We use cookies to enhance your browsing experience, serve personalized content, and analyze our traffic.
By clicking "Accept All", you consent to our use of cookies. See our
Privacy Policy
for more information.
Database scaling enables systems to handle growing workloads. As data volumes and user counts increase, understanding horizontal and vertical scaling, replication, and sharding becomes essential for system architects.
Series Context: This is Part 11 of 15 in the Complete Database Mastery series. We're tackling the architecture challenges of large-scale systems.
Think of scaling like upgrading a restaurant: Vertical scaling = get a bigger kitchen. Horizontal scaling = open more locations. Both have tradeoffs.
Scaling Approaches
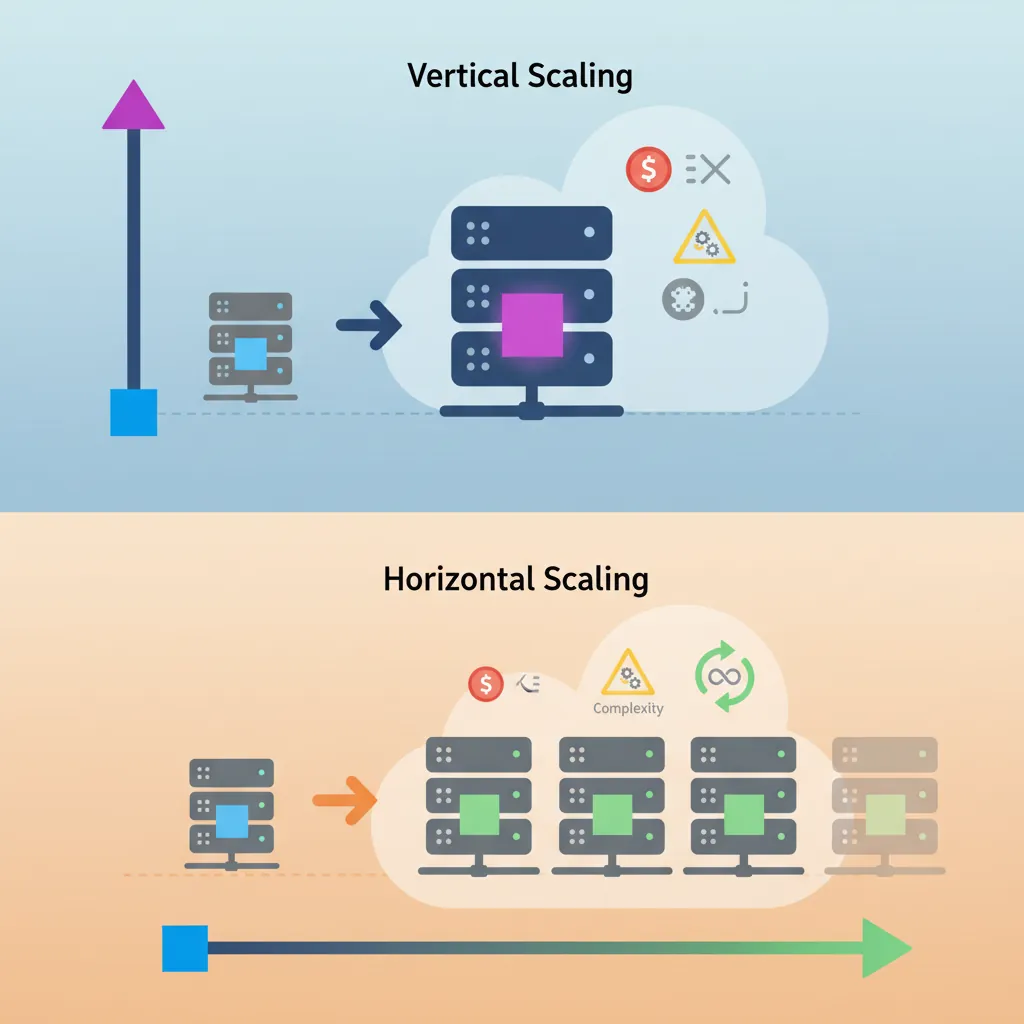
Vertical Scaling (Scale Up)
Add more power to a single machine: more CPU, RAM, faster storage.
Scaling approaches: vertical (bigger hardware) vs horizontal (more machines) with tradeoffs in cost, complexity, and limits
Vertical Scaling Characteristics
Pros
Cons
Simple—no code changes
Hardware limits (can't scale forever)
No distributed complexity
Single point of failure
ACID transactions work normally
Expensive at high end
Lower latency (no network hops)
Downtime during upgrades
Horizontal Scaling (Scale Out)
Add more machines to distribute the load. More complex but virtually unlimited.
-- Example: Application routes queries based on user ID
-- Shard 1: Users 1-1,000,000
-- Shard 2: Users 1,000,001-2,000,000
-- etc.
-- Application logic determines routing
user_id = 1,500,000
shard = (user_id / 1000000) + 1 -- Shard 2
When to Scale Horizontally: When you've maximized vertical scaling, need geographic distribution, require fault tolerance, or have predictable sharding keys.
Replication Architectures
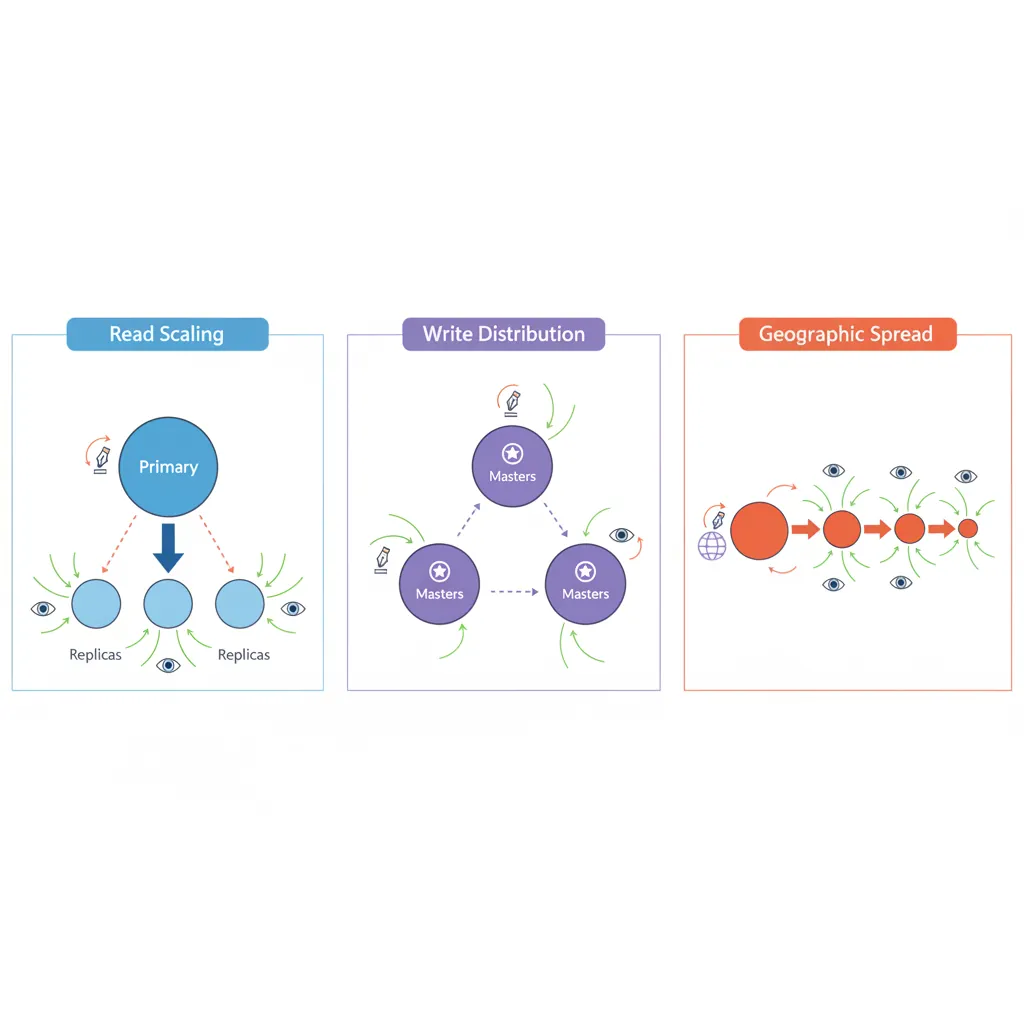
Replication copies data across multiple servers for redundancy and read scaling.
Replication architectures: primary-replica for read scaling, multi-master for write distribution, chain replication for geographic spread
# Application-level read/write routing
class DatabaseRouter:
def get_connection(self, query_type):
if query_type == 'write':
return primary_connection
else:
# Round-robin across replicas
return random.choice(replica_connections)
# Or use a proxy like PgBouncer, ProxySQL, HAProxy
Multi-Master
Multiple servers accept writes. Complex but enables geographic distribution.
# MySQL Group Replication (Multi-Primary Mode)
# Each node can accept writes; conflicts resolved automatically
SET GLOBAL group_replication_single_primary_mode = OFF;
SET GLOBAL group_replication_enforce_update_everywhere_checks = ON;
START GROUP_REPLICATION;
Multi-Master Challenges: Conflict resolution (last-write-wins vs merge), increased latency for consistency, complexity in debugging. Use only when truly needed.
Synchronous vs Asynchronous Replication
Replication Modes
Mode
Behavior
Tradeoff
Synchronous
Wait for replica acknowledgment
Zero data loss, higher latency
Asynchronous
Return immediately after primary write
Lower latency, potential data loss
Semi-synchronous
Wait for at least one replica
Balance of both
Sharding Strategies
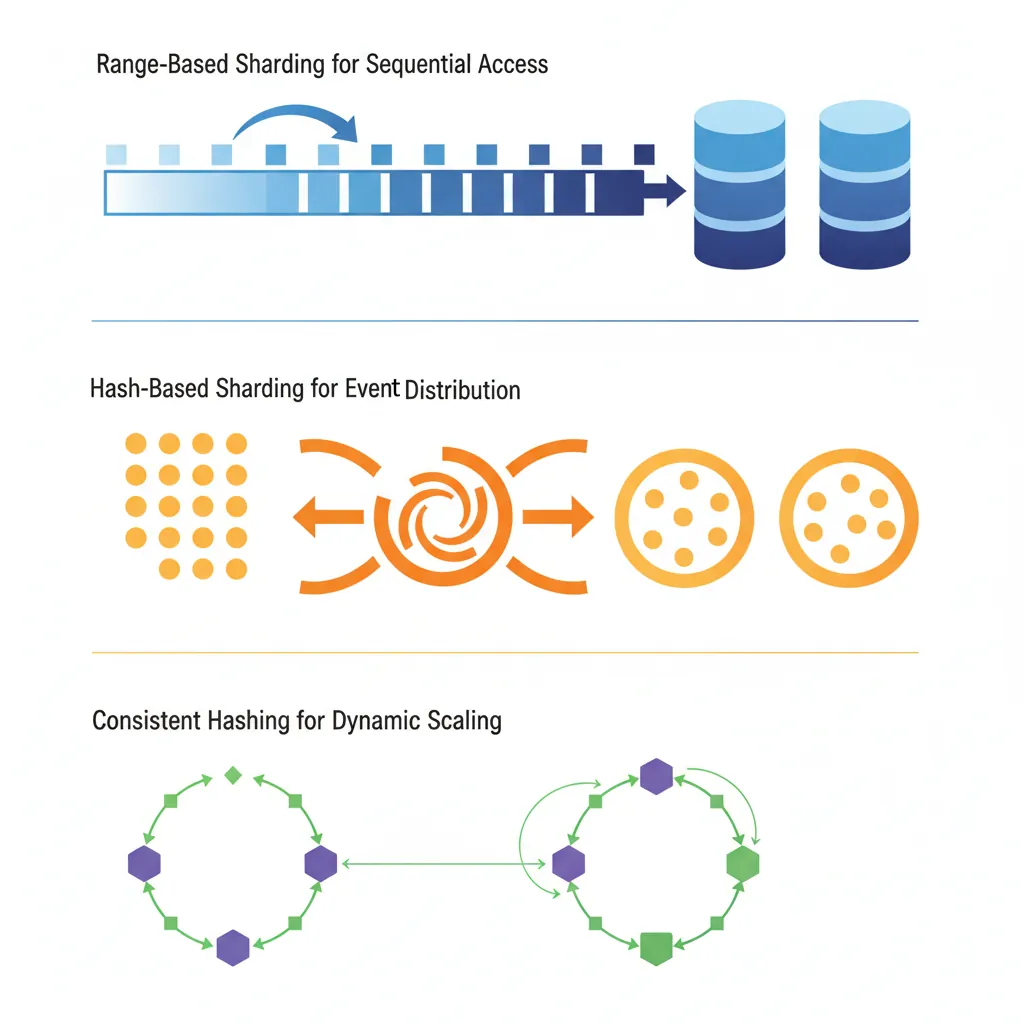
Sharding partitions data across multiple databases. Each shard holds a subset of the data.
Sharding strategies: range-based for sequential access, hash-based for even distribution, consistent hashing for dynamic scaling
Range-Based Sharding
Partition by value ranges. Good for sequential access patterns.
-- Range sharding by date
-- Shard 2023: orders from 2023
-- Shard 2024: orders from 2024
-- Routing logic
IF order_date >= '2024-01-01' THEN
USE shard_2024;
ELSE
USE shard_2023;
END IF;
Hotspot Risk: If most queries hit recent data, the newest shard becomes overloaded. Consider time-based archiving.
Hash-Based Sharding
Hash the sharding key for even distribution. Best for random access patterns.
# Hash-based shard routing
def get_shard(user_id, num_shards=4):
return hash(user_id) % num_shards
# user_id=12345 → shard 1
# user_id=67890 → shard 2
# Even distribution regardless of user_id patterns
Consistent Hashing
Minimizes data movement when adding/removing shards. Essential for dynamic scaling.
# Consistent hashing concept
# Nodes placed on a hash ring (0-360 degrees)
# Keys hash to a position, route to nearest clockwise node
# Without consistent hashing:
# Adding a shard moves ~50% of data
# With consistent hashing:
# Adding a shard moves only 1/N of data
# (where N = number of shards)
Sharding Key Selection
Good Keys
Bad Keys
user_id (for user-centric apps)
Auto-increment ID (sequential hotspots)
tenant_id (for SaaS)
Date alone (recent data hotspot)
geographic_region
Low-cardinality fields (status, type)
CAP Theorem & PACELC
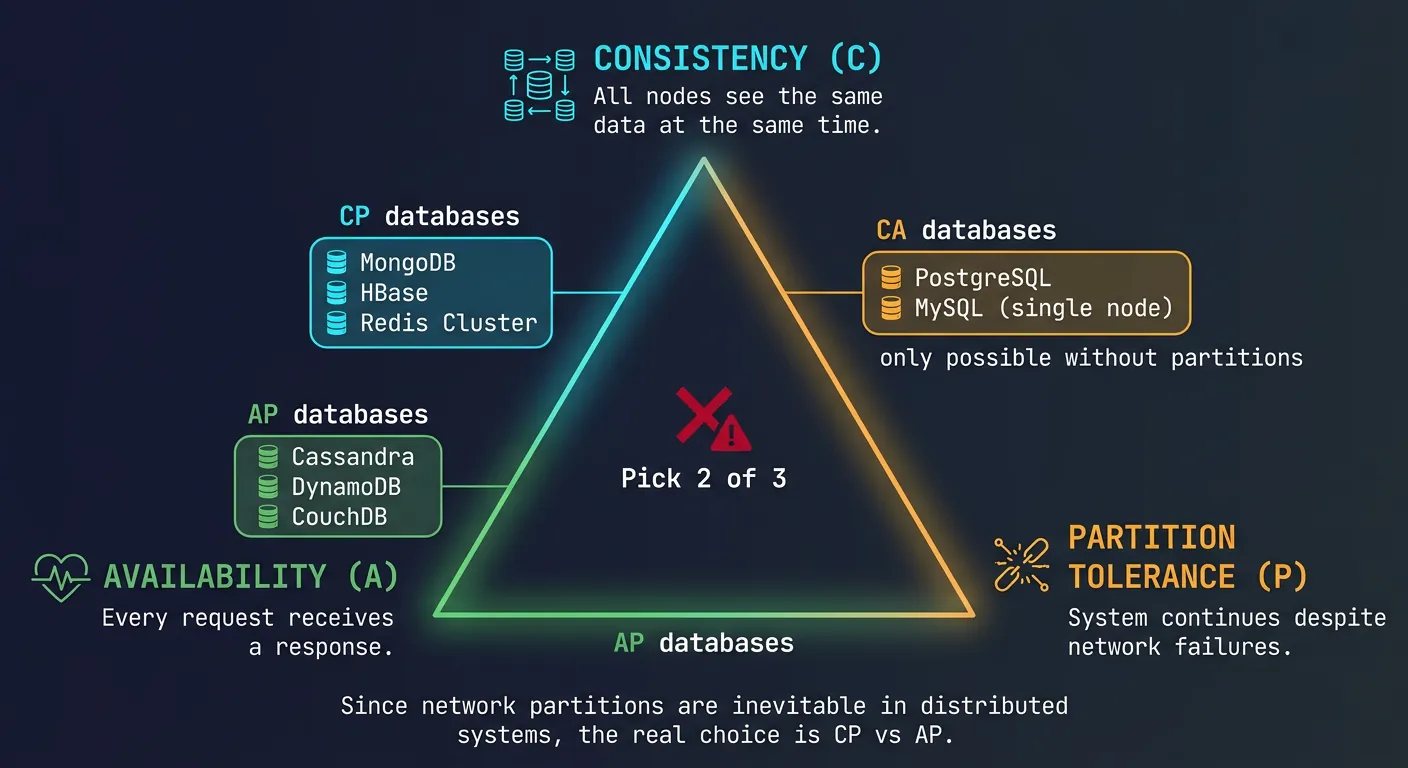
CAP Theorem
In a distributed system, you can only guarantee two of three properties:
CAP theorem: distributed systems must choose between consistency, availability, and partition tolerance—only two can be guaranteed
CAP Properties
Consistency (C): All nodes see the same data at the same time
Availability (A): Every request receives a response (success or failure)
Partition Tolerance (P): System continues despite network failures
Since network partitions are inevitable, the real choice is:
During a network partition:
CP (Consistency + Partition Tolerance):
- Refuse requests if consistency can't be guaranteed
- Examples: PostgreSQL, MongoDB (with majority writes)
- Use case: Financial transactions, inventory systems
AP (Availability + Partition Tolerance):
- Serve requests even with potentially stale data
- Examples: Cassandra, DynamoDB (eventual consistency)
- Use case: Social media feeds, analytics
PACELC Extension
CAP only describes partition behavior. PACELC adds: "Else (no partition), what's the Latency vs Consistency tradeoff?"
PACELC: If Partition → choose A or C
Else → choose Latency or Consistency
Examples:
- DynamoDB: PA/EL (Available during partition, low latency normally)
- PostgreSQL: PC/EC (Consistent always, but slower)
- Cassandra: PA/EL (Available, low latency, eventual consistency)
Distributed Consensus
How do distributed nodes agree on the state of data? Consensus algorithms solve this.
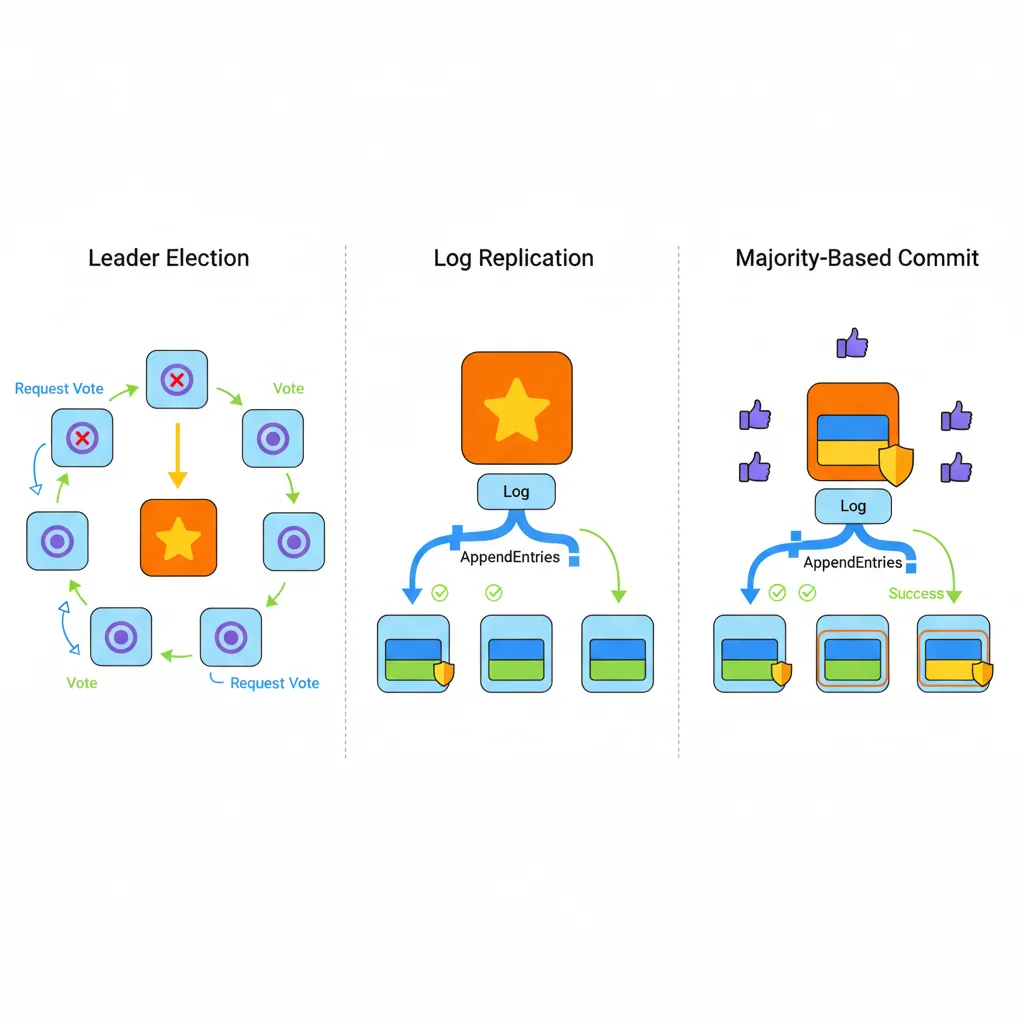
Distributed consensus: Raft algorithm with leader election, log replication, and majority-based commit for consistent state
Common Consensus Algorithms
Algorithm
Used By
Key Idea
Paxos
Google Spanner, Chubby
Classic, complex, proven
Raft
etcd, CockroachDB, Consul
Understandable Paxos alternative
Zab
ZooKeeper
Optimized for primary-backup
Raft Consensus (Simplified):
1. Leader Election: Nodes vote for a leader
2. Log Replication: Leader appends entries, replicates to followers
3. Commit: Entry committed when majority acknowledges
4. Leader fails → New election → New leader
Quorum = (N/2) + 1
- 3 nodes: need 2 to agree
- 5 nodes: need 3 to agree
Case Studies
Database Architecture Examples
System
Architecture
CAP Choice
Google Spanner
Globally distributed, TrueTime
CP (strong consistency)
Amazon DynamoDB
Multi-region, eventual consistency
AP (configurable)
CockroachDB
Raft consensus, serializable
CP (SQL + distributed)
Cassandra
Masterless, tunable consistency
AP (default)
Modern Trend: NewSQL databases like CockroachDB, Spanner, and YugabyteDB offer the best of both worlds—SQL semantics with horizontal scaling.
Conclusion & Next Steps
Distributed databases are the backbone of internet-scale applications. Understanding CAP tradeoffs, replication topologies, and sharding strategies is essential for architects building resilient systems.
Continue the Database Mastery Series
Part 10: Database Administration & Migrations
Operations fundamentals before scaling complexity.