Introduction
Cloud databases eliminate the operational overhead of managing database infrastructure while providing scalability, high availability, and automated backups. This guide covers both relational and NoSQL database services across AWS, Azure, and GCP.
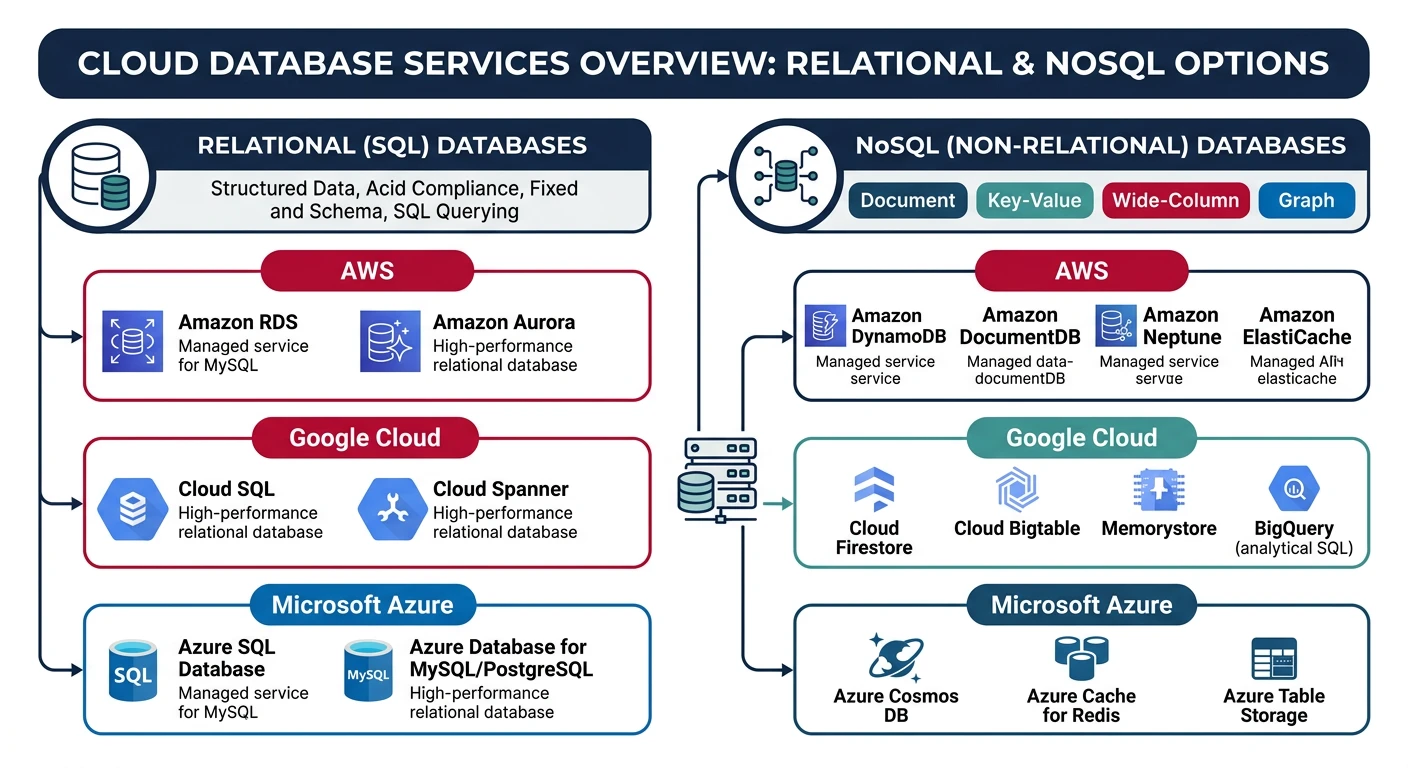
What We'll Cover:
- Relational databases - RDS, Azure SQL, Cloud SQL
- NoSQL databases - DynamoDB, Cosmos DB, Firestore
- Scaling strategies - Read replicas, sharding, partitioning
- Backup & recovery - Automated backups, point-in-time recovery
- Security - Encryption, access control, networking
Cloud Computing Mastery
Your 11-step learning path • Currently on Step 5
Cloud Computing Fundamentals
IaaS, PaaS, SaaS, deployment modelsCLI Tools & Setup
AWS CLI, Azure CLI, gcloud, TerraformCompute Services
VMs, containers, auto-scaling, spot instancesStorage Services
Object, block, file storage, data lifecycle5
Database Services
RDS, DynamoDB, Cosmos DB, caching6
Networking & CDN
VPCs, load balancers, DNS, content delivery7
Serverless Computing
Lambda, Functions, event-driven architecture8
Containers & Kubernetes
Docker, EKS, AKS, GKE, orchestration9
Identity & Security
IAM, RBAC, encryption, compliance10
Monitoring & Observability
CloudWatch, Azure Monitor, logging11
DevOps & CI/CD
Pipelines, infrastructure as code, GitOpsDatabase Types
Relational vs NoSQL
| Aspect | Relational (SQL) | NoSQL |
|---|---|---|
| Data Model | Tables with rows and columns | Document, Key-Value, Column, Graph |
| Schema | Fixed schema, strict structure | Flexible/dynamic schema |
| Scaling | Vertical (scale up) + Read replicas | Horizontal (scale out) |
| Transactions | ACID compliant | Eventual consistency (some offer ACID) |
| Query Language | SQL | Varies (API, custom query languages) |
| Best For | Complex queries, joins, transactions | High throughput, flexible data, scale |
NoSQL Categories
Document
JSON-like documents with nested data
MongoDB, Cosmos DB, FirestoreKey-Value
Simple key-value pairs, fast lookups
DynamoDB, Redis, MemcachedWide-Column
Column families, sparse data
Cassandra, HBase, BigtableGraph
Nodes and edges, relationships
Neo4j, Neptune, Cosmos DBProvider Comparison
Relational Database Services
| Feature | AWS RDS | Azure SQL Database | Google Cloud SQL |
|---|---|---|---|
| Engines | MySQL, PostgreSQL, MariaDB, Oracle, SQL Server, Aurora | SQL Server (Azure SQL), MySQL, PostgreSQL | MySQL, PostgreSQL, SQL Server |
| Serverless | Aurora Serverless v2 | Azure SQL Serverless | Cloud SQL (always-on) |
| Max Storage | 64 TB (Aurora), 16 TB (others) | 100 TB (Hyperscale) | 64 TB |
| Read Replicas | Up to 15 (Aurora), 5 (others) | Yes (geo-replication) | Up to 10 |
| Multi-Region | Aurora Global Database | Active geo-replication | Cross-region replicas |
NoSQL Database Services
| Feature | AWS DynamoDB | Azure Cosmos DB | Google Firestore |
|---|---|---|---|
| Type | Key-Value / Document | Multi-model (Document, Graph, Key-Value, Column) | Document |
| Query | PartiQL, API | SQL API, MongoDB API, Cassandra API, Gremlin | Query API, Realtime listeners |
| Pricing Model | On-demand or provisioned capacity | RU/s (Request Units) | Document reads/writes/deletes |
| Global Distribution | Global Tables | Multi-region writes (turnkey) | Multi-region (single region write) |
| Consistency | Eventually/Strongly consistent | 5 consistency levels | Strong consistency |
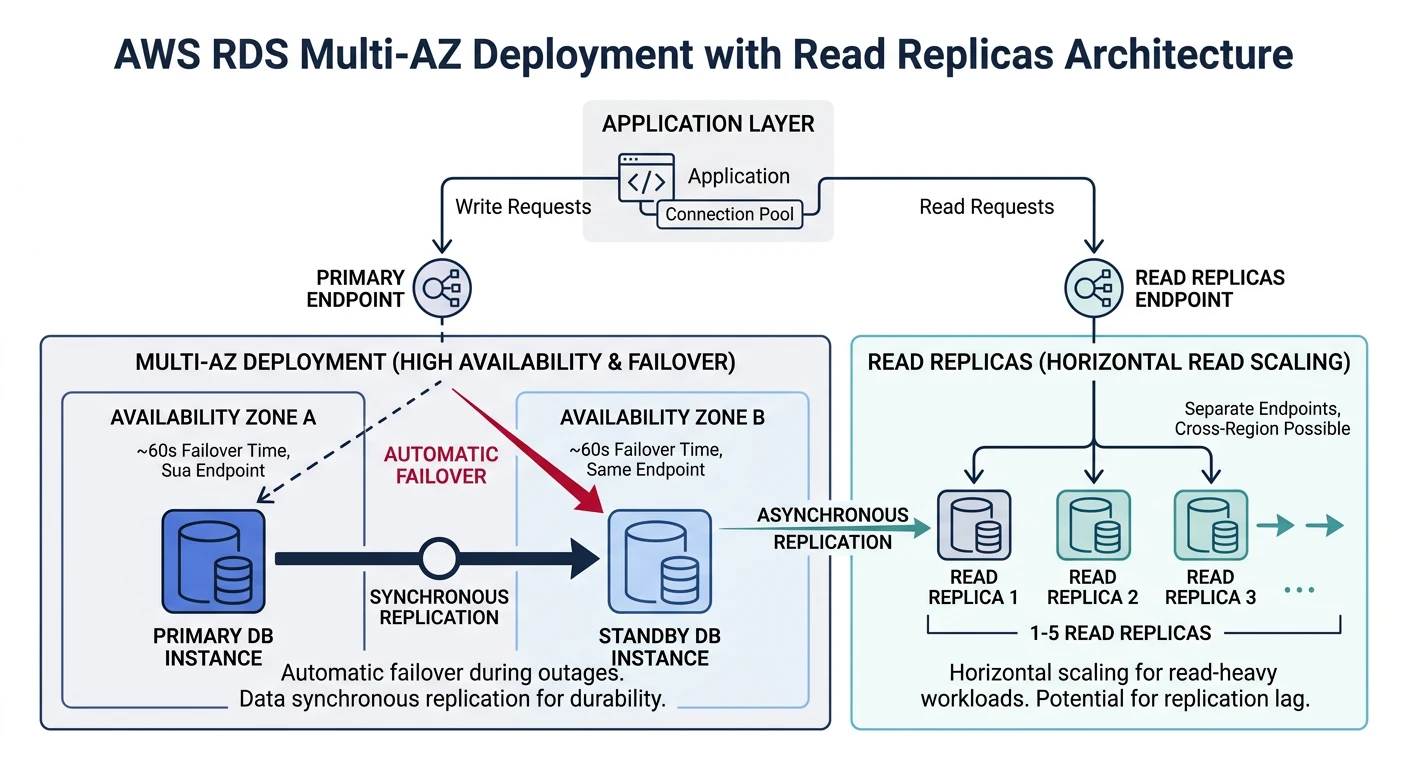
AWS RDS
Amazon Relational Database Service
- Multi-AZ deployments - Automatic failover for high availability
- Read replicas - Scale read traffic, cross-region
- Automated backups - Point-in-time recovery up to 35 days
- Aurora - AWS-optimized MySQL/PostgreSQL (5x faster)
Creating RDS Instance
# Create PostgreSQL RDS instance
aws rds create-db-instance \
--db-instance-identifier mydb \
--db-instance-class db.t3.medium \
--engine postgres \
--engine-version 15.4 \
--master-username admin \
--master-user-password MySecurePassword123! \
--allocated-storage 100 \
--storage-type gp3 \
--storage-encrypted \
--vpc-security-group-ids sg-12345678 \
--db-subnet-group-name my-subnet-group \
--backup-retention-period 7 \
--multi-az \
--publicly-accessible false
# Create MySQL RDS instance
aws rds create-db-instance \
--db-instance-identifier mysql-db \
--db-instance-class db.r6g.large \
--engine mysql \
--engine-version 8.0 \
--master-username admin \
--master-user-password MySecurePassword123! \
--allocated-storage 200 \
--storage-type gp3 \
--iops 3000
# Wait for instance to be available
aws rds wait db-instance-available --db-instance-identifier mydb
# Describe instance
aws rds describe-db-instances --db-instance-identifier mydb
RDS Read Replicas
# Create read replica (same region)
aws rds create-db-instance-read-replica \
--db-instance-identifier mydb-replica \
--source-db-instance-identifier mydb \
--db-instance-class db.t3.medium
# Create cross-region read replica
aws rds create-db-instance-read-replica \
--db-instance-identifier mydb-replica-eu \
--source-db-instance-identifier arn:aws:rds:us-east-1:123456789012:db:mydb \
--db-instance-class db.t3.medium \
--region eu-west-1
# Promote replica to standalone (for migration/disaster recovery)
aws rds promote-read-replica --db-instance-identifier mydb-replica
# List read replicas
aws rds describe-db-instances \
--query "DBInstances[?ReadReplicaSourceDBInstanceIdentifier!=null]"
Aurora Cluster
# Create Aurora PostgreSQL cluster
aws rds create-db-cluster \
--db-cluster-identifier aurora-cluster \
--engine aurora-postgresql \
--engine-version 15.4 \
--master-username admin \
--master-user-password MySecurePassword123! \
--db-subnet-group-name my-subnet-group \
--vpc-security-group-ids sg-12345678 \
--storage-encrypted \
--backup-retention-period 14
# Add writer instance
aws rds create-db-instance \
--db-instance-identifier aurora-instance-1 \
--db-cluster-identifier aurora-cluster \
--db-instance-class db.r6g.large \
--engine aurora-postgresql
# Add reader instance
aws rds create-db-instance \
--db-instance-identifier aurora-reader-1 \
--db-cluster-identifier aurora-cluster \
--db-instance-class db.r6g.large \
--engine aurora-postgresql
# Aurora Serverless v2
aws rds create-db-cluster \
--db-cluster-identifier aurora-serverless \
--engine aurora-postgresql \
--engine-version 15.4 \
--master-username admin \
--master-user-password MySecurePassword123! \
--serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16
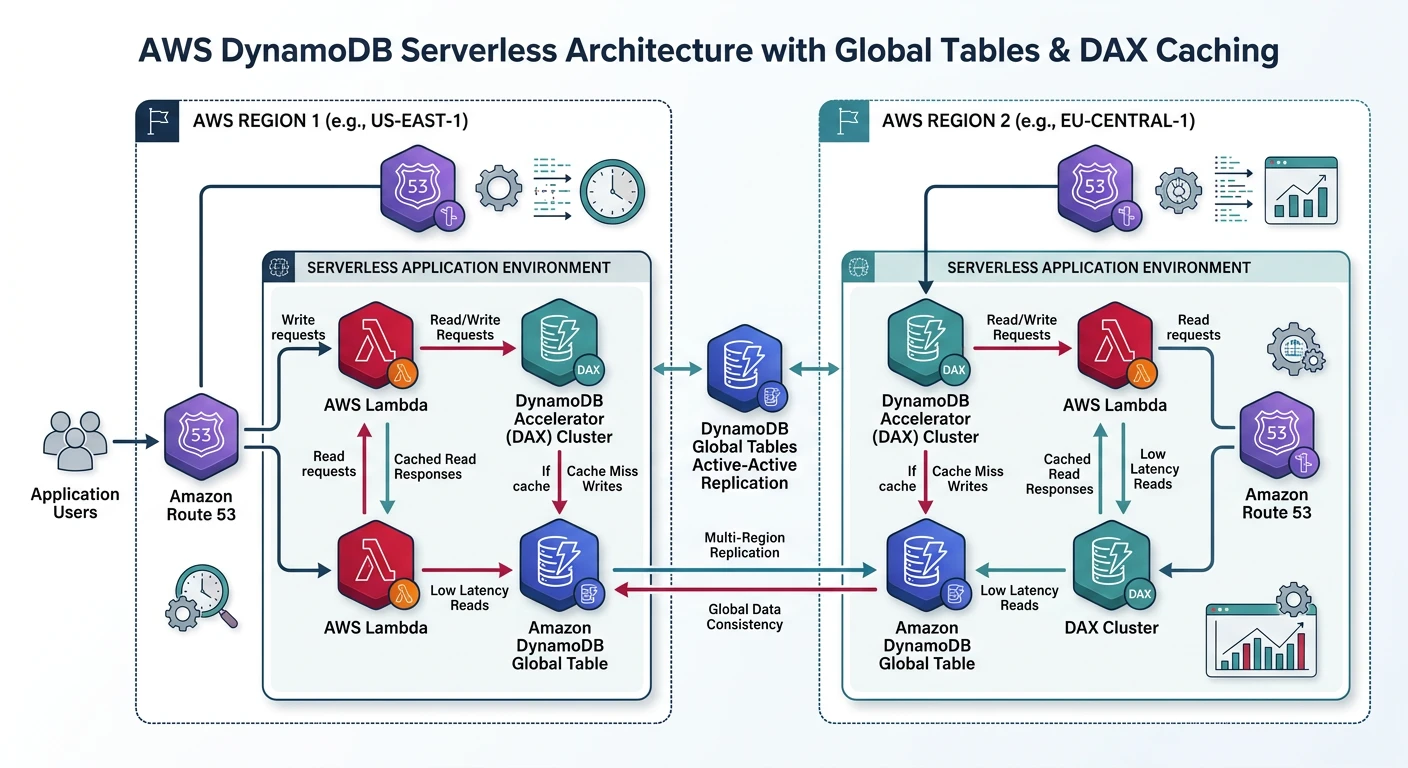
AWS DynamoDB
Amazon DynamoDB
- Serverless - No servers to manage, auto-scaling
- Single-digit millisecond - Consistent performance at any scale
- Global Tables - Multi-region, multi-active replication
- DAX - In-memory cache for microsecond latency
Creating DynamoDB Tables
# Create table with on-demand capacity
aws dynamodb create-table \
--table-name Users \
--attribute-definitions \
AttributeName=userId,AttributeType=S \
AttributeName=email,AttributeType=S \
--key-schema \
AttributeName=userId,KeyType=HASH \
--global-secondary-indexes \
"[{\"IndexName\": \"email-index\",
\"KeySchema\": [{\"AttributeName\":\"email\",\"KeyType\":\"HASH\"}],
\"Projection\": {\"ProjectionType\":\"ALL\"}}]" \
--billing-mode PAY_PER_REQUEST
# Create table with provisioned capacity
aws dynamodb create-table \
--table-name Orders \
--attribute-definitions \
AttributeName=orderId,AttributeType=S \
AttributeName=customerId,AttributeType=S \
AttributeName=orderDate,AttributeType=S \
--key-schema \
AttributeName=orderId,KeyType=HASH \
--global-secondary-indexes \
"[{\"IndexName\": \"customer-date-index\",
\"KeySchema\": [
{\"AttributeName\":\"customerId\",\"KeyType\":\"HASH\"},
{\"AttributeName\":\"orderDate\",\"KeyType\":\"RANGE\"}
],
\"Projection\": {\"ProjectionType\":\"ALL\"},
\"ProvisionedThroughput\": {\"ReadCapacityUnits\":10,\"WriteCapacityUnits\":5}}]" \
--provisioned-throughput ReadCapacityUnits=10,WriteCapacityUnits=5
# Describe table
aws dynamodb describe-table --table-name Users
DynamoDB CRUD Operations
# Put item
aws dynamodb put-item \
--table-name Users \
--item '{
"userId": {"S": "user-001"},
"email": {"S": "john@example.com"},
"name": {"S": "John Doe"},
"age": {"N": "30"},
"active": {"BOOL": true}
}'
# Get item
aws dynamodb get-item \
--table-name Users \
--key '{"userId": {"S": "user-001"}}'
# Update item
aws dynamodb update-item \
--table-name Users \
--key '{"userId": {"S": "user-001"}}' \
--update-expression "SET age = :newage, #n = :newname" \
--expression-attribute-names '{"#n": "name"}' \
--expression-attribute-values '{":newage": {"N": "31"}, ":newname": {"S": "John Smith"}}'
# Query with GSI
aws dynamodb query \
--table-name Users \
--index-name email-index \
--key-condition-expression "email = :email" \
--expression-attribute-values '{":email": {"S": "john@example.com"}}'
# Scan with filter
aws dynamodb scan \
--table-name Users \
--filter-expression "age > :minage" \
--expression-attribute-values '{":minage": {"N": "25"}}'
# Delete item
aws dynamodb delete-item \
--table-name Users \
--key '{"userId": {"S": "user-001"}}'
DynamoDB Global Tables
# Create global table (table must exist in primary region)
aws dynamodb update-table \
--table-name Users \
--replica-updates \
"[{\"Create\": {\"RegionName\": \"eu-west-1\"}},
{\"Create\": {\"RegionName\": \"ap-southeast-1\"}}]"
# Check replication status
aws dynamodb describe-table --table-name Users \
--query "Table.Replicas"
# Remove replica
aws dynamodb update-table \
--table-name Users \
--replica-updates \
"[{\"Delete\": {\"RegionName\": \"ap-southeast-1\"}}]"
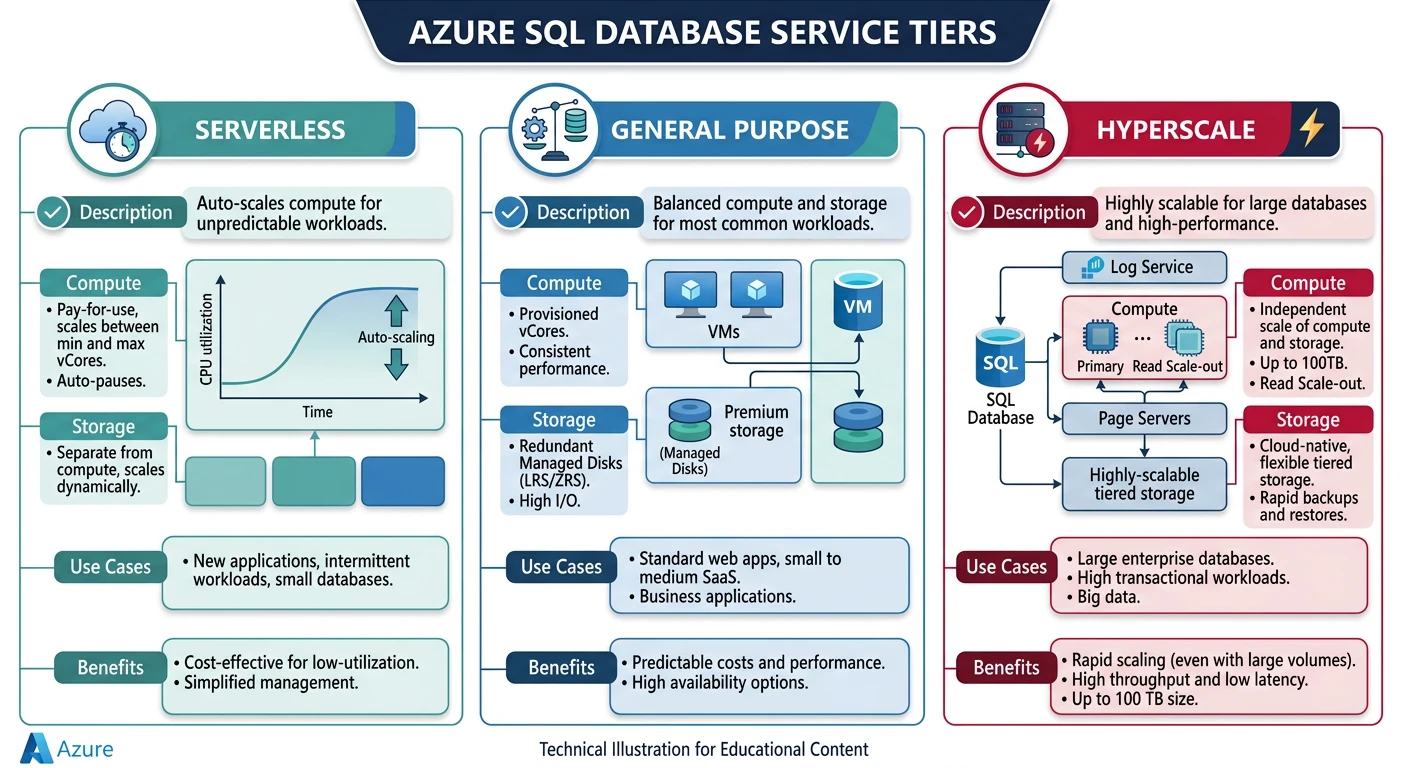
Azure SQL Database
Azure SQL Database
- Intelligent features - Auto-tuning, threat detection
- Hyperscale - Up to 100 TB, rapid scale-out
- Serverless - Auto-pause, pay for compute used
- Elastic pools - Share resources across databases
Creating Azure SQL Database
# Create resource group
az group create --name myResourceGroup --location eastus
# Create SQL Server
az sql server create \
--name mysqlserver \
--resource-group myResourceGroup \
--location eastus \
--admin-user sqladmin \
--admin-password MySecurePassword123!
# Create database (General Purpose)
az sql db create \
--resource-group myResourceGroup \
--server mysqlserver \
--name mydb \
--edition GeneralPurpose \
--compute-model Provisioned \
--family Gen5 \
--capacity 2 \
--max-size 32GB \
--zone-redundant false
# Create serverless database
az sql db create \
--resource-group myResourceGroup \
--server mysqlserver \
--name serverlessdb \
--edition GeneralPurpose \
--compute-model Serverless \
--family Gen5 \
--min-capacity 0.5 \
--max-capacity 4 \
--auto-pause-delay 60
# Create Hyperscale database
az sql db create \
--resource-group myResourceGroup \
--server mysqlserver \
--name hyperscaledb \
--edition Hyperscale \
--compute-model Provisioned \
--family Gen5 \
--capacity 2 \
--read-replicas 2
Azure SQL Firewall & Security
# Add firewall rule (allow specific IP)
az sql server firewall-rule create \
--resource-group myResourceGroup \
--server mysqlserver \
--name AllowMyIP \
--start-ip-address 203.0.113.1 \
--end-ip-address 203.0.113.1
# Allow Azure services
az sql server firewall-rule create \
--resource-group myResourceGroup \
--server mysqlserver \
--name AllowAzureServices \
--start-ip-address 0.0.0.0 \
--end-ip-address 0.0.0.0
# Enable Azure AD authentication
az sql server ad-admin create \
--resource-group myResourceGroup \
--server mysqlserver \
--display-name "DBA Group" \
--object-id 00000000-0000-0000-0000-000000000000
# Enable auditing
az sql server audit-policy update \
--resource-group myResourceGroup \
--name mysqlserver \
--state Enabled \
--storage-account mystorageaccount
# Enable transparent data encryption (enabled by default)
az sql db tde set \
--resource-group myResourceGroup \
--server mysqlserver \
--database mydb \
--status Enabled
Azure SQL Elastic Pools
# Create elastic pool
az sql elastic-pool create \
--resource-group myResourceGroup \
--server mysqlserver \
--name mypool \
--edition GeneralPurpose \
--family Gen5 \
--capacity 4 \
--db-max-capacity 2 \
--db-min-capacity 0 \
--max-size 100GB
# Add database to pool
az sql db update \
--resource-group myResourceGroup \
--server mysqlserver \
--name mydb \
--elastic-pool mypool
# Create database directly in pool
az sql db create \
--resource-group myResourceGroup \
--server mysqlserver \
--name pooldb \
--elastic-pool mypool
# List databases in pool
az sql elastic-pool list-dbs \
--resource-group myResourceGroup \
--server mysqlserver \
--name mypool
Azure Cosmos DB
Azure Cosmos DB
- Multi-model - Document, Key-Value, Graph, Column-family
- Global distribution - Turnkey multi-region replication
- 5 consistency levels - Strong to eventual
- Multiple APIs - SQL, MongoDB, Cassandra, Gremlin, Table
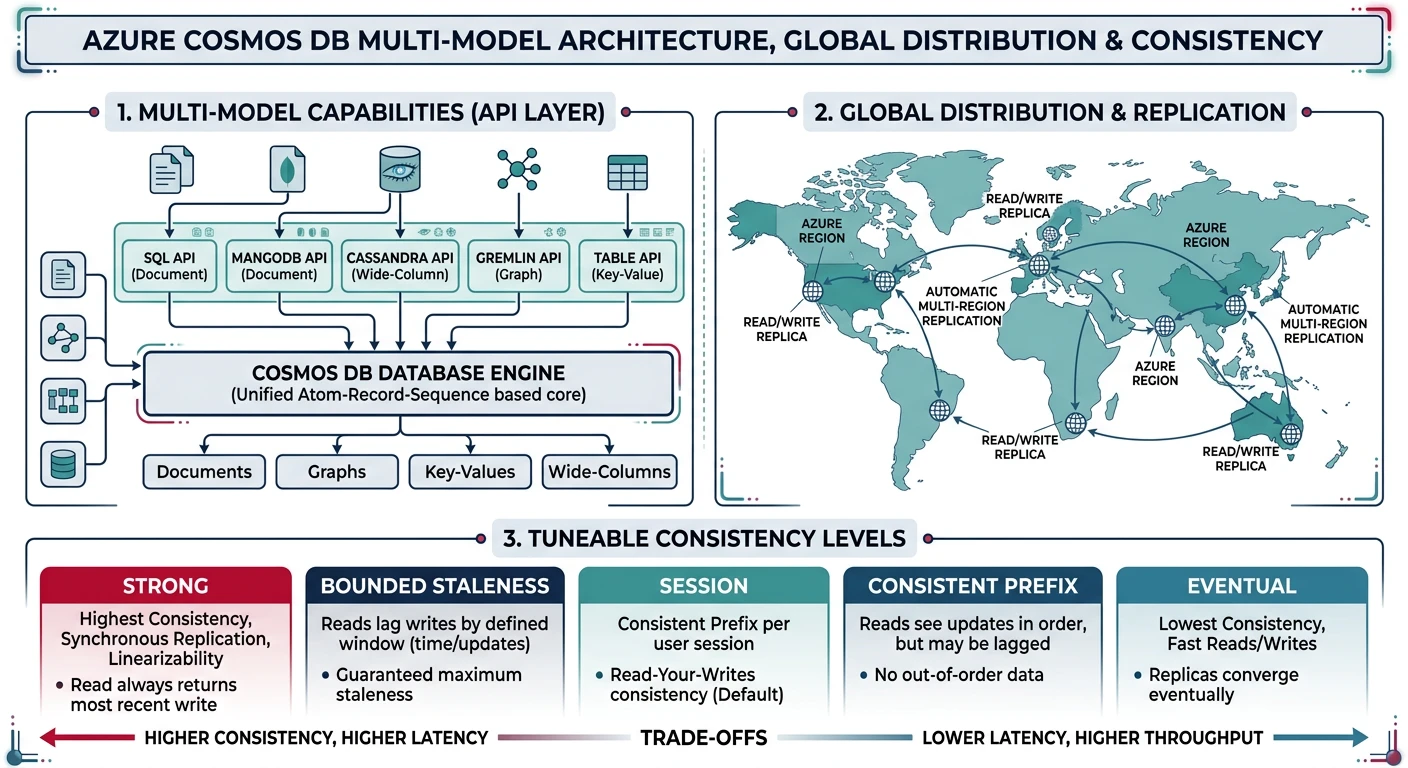
Creating Cosmos DB Account
# Create Cosmos DB account (SQL API)
az cosmosdb create \
--name mycosmosaccount \
--resource-group myResourceGroup \
--kind GlobalDocumentDB \
--default-consistency-level Session \
--locations regionName=eastus failoverPriority=0 isZoneRedundant=true \
--locations regionName=westus failoverPriority=1 isZoneRedundant=false \
--enable-automatic-failover true
# Create with MongoDB API
az cosmosdb create \
--name mymongocosmosaccount \
--resource-group myResourceGroup \
--kind MongoDB \
--server-version 4.2 \
--default-consistency-level Session \
--locations regionName=eastus failoverPriority=0
# Create database
az cosmosdb sql database create \
--account-name mycosmosaccount \
--resource-group myResourceGroup \
--name mydb
# Create container with partition key
az cosmosdb sql container create \
--account-name mycosmosaccount \
--resource-group myResourceGroup \
--database-name mydb \
--name users \
--partition-key-path "/userId" \
--throughput 400
# Create with autoscale
az cosmosdb sql container create \
--account-name mycosmosaccount \
--resource-group myResourceGroup \
--database-name mydb \
--name orders \
--partition-key-path "/customerId" \
--max-throughput 4000
Cosmos DB Operations
# Get connection string
az cosmosdb keys list \
--name mycosmosaccount \
--resource-group myResourceGroup \
--type connection-strings
# Get primary key
az cosmosdb keys list \
--name mycosmosaccount \
--resource-group myResourceGroup
# Update throughput
az cosmosdb sql container throughput update \
--account-name mycosmosaccount \
--resource-group myResourceGroup \
--database-name mydb \
--name users \
--throughput 800
# Migrate to autoscale
az cosmosdb sql container throughput migrate \
--account-name mycosmosaccount \
--resource-group myResourceGroup \
--database-name mydb \
--name users \
--throughput-type autoscale
# Add region
az cosmosdb update \
--name mycosmosaccount \
--resource-group myResourceGroup \
--locations regionName=eastus failoverPriority=0 \
--locations regionName=westus failoverPriority=1 \
--locations regionName=northeurope failoverPriority=2
Cosmos DB with Python SDK
# pip install azure-cosmos
from azure.cosmos import CosmosClient, PartitionKey
import os
# Connection
endpoint = os.environ["COSMOS_ENDPOINT"]
key = os.environ["COSMOS_KEY"]
client = CosmosClient(endpoint, key)
# Create database
database = client.create_database_if_not_exists(id="mydb")
# Create container
container = database.create_container_if_not_exists(
id="users",
partition_key=PartitionKey(path="/userId"),
offer_throughput=400
)
# Create item
user = {
"id": "user-001",
"userId": "user-001",
"name": "John Doe",
"email": "john@example.com"
}
container.create_item(body=user)
# Read item
item = container.read_item(item="user-001", partition_key="user-001")
print(item)
# Query items
query = "SELECT * FROM users u WHERE u.name = @name"
items = container.query_items(
query=query,
parameters=[{"name": "@name", "value": "John Doe"}],
enable_cross_partition_query=True
)
for item in items:
print(item)
# Update item
item["email"] = "john.doe@example.com"
container.upsert_item(body=item)
# Delete item
container.delete_item(item="user-001", partition_key="user-001")
Google Cloud SQL
Google Cloud SQL
- Fully managed - MySQL, PostgreSQL, SQL Server
- High availability - Regional instances with automatic failover
- Automated backups - Point-in-time recovery
- Cloud SQL Proxy - Secure connections without IP allowlisting
Creating Cloud SQL Instance
# Create PostgreSQL instance
gcloud sql instances create mydb \
--database-version=POSTGRES_15 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--root-password=MySecurePassword123! \
--storage-size=100GB \
--storage-type=SSD \
--storage-auto-increase \
--availability-type=REGIONAL \
--backup-start-time=02:00 \
--enable-point-in-time-recovery
# Create MySQL instance
gcloud sql instances create mysql-db \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=us-central1 \
--root-password=MySecurePassword123! \
--storage-size=50GB \
--storage-auto-increase
# Create database
gcloud sql databases create myapp --instance=mydb
# Create user
gcloud sql users create appuser \
--instance=mydb \
--password=AppUserPassword123!
# Describe instance
gcloud sql instances describe mydb
Cloud SQL Networking
# Authorize network (IP allowlisting)
gcloud sql instances patch mydb \
--authorized-networks=203.0.113.0/24
# Add multiple networks
gcloud sql instances patch mydb \
--authorized-networks="203.0.113.0/24,198.51.100.0/24"
# Enable private IP (requires VPC)
gcloud sql instances patch mydb \
--network=projects/my-project/global/networks/my-vpc \
--no-assign-ip
# Get connection name for Cloud SQL Proxy
gcloud sql instances describe mydb --format="value(connectionName)"
# Connect using Cloud SQL Proxy
./cloud-sql-proxy my-project:us-central1:mydb
# Connect via psql (after proxy is running)
psql "host=127.0.0.1 port=5432 user=postgres dbname=myapp"
Cloud SQL Read Replicas
# Create read replica (same region)
gcloud sql instances create mydb-replica \
--master-instance-name=mydb \
--region=us-central1
# Create cross-region replica
gcloud sql instances create mydb-replica-eu \
--master-instance-name=mydb \
--region=europe-west1
# Promote replica to standalone
gcloud sql instances promote-replica mydb-replica
# List replicas
gcloud sql instances list --filter="replicaConfiguration.mysqlReplicaConfiguration.masterInstanceName:mydb"
Google Firestore
Google Cloud Firestore
- Serverless document database - Auto-scaling, no provisioning
- Real-time listeners - Live synchronization for apps
- Offline support - Built-in for mobile/web SDKs
- Strong consistency - ACID transactions
Firestore CLI Operations
# Create Firestore database (Native mode)
gcloud firestore databases create \
--location=us-central \
--type=firestore-native
# Export data
gcloud firestore export gs://my-bucket/firestore-backup
# Import data
gcloud firestore import gs://my-bucket/firestore-backup
# List indexes
gcloud firestore indexes composite list
# Create composite index
gcloud firestore indexes composite create \
--collection-group=users \
--field-config field-path=age,order=ASCENDING \
--field-config field-path=createdAt,order=DESCENDING
Firestore with Python SDK
# pip install google-cloud-firestore
from google.cloud import firestore
from datetime import datetime
# Initialize client
db = firestore.Client()
# Add document with auto-generated ID
doc_ref = db.collection('users').document()
doc_ref.set({
'name': 'John Doe',
'email': 'john@example.com',
'age': 30,
'created_at': datetime.now()
})
print(f"Document ID: {doc_ref.id}")
# Add document with specific ID
db.collection('users').document('user-001').set({
'name': 'Jane Smith',
'email': 'jane@example.com',
'age': 25
})
# Get document
doc = db.collection('users').document('user-001').get()
if doc.exists:
print(doc.to_dict())
# Update document
db.collection('users').document('user-001').update({
'age': 26,
'updated_at': firestore.SERVER_TIMESTAMP
})
# Query documents
users_ref = db.collection('users')
query = users_ref.where('age', '>=', 25).order_by('age').limit(10)
docs = query.stream()
for doc in docs:
print(f'{doc.id} => {doc.to_dict()}')
# Delete document
db.collection('users').document('user-001').delete()
# Batch write
batch = db.batch()
for i in range(10):
ref = db.collection('items').document(f'item-{i}')
batch.set(ref, {'index': i, 'name': f'Item {i}'})
batch.commit()
# Transaction
@firestore.transactional
def update_count(transaction, doc_ref):
doc = doc_ref.get(transaction=transaction)
new_count = doc.get('count') + 1
transaction.update(doc_ref, {'count': new_count})
return new_count
counter_ref = db.collection('counters').document('visits')
transaction = db.transaction()
new_count = update_count(transaction, counter_ref)
Backups & Recovery
AWS RDS Backups
# Create manual snapshot
aws rds create-db-snapshot \
--db-instance-identifier mydb \
--db-snapshot-identifier mydb-snapshot-2026-01-25
# List snapshots
aws rds describe-db-snapshots --db-instance-identifier mydb
# Restore from snapshot
aws rds restore-db-instance-from-db-snapshot \
--db-instance-identifier mydb-restored \
--db-snapshot-identifier mydb-snapshot-2026-01-25 \
--db-instance-class db.t3.medium
# Point-in-time recovery
aws rds restore-db-instance-to-point-in-time \
--source-db-instance-identifier mydb \
--target-db-instance-identifier mydb-pitr \
--restore-time 2026-01-25T10:30:00Z
# Copy snapshot to another region
aws rds copy-db-snapshot \
--source-db-snapshot-identifier arn:aws:rds:us-east-1:123456789012:snapshot:mydb-snapshot \
--target-db-snapshot-identifier mydb-snapshot-copy \
--region eu-west-1
# Delete snapshot
aws rds delete-db-snapshot --db-snapshot-identifier mydb-snapshot-2026-01-25
Azure SQL Backups
# List available restore points
az sql db list-deleted \
--resource-group myResourceGroup \
--server mysqlserver
# Restore to point in time
az sql db restore \
--resource-group myResourceGroup \
--server mysqlserver \
--name mydb-restored \
--dest-name mydb-pitr \
--time 2026-01-25T10:30:00Z
# Long-term retention policy
az sql db ltr-policy set \
--resource-group myResourceGroup \
--server mysqlserver \
--name mydb \
--weekly-retention P4W \
--monthly-retention P12M \
--yearly-retention P5Y \
--week-of-year 1
# List long-term backups
az sql db ltr-backup list \
--resource-group myResourceGroup \
--server mysqlserver \
--database mydb
# Restore from long-term backup
az sql db ltr-backup restore \
--dest-database mydb-ltr-restored \
--dest-server mysqlserver \
--dest-resource-group myResourceGroup \
--backup-id "/subscriptions/.../backups/mydb;..."
Cloud SQL Backups
# Create on-demand backup
gcloud sql backups create \
--instance=mydb \
--description="Manual backup before upgrade"
# List backups
gcloud sql backups list --instance=mydb
# Restore from backup
gcloud sql backups restore BACKUP_ID \
--restore-instance=mydb \
--backup-instance=mydb
# Clone instance (creates new instance from backup)
gcloud sql instances clone mydb mydb-clone
# Point-in-time recovery
gcloud sql instances clone mydb mydb-pitr \
--point-in-time 2026-01-25T10:30:00Z
# Export to Cloud Storage
gcloud sql export sql mydb gs://my-bucket/export.sql \
--database=myapp
# Import from Cloud Storage
gcloud sql import sql mydb gs://my-bucket/export.sql \
--database=myapp
Best Practices
Security Best Practices:
- Encryption at rest - Enable for all databases
- Encryption in transit - Use TLS/SSL connections
- Network isolation - Use private subnets, VPC endpoints
- Least privilege - Grant minimum required permissions
- Audit logging - Enable and monitor access logs
- Secrets management - Use Key Vault, Secrets Manager
Performance Tips
- Right-size instances - Monitor and adjust based on usage
- Use connection pooling - Reduce connection overhead
- Index strategically - Based on query patterns
- Caching layer - Redis/ElastiCache for frequently accessed data
- Read replicas - Offload read traffic from primary
- Partition/shard - For large NoSQL tables
Cost Optimization
- Reserved instances - 1-3 year commitments for predictable workloads
- Serverless options - Aurora Serverless, Azure SQL Serverless for variable workloads
- Right storage class - Standard vs Provisioned IOPS based on needs
- Auto-pause - For dev/test databases
- Delete unused resources - Snapshots, replicas, test databases
Conclusion
Choosing the right database service depends on your data model, scaling requirements, and consistency needs:
| Use Case | AWS | Azure | GCP |
|---|---|---|---|
| Traditional SQL | RDS / Aurora | Azure SQL Database | Cloud SQL |
| High-throughput NoSQL | DynamoDB | Cosmos DB | Bigtable |
| Document Store | DocumentDB | Cosmos DB (SQL API) | Firestore |
| Real-time/Mobile | DynamoDB + AppSync | Cosmos DB | Firestore |
| Analytics | Redshift | Synapse Analytics | BigQuery |
Continue Learning: