Introduction
Observability is essential for understanding, debugging, and optimizing cloud applications. This guide covers the three pillars of observability—metrics, logs, and traces—across all major cloud providers, with practical CLI examples.
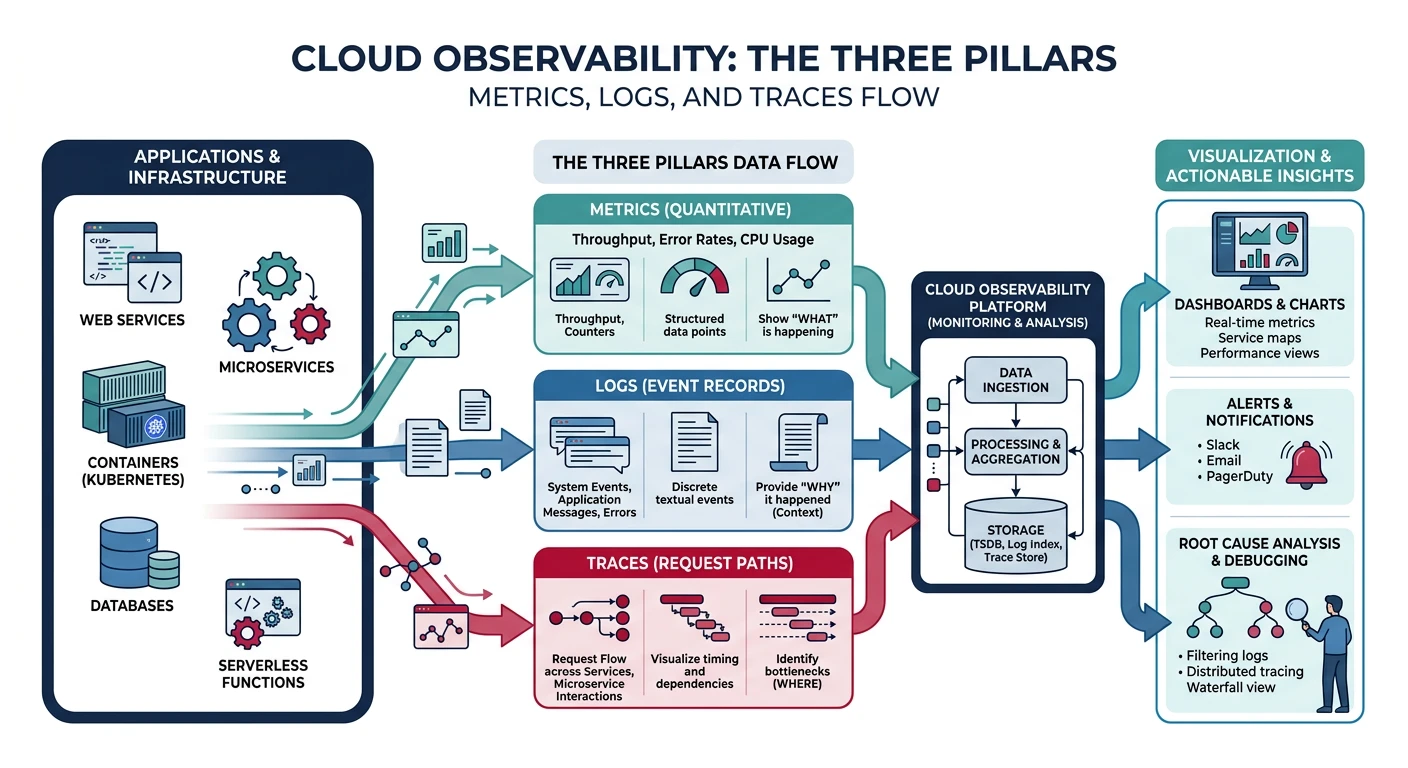
What We'll Cover:
- Metrics - Quantitative measurements over time
- Logs - Discrete events and messages
- Traces - Request flow across services
- Alerts - Proactive notification of issues
- Dashboards - Visual representation of system health
Cloud Computing Mastery
Your 11-step learning path • Currently on Step 10
Cloud Computing Fundamentals
IaaS, PaaS, SaaS, deployment modelsCLI Tools & Setup
AWS CLI, Azure CLI, gcloud, TerraformCompute Services
VMs, containers, auto-scaling, spot instancesStorage Services
Object, block, file storage, data lifecycleDatabase Services
RDS, DynamoDB, Cosmos DB, cachingNetworking & CDN
VPCs, load balancers, DNS, content deliveryServerless Computing
Lambda, Functions, event-driven architectureContainers & Kubernetes
Docker, EKS, AKS, GKE, orchestrationIdentity & Security
IAM, RBAC, encryption, compliance10
Monitoring & Observability
CloudWatch, Azure Monitor, logging11
DevOps & CI/CD
Pipelines, infrastructure as code, GitOpsObservability Pillars
Architecture Context: For observability patterns specific to microservices (log aggregation, health check APIs, exception tracking, audit logging, deployment annotations) and resilience patterns (circuit breaker, bulkhead, retry), see System Design Part 5: Microservices Architecture and Part 10: Monitoring & Observability.
The Three Pillars
| Pillar | Description | Use Cases |
|---|---|---|
| Metrics | Numeric measurements collected at regular intervals | CPU usage, memory, request count, latency percentiles |
| Logs | Timestamped records of discrete events | Error messages, audit trails, application events |
| Traces | End-to-end journey of a request through services | Debugging latency, finding bottlenecks, service dependencies |
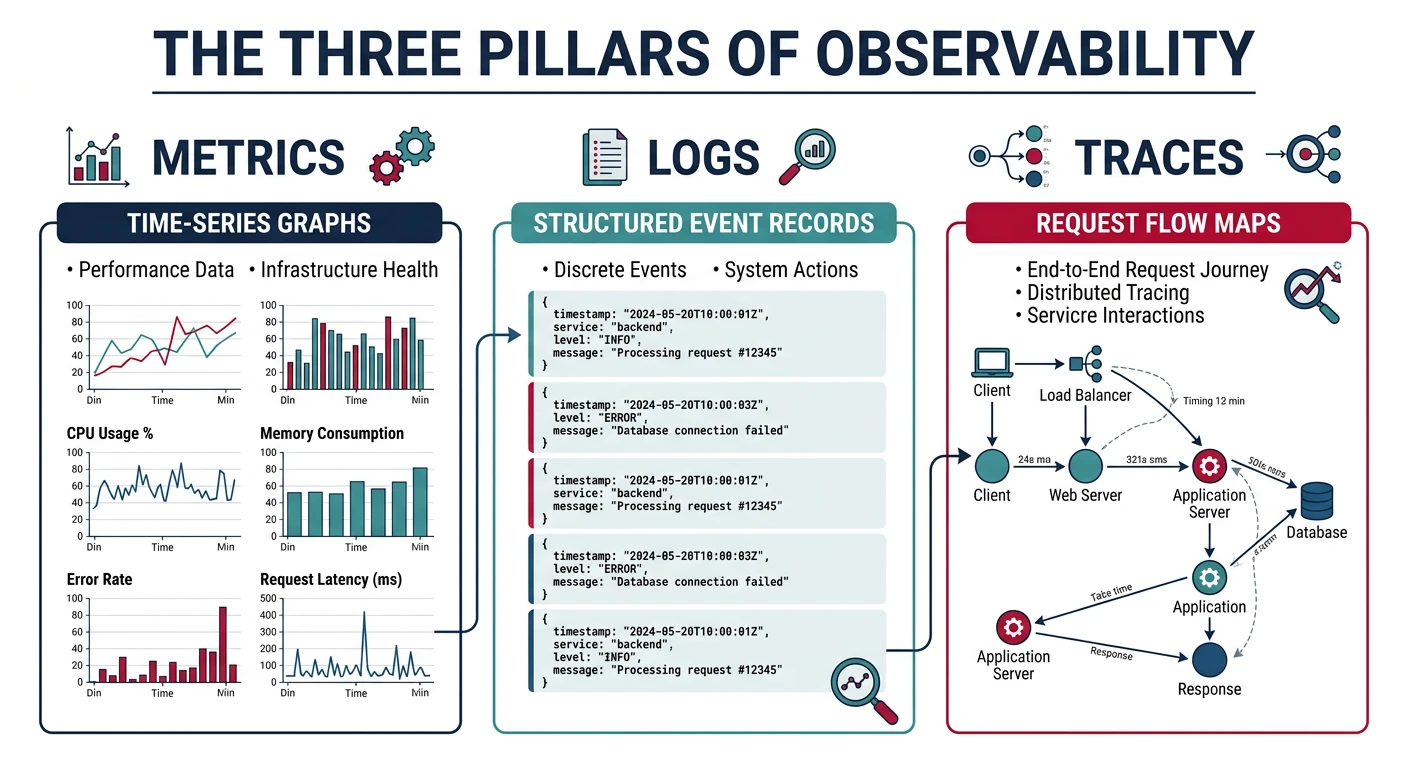
Key Metrics to Monitor
Golden Signals (Google SRE)
- Latency - Time to service a request (p50, p95, p99)
- Traffic - Demand on your system (requests/sec)
- Errors - Rate of failed requests (5xx, 4xx)
- Saturation - How "full" your service is (CPU, memory, queue depth)
Provider Comparison
| Feature | AWS | Azure | GCP |
|---|---|---|---|
| Primary Service | CloudWatch | Azure Monitor | Cloud Operations (Stackdriver) |
| Metrics | CloudWatch Metrics | Azure Metrics | Cloud Monitoring |
| Logs | CloudWatch Logs | Log Analytics | Cloud Logging |
| Tracing | X-Ray | Application Insights | Cloud Trace |
| Alerting | CloudWatch Alarms | Azure Alerts | Alerting Policies |
| Dashboards | CloudWatch Dashboards | Azure Dashboards / Workbooks | Cloud Monitoring Dashboards |
| APM | X-Ray + CloudWatch | Application Insights | Cloud Trace + Profiler |
| Query Language | CloudWatch Logs Insights | Kusto Query Language (KQL) | Logging Query Language |
AWS CloudWatch
Amazon CloudWatch
- Unified monitoring - Metrics, logs, alarms in one service
- Auto-collected metrics - EC2, Lambda, RDS, etc.
- Custom metrics - Publish your own application metrics
- Logs Insights - Query and analyze log data
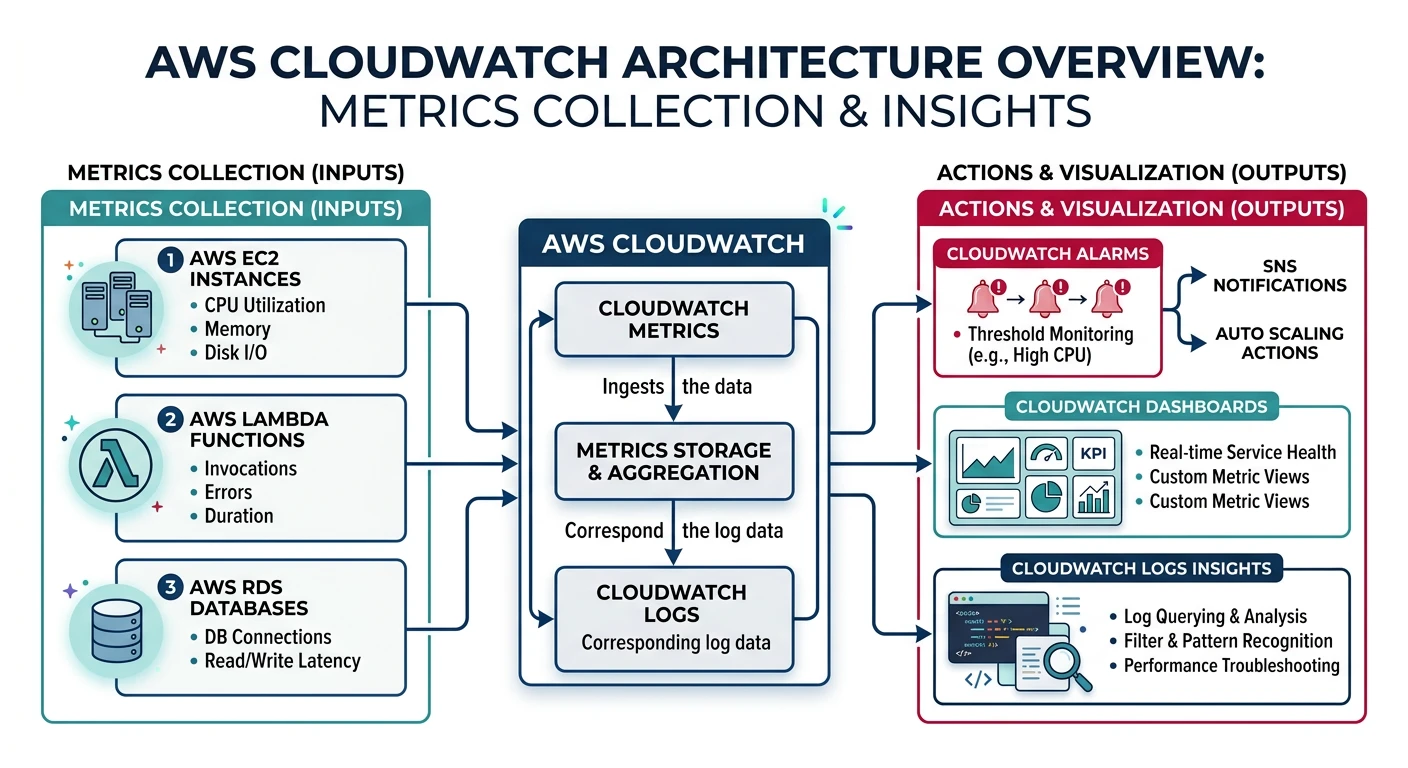
CloudWatch Metrics
# List available metrics for EC2
aws cloudwatch list-metrics --namespace AWS/EC2
# Get CPU utilization for an instance
aws cloudwatch get-metric-statistics \
--namespace AWS/EC2 \
--metric-name CPUUtilization \
--dimensions Name=InstanceId,Value=i-1234567890abcdef0 \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%SZ) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%SZ) \
--period 300 \
--statistics Average Maximum
# Publish custom metric
aws cloudwatch put-metric-data \
--namespace MyApplication \
--metric-name RequestCount \
--value 100 \
--unit Count \
--dimensions Environment=Production,Service=API
# Publish metric with timestamp
aws cloudwatch put-metric-data \
--namespace MyApplication \
--metric-data '[
{
"MetricName": "ProcessingTime",
"Value": 250,
"Unit": "Milliseconds",
"Timestamp": "'$(date -u +%Y-%m-%dT%H:%M:%SZ)'",
"Dimensions": [
{"Name": "Environment", "Value": "Production"},
{"Name": "Operation", "Value": "ProcessOrder"}
]
}
]'
# Get metric data with math expressions
aws cloudwatch get-metric-data \
--metric-data-queries '[
{
"Id": "cpu",
"MetricStat": {
"Metric": {
"Namespace": "AWS/EC2",
"MetricName": "CPUUtilization",
"Dimensions": [{"Name": "InstanceId", "Value": "i-1234567890abcdef0"}]
},
"Period": 300,
"Stat": "Average"
}
},
{
"Id": "high_cpu",
"Expression": "IF(cpu > 80, cpu, 0)",
"Label": "High CPU Periods"
}
]' \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%SZ) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%SZ)
CloudWatch Logs
# Create log group
aws logs create-log-group --log-group-name /myapp/production
# Create log stream
aws logs create-log-stream \
--log-group-name /myapp/production \
--log-stream-name api-server-1
# Put log events
aws logs put-log-events \
--log-group-name /myapp/production \
--log-stream-name api-server-1 \
--log-events '[
{"timestamp": '$(date +%s000)', "message": "Application started"},
{"timestamp": '$(date +%s000)', "message": "Connected to database"}
]'
# Set retention policy
aws logs put-retention-policy \
--log-group-name /myapp/production \
--retention-in-days 30
# Query logs with Logs Insights
aws logs start-query \
--log-group-name /myapp/production \
--start-time $(date -u -d '1 hour ago' +%s) \
--end-time $(date -u +%s) \
--query-string 'fields @timestamp, @message
| filter @message like /ERROR/
| sort @timestamp desc
| limit 100'
# Get query results
aws logs get-query-results --query-id "abc123-def456"
# Create metric filter from logs
aws logs put-metric-filter \
--log-group-name /myapp/production \
--filter-name ErrorCount \
--filter-pattern "ERROR" \
--metric-transformations '[
{
"metricName": "ApplicationErrors",
"metricNamespace": "MyApplication",
"metricValue": "1",
"defaultValue": 0
}
]'
# Subscribe to log group (send to Lambda)
aws logs put-subscription-filter \
--log-group-name /myapp/production \
--filter-name AllLogs \
--filter-pattern "" \
--destination-arn arn:aws:lambda:us-east-1:123456789012:function:ProcessLogs
CloudWatch Alarms
# Create alarm for high CPU
aws cloudwatch put-metric-alarm \
--alarm-name HighCPU \
--alarm-description "CPU utilization exceeds 80%" \
--metric-name CPUUtilization \
--namespace AWS/EC2 \
--dimensions Name=InstanceId,Value=i-1234567890abcdef0 \
--statistic Average \
--period 300 \
--threshold 80 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 2 \
--alarm-actions arn:aws:sns:us-east-1:123456789012:alerts
# Create alarm for error rate
aws cloudwatch put-metric-alarm \
--alarm-name HighErrorRate \
--alarm-description "Error rate exceeds 5%" \
--metrics '[
{
"Id": "errors",
"MetricStat": {
"Metric": {
"Namespace": "AWS/ApplicationELB",
"MetricName": "HTTPCode_Target_5XX_Count",
"Dimensions": [{"Name": "LoadBalancer", "Value": "app/my-alb/123456"}]
},
"Period": 60,
"Stat": "Sum"
}
},
{
"Id": "requests",
"MetricStat": {
"Metric": {
"Namespace": "AWS/ApplicationELB",
"MetricName": "RequestCount",
"Dimensions": [{"Name": "LoadBalancer", "Value": "app/my-alb/123456"}]
},
"Period": 60,
"Stat": "Sum"
}
},
{
"Id": "error_rate",
"Expression": "(errors/requests)*100",
"Label": "Error Rate"
}
]' \
--threshold 5 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 3 \
--alarm-actions arn:aws:sns:us-east-1:123456789012:alerts
# Create composite alarm
aws cloudwatch put-composite-alarm \
--alarm-name CriticalSystemAlarm \
--alarm-rule "ALARM(HighCPU) AND ALARM(HighMemory)" \
--alarm-actions arn:aws:sns:us-east-1:123456789012:critical-alerts
# List alarms
aws cloudwatch describe-alarms --state-value ALARM
# Disable alarm actions
aws cloudwatch disable-alarm-actions --alarm-names HighCPU
Azure Monitor
Azure Monitor
- Full-stack monitoring - Infrastructure to application
- Log Analytics - Powerful query language (KQL)
- Application Insights - APM and distributed tracing
- Workbooks - Interactive reports and visualizations
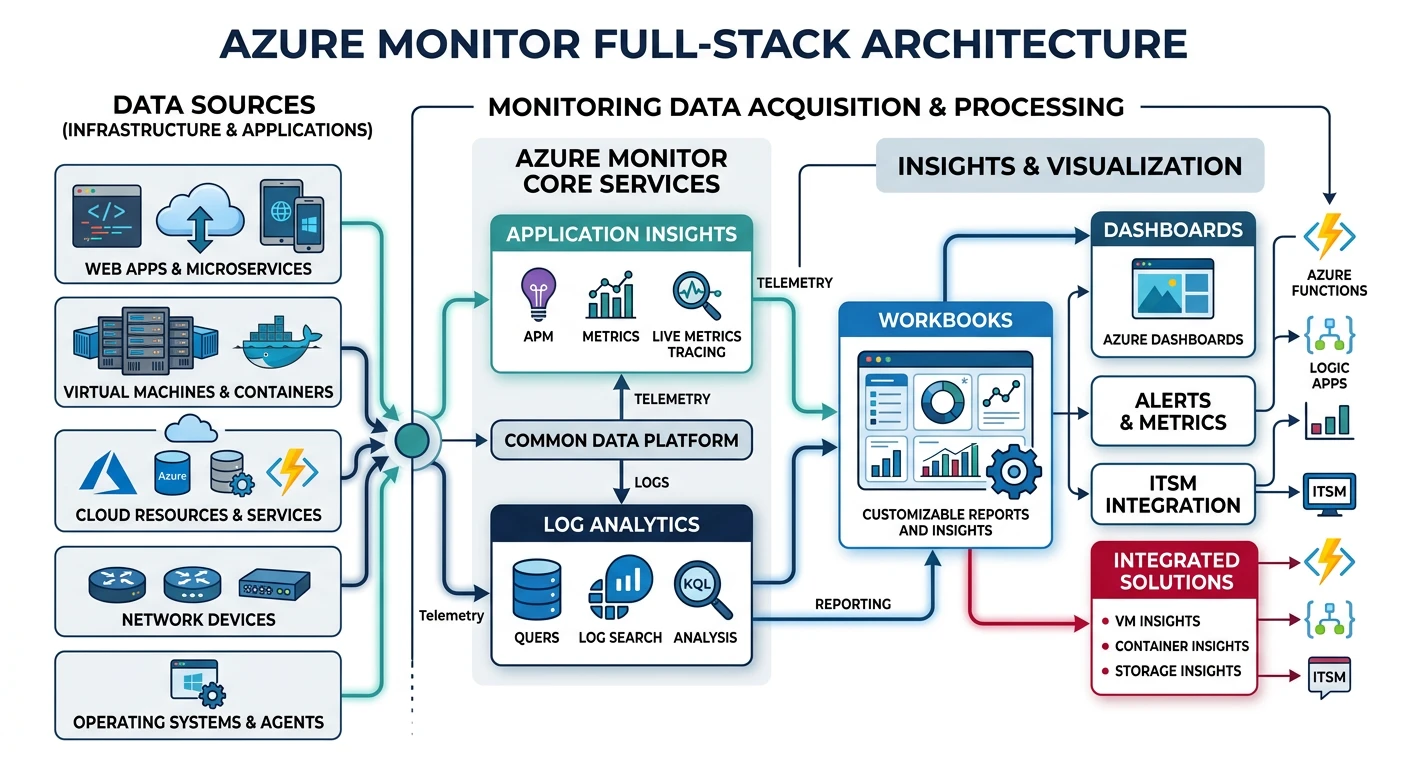
Azure Metrics
# List metric definitions for a VM
az monitor metrics list-definitions \
--resource /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM
# Get CPU metrics
az monitor metrics list \
--resource /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM \
--metric "Percentage CPU" \
--interval PT1M \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%SZ) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%SZ)
# Get multiple metrics
az monitor metrics list \
--resource /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM \
--metrics "Percentage CPU" "Available Memory Bytes" "Disk Read Bytes" \
--aggregation Average Maximum \
--interval PT5M
# Create Application Insights resource
az monitor app-insights component create \
--app myAppInsights \
--resource-group myRG \
--location eastus \
--application-type web
# Get instrumentation key
az monitor app-insights component show \
--app myAppInsights \
--resource-group myRG \
--query instrumentationKey
Log Analytics
# Create Log Analytics workspace
az monitor log-analytics workspace create \
--resource-group myRG \
--workspace-name myWorkspace \
--location eastus \
--sku PerGB2018
# Get workspace ID
az monitor log-analytics workspace show \
--resource-group myRG \
--workspace-name myWorkspace \
--query customerId -o tsv
# Query logs with KQL
az monitor log-analytics query \
--workspace $(az monitor log-analytics workspace show -g myRG -n myWorkspace --query customerId -o tsv) \
--analytics-query "
AzureActivity
| where TimeGenerated > ago(1h)
| where Level == 'Error'
| project TimeGenerated, OperationName, ResourceGroup, Caller
| order by TimeGenerated desc
| take 50
"
# Query Application Insights
az monitor app-insights query \
--app myAppInsights \
--resource-group myRG \
--analytics-query "
requests
| where timestamp > ago(1h)
| summarize count(), avg(duration) by bin(timestamp, 5m)
| order by timestamp desc
"
# Enable diagnostic settings (send to Log Analytics)
az monitor diagnostic-settings create \
--name myDiagSettings \
--resource /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.Web/sites/myWebApp \
--workspace $(az monitor log-analytics workspace show -g myRG -n myWorkspace --query id -o tsv) \
--logs '[
{"category": "AppServiceHTTPLogs", "enabled": true},
{"category": "AppServiceConsoleLogs", "enabled": true},
{"category": "AppServiceAppLogs", "enabled": true}
]' \
--metrics '[{"category": "AllMetrics", "enabled": true}]'
Azure Alerts
# Create action group
az monitor action-group create \
--resource-group myRG \
--name myActionGroup \
--short-name myAG \
--email-receiver name=admin email=admin@example.com \
--sms-receiver name=oncall country-code=1 phone-number=5551234567
# Create metric alert
az monitor metrics alert create \
--resource-group myRG \
--name HighCPUAlert \
--scopes /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.Compute/virtualMachines/myVM \
--condition "avg Percentage CPU > 80" \
--window-size 5m \
--evaluation-frequency 1m \
--severity 2 \
--action /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.Insights/actionGroups/myActionGroup
# Create log alert
az monitor scheduled-query create \
--resource-group myRG \
--name ErrorLogAlert \
--scopes /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.OperationalInsights/workspaces/myWorkspace \
--condition "count > 10" \
--condition-query "
AppServiceAppLogs
| where Level == 'Error'
| summarize count() by bin(TimeGenerated, 5m)
" \
--evaluation-frequency 5m \
--window-size 5m \
--severity 2 \
--action /subscriptions/xxx/resourceGroups/myRG/providers/Microsoft.Insights/actionGroups/myActionGroup
# List alerts
az monitor metrics alert list --resource-group myRG --output table
GCP Cloud Operations
Google Cloud Operations Suite
- Cloud Monitoring - Metrics and dashboards
- Cloud Logging - Centralized log management
- Cloud Trace - Distributed tracing
- Cloud Profiler - Continuous profiling
Cloud Monitoring
# List metric descriptors
gcloud monitoring metrics-descriptors list \
--filter="metric.type = starts_with('compute.googleapis.com')"
# Query time series data
gcloud monitoring time-series list \
--filter='metric.type="compute.googleapis.com/instance/cpu/utilization" AND resource.labels.instance_id="1234567890"' \
--interval-start-time=$(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%SZ) \
--interval-end-time=$(date -u +%Y-%m-%dT%H:%M:%SZ)
# Create custom metric descriptor
gcloud monitoring metric-descriptors create \
custom.googleapis.com/myapp/request_count \
--description="Number of requests" \
--metric-kind=CUMULATIVE \
--value-type=INT64 \
--labels=environment:STRING,service:STRING
# Write time series data (custom metric)
# Note: Typically done via API or client library
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
"https://monitoring.googleapis.com/v3/projects/my-project/timeSeries" \
-d '{
"timeSeries": [{
"metric": {
"type": "custom.googleapis.com/myapp/request_count",
"labels": {"environment": "production", "service": "api"}
},
"resource": {
"type": "global",
"labels": {"project_id": "my-project"}
},
"points": [{
"interval": {"endTime": "'$(date -u +%Y-%m-%dT%H:%M:%SZ)'"},
"value": {"int64Value": "100"}
}]
}]
}'
Cloud Logging
# List recent logs
gcloud logging read "resource.type=gce_instance" --limit=10
# Query logs with filter
gcloud logging read '
resource.type="gce_instance"
AND severity>=ERROR
AND timestamp>="2026-01-25T00:00:00Z"
' --limit=50 --format=json
# Query application logs
gcloud logging read '
resource.type="cloud_run_revision"
AND resource.labels.service_name="my-service"
AND textPayload=~"error|exception"
' --limit=100
# Write log entry
gcloud logging write my-log "Application started successfully" \
--severity=INFO \
--payload-type=text
# Write structured log
gcloud logging write my-log \
'{"message": "User login", "user_id": "12345", "action": "login"}' \
--severity=INFO \
--payload-type=json
# Create log sink (export to BigQuery)
gcloud logging sinks create my-bq-sink \
bigquery.googleapis.com/projects/my-project/datasets/logs_dataset \
--log-filter='resource.type="gce_instance"'
# Create log sink (export to Cloud Storage)
gcloud logging sinks create my-storage-sink \
storage.googleapis.com/my-logs-bucket \
--log-filter='severity>=WARNING'
# Create log-based metric
gcloud logging metrics create error_count \
--description="Count of error logs" \
--log-filter='severity>=ERROR'
# List log-based metrics
gcloud logging metrics list
GCP Alerting
# Create notification channel (email)
gcloud beta monitoring channels create \
--display-name="Admin Email" \
--type=email \
--channel-labels=email_address=admin@example.com
# List notification channels
gcloud beta monitoring channels list
# Create alerting policy
gcloud alpha monitoring policies create \
--display-name="High CPU Alert" \
--condition-display-name="CPU > 80%" \
--condition-filter='metric.type="compute.googleapis.com/instance/cpu/utilization" AND resource.type="gce_instance"' \
--condition-threshold-value=0.8 \
--condition-threshold-comparison=COMPARISON_GT \
--condition-threshold-duration=300s \
--notification-channels=projects/my-project/notificationChannels/123456 \
--combiner=OR
# Create alerting policy from YAML
cat > alert-policy.yaml << 'EOF'
displayName: "Error Rate Alert"
conditions:
- displayName: "Error rate > 5%"
conditionThreshold:
filter: 'metric.type="logging.googleapis.com/user/error_count" AND resource.type="global"'
comparison: COMPARISON_GT
thresholdValue: 5
duration: "300s"
aggregations:
- alignmentPeriod: "60s"
perSeriesAligner: ALIGN_RATE
combiner: OR
notificationChannels:
- projects/my-project/notificationChannels/123456
EOF
gcloud alpha monitoring policies create --policy-from-file=alert-policy.yaml
# List alerting policies
gcloud alpha monitoring policies list
Distributed Tracing
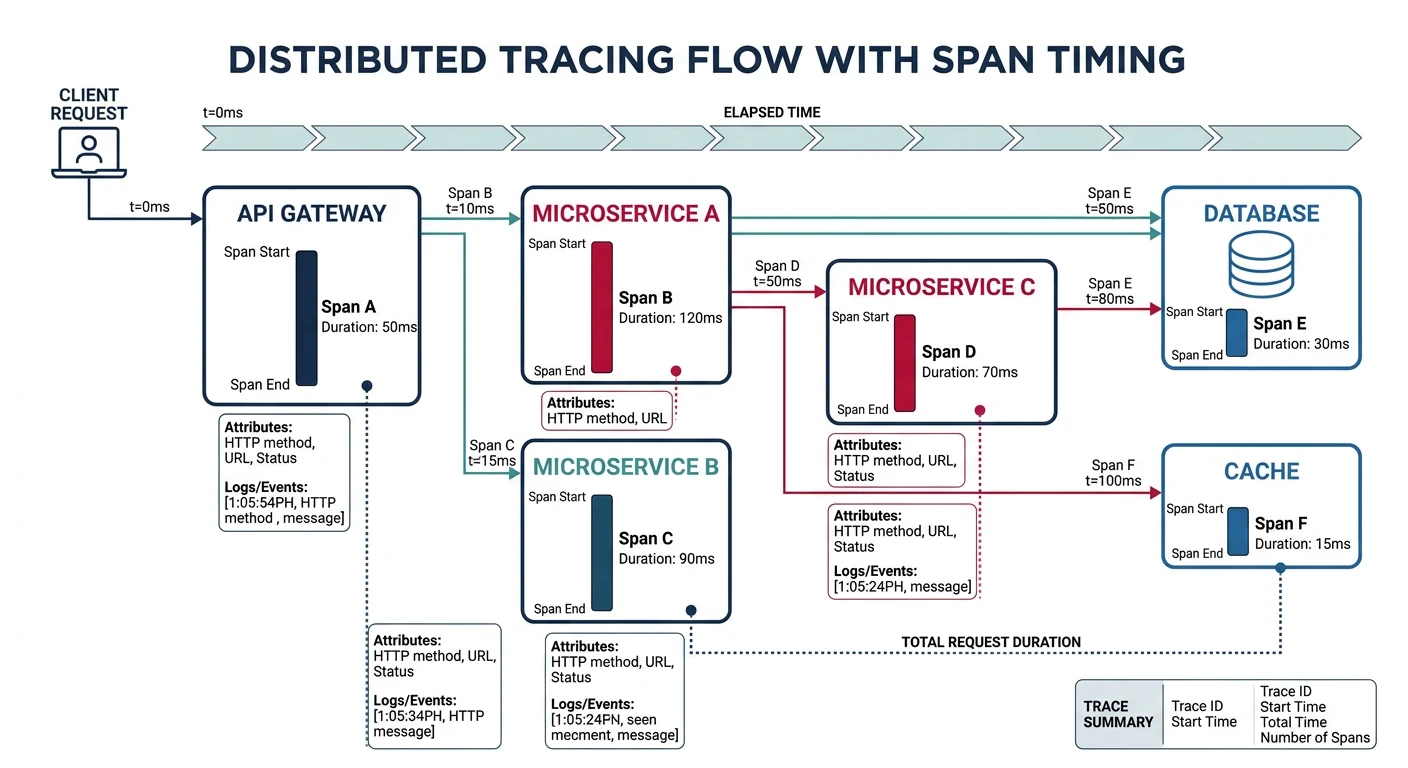
AWS X-Ray
# Get trace summaries
aws xray get-trace-summaries \
--start-time $(date -u -d '1 hour ago' +%s) \
--end-time $(date -u +%s) \
--filter-expression 'service(id(name: "my-service"))'
# Get specific trace
aws xray batch-get-traces \
--trace-ids "1-abc123-def456789"
# Get service graph
aws xray get-service-graph \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%SZ) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%SZ)
# Create sampling rule
aws xray create-sampling-rule --sampling-rule '{
"RuleName": "MyRule",
"Priority": 1000,
"FixedRate": 0.05,
"ReservoirSize": 5,
"ServiceName": "my-service",
"ServiceType": "*",
"Host": "*",
"HTTPMethod": "*",
"URLPath": "*",
"Version": 1
}'
# Get time series data
aws xray get-time-series-service-statistics \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%SZ) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%SZ) \
--entity-selector-expression 'service(id(name: "my-service"))'
Azure Application Insights
# Query traces
az monitor app-insights query \
--app myAppInsights \
--resource-group myRG \
--analytics-query "
traces
| where timestamp > ago(1h)
| where severityLevel >= 3
| project timestamp, message, operation_Id, customDimensions
| order by timestamp desc
| take 100
"
# Query dependencies (external calls)
az monitor app-insights query \
--app myAppInsights \
--resource-group myRG \
--analytics-query "
dependencies
| where timestamp > ago(1h)
| summarize count(), avg(duration), percentile(duration, 95) by target, type
| order by count_ desc
"
# Query end-to-end transaction
az monitor app-insights query \
--app myAppInsights \
--resource-group myRG \
--analytics-query "
union requests, dependencies, exceptions
| where operation_Id == 'abc123'
| order by timestamp asc
"
# Get availability results
az monitor app-insights query \
--app myAppInsights \
--resource-group myRG \
--analytics-query "
availabilityResults
| where timestamp > ago(24h)
| summarize successRate=avg(success)*100 by bin(timestamp, 1h), name
| render timechart
"
Google Cloud Trace
# List traces
gcloud trace traces list \
--filter='rootSpan.name:"/api"' \
--limit=50
# Get specific trace
gcloud trace traces describe TRACE_ID
# Query traces by latency
gcloud trace traces list \
--filter='latency>500ms' \
--limit=20
# Enable trace sampling
# (Typically configured in application code or via API)
# View trace analysis (via Console or API)
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
"https://cloudtrace.googleapis.com/v1/projects/my-project/traces?filter=latency>100ms"
Dashboards & Visualization
AWS CloudWatch Dashboards
# Create dashboard
aws cloudwatch put-dashboard \
--dashboard-name MyDashboard \
--dashboard-body '{
"widgets": [
{
"type": "metric",
"x": 0, "y": 0,
"width": 12, "height": 6,
"properties": {
"metrics": [
["AWS/EC2", "CPUUtilization", "InstanceId", "i-1234567890"]
],
"title": "EC2 CPU Utilization",
"period": 300,
"stat": "Average"
}
},
{
"type": "log",
"x": 12, "y": 0,
"width": 12, "height": 6,
"properties": {
"query": "SOURCE '\''/myapp/production'\'' | fields @timestamp, @message | filter @message like /ERROR/ | sort @timestamp desc | limit 20",
"title": "Recent Errors"
}
},
{
"type": "metric",
"x": 0, "y": 6,
"width": 24, "height": 6,
"properties": {
"metrics": [
["AWS/ApplicationELB", "RequestCount", "LoadBalancer", "app/my-alb/123"],
[".", "HTTPCode_Target_2XX_Count", ".", "."],
[".", "HTTPCode_Target_5XX_Count", ".", "."]
],
"title": "ALB Request Metrics",
"period": 60,
"stat": "Sum"
}
}
]
}'
# List dashboards
aws cloudwatch list-dashboards
# Get dashboard
aws cloudwatch get-dashboard --dashboard-name MyDashboard
# Delete dashboard
aws cloudwatch delete-dashboards --dashboard-names MyDashboard
Azure Workbooks
# Create workbook (via ARM template or Portal)
# Workbooks are typically created via Azure Portal due to complexity
# Query for dashboard visualization
az monitor app-insights query \
--app myAppInsights \
--resource-group myRG \
--analytics-query "
requests
| where timestamp > ago(24h)
| summarize
total=count(),
failed=countif(success == false),
p50=percentile(duration, 50),
p95=percentile(duration, 95),
p99=percentile(duration, 99)
by bin(timestamp, 1h)
| project timestamp, total, failed,
failure_rate=failed*100.0/total,
p50, p95, p99
"
# Export dashboard as ARM template
az portal dashboard export \
--resource-group myRG \
--name myDashboard
GCP Monitoring Dashboards
# Create dashboard
gcloud monitoring dashboards create --config-from-file=dashboard.json
# Example dashboard.json
cat > dashboard.json << 'EOF'
{
"displayName": "My Application Dashboard",
"gridLayout": {
"columns": "2",
"widgets": [
{
"title": "CPU Utilization",
"xyChart": {
"dataSets": [{
"timeSeriesQuery": {
"timeSeriesFilter": {
"filter": "metric.type=\"compute.googleapis.com/instance/cpu/utilization\"",
"aggregation": {
"alignmentPeriod": "60s",
"perSeriesAligner": "ALIGN_MEAN"
}
}
}
}]
}
},
{
"title": "Request Count",
"xyChart": {
"dataSets": [{
"timeSeriesQuery": {
"timeSeriesFilter": {
"filter": "metric.type=\"loadbalancing.googleapis.com/https/request_count\"",
"aggregation": {
"alignmentPeriod": "60s",
"perSeriesAligner": "ALIGN_RATE"
}
}
}
}]
}
}
]
}
}
EOF
# List dashboards
gcloud monitoring dashboards list
# Delete dashboard
gcloud monitoring dashboards delete DASHBOARD_ID
Alerting Strategies
Alerting Best Practices:
- Alert on symptoms, not causes - Focus on user impact
- Reduce noise - Every alert should be actionable
- Use multi-window alerts - Avoid false positives
- Set up escalation - Different severity levels
- Include runbooks - Link to remediation docs
Alert Severity Levels
| Level | Response Time | Example |
|---|---|---|
| P1 Critical | Immediate (page) | Service down, data loss |
| P2 High | Within 1 hour | Degraded performance, high error rate |
| P3 Medium | Within 4 hours | Elevated latency, approaching limits |
| P4 Low | Next business day | Non-critical warnings, cleanup needed |
Best Practices
Observability Checklist
- Standardize logging - Consistent format (JSON), include trace IDs
- Use structured logs - Key-value pairs for easy querying
- Correlate signals - Link metrics, logs, and traces
- Set baselines - Understand normal behavior first
- Automate responses - Auto-scaling, auto-remediation
- Retention policies - Balance cost vs. debugging needs
- Tag everything - Environment, service, version labels
- Test alerts - Regularly verify alerting works
Logging Format Example:
{
"timestamp": "2026-01-25T10:30:00.000Z",
"level": "ERROR",
"service": "order-service",
"version": "1.2.3",
"trace_id": "abc123def456",
"span_id": "789xyz",
"message": "Failed to process order",
"error": {
"type": "ValidationError",
"message": "Invalid payment method"
},
"context": {
"order_id": "ORD-12345",
"user_id": "USR-67890"
}
}
Conclusion
Effective observability requires combining metrics, logs, and traces. Key takeaways:
| Component | AWS | Azure | GCP |
|---|---|---|---|
| Start With | CloudWatch + X-Ray | Application Insights | Cloud Operations Suite |
| Query Language | Logs Insights | KQL (powerful) | Logging Query |
| Strength | Deep AWS integration | Full APM solution | Global/multi-cloud |
Continue Learning: