brute Force) Algorithm
The brute force approach slides the pattern across the text one character at a time, checking for a full match at each position. At position \(i\), compare text[i..i+m-1] with pattern[0..m-1]. If any character mismatches, shift right by 1 and restart. Worst case \(O(nm)\) occurs with pathological inputs like searching "AAAB" in "AAAAAAA..." (many partial matches that fail at the last character). Despite poor worst-case, this is acceptable for short patterns and random text.
KMP (Knuth-Morris-Pratt) Algorithm
KMP achieves \(O(n + m)\) by never re-examining text characters. The key insight: when a mismatch occurs after matching \(k\) characters, the LPS (Longest Proper Prefix which is also Suffix) table tells you how far you can skip without missing any potential match. If the first \(k\) characters matched, and the LPS value for position \(k-1\) is \(j\), then the first \(j\) characters of the pattern already align correctly — resume matching from position \(j\) instead of restarting from 0.
Analogy: Imagine searching for "ABCABD" in text. If you've matched "ABCAB" and the next character fails, KMP knows that the suffix "AB" of what you matched is also a prefix of the pattern — so you can "slide" to reuse those 2 characters instead of starting over.
Rabin-Karp Algorithm
Rabin-Karp uses rolling hashes for pattern matching: compute a hash of the pattern, then slide a window across the text computing the hash of each window. If hashes match, verify character-by-character (to handle hash collisions). The "rolling" part: when the window shifts right by 1, the new hash is computed from the old hash in \(O(1)\) by removing the leftmost character's contribution and adding the new rightmost character's. Average case: \(O(n + m)\). Rabin-Karp excels at multi-pattern search (search for many patterns simultaneously) and is the basis for plagiarism detection tools.
Pattern Matching Comparison
| Algorithm | Preprocessing | Search Time | Best For |
|---|---|---|---|
| Naive | None | O(n×m) | Short patterns, simple cases |
| KMP | O(m) | \(O(n)\) | Single pattern, guaranteed linear |
| Rabin-Karp | O(m) | \(O(n)\) average | Multiple patterns, plagiarism detection |
Palindrome Algorithms
Palindromes read the same forwards and backwards. They appear frequently in interviews!

Longest Palindromic Substring
Finding the longest palindromic substring is a classic interview question. The expand-around-center approach is optimal for interviews.
Anagram Algorithms
Anagrams are words formed by rearranging letters of another word. They're common in interview questions!
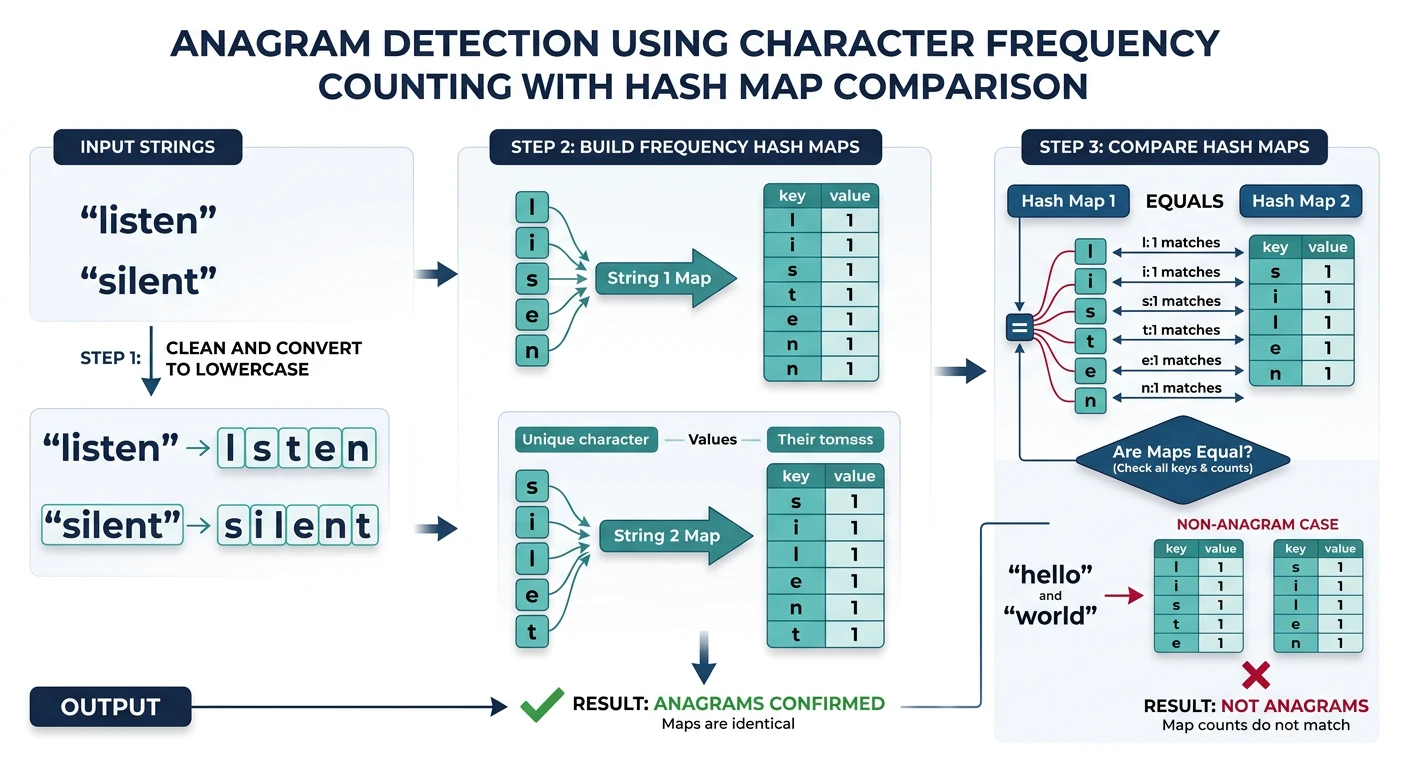
Group Anagrams
LeetCode Practice Problems
Master these string problems for FAANG interviews:
Easy 344. Reverse String
Reverse a string in-place using \(O(1)\) extra memory.
Easy 125. Valid Palindrome
Check if string is palindrome considering only alphanumeric characters.
Medium 5. Longest Palindromic Substring
Find the longest palindromic substring in s.
Medium 49. Group Anagrams
Group strings that are anagrams of each other.
Medium 3. Longest Substring Without Repeating
Find length of longest substring without repeating characters.
Hard 76. Minimum Window Substring
Find minimum window in s containing all characters of t.
Next in the Series
In Part 5: Matrices, we’ll extend arrays into two dimensions with matrices — covering sparse representations, special matrices, and the traversal patterns that appear in graph and DP problems.