Introduction to Advanced Tasks
Advanced NLP tasks go beyond simple classification to generate or extract complex outputs. These tasks power search engines, virtual assistants, and content creation tools.
Key Insight
Advanced NLP tasks often combine multiple capabilities—understanding context, reasoning over information, and generating coherent natural language outputs.
NLP Mastery
NLP Fundamentals & Linguistic Basics
Phonology, morphology, syntax, semantics, pragmaticsTokenization & Text Cleaning
Subword tokenization, BPE, stopwords, normalizationText Representation & Feature Engineering
Bag-of-words, TF-IDF, feature extraction, vectorizationWord Embeddings
Word2Vec, GloVe, FastText, embedding spaces, analogiesStatistical Language Models & N-grams
Probability chains, smoothing, perplexity, Markov modelsNeural Networks for NLP
Feedforward nets, backpropagation, activation functionsRNNs, LSTMs & GRUs
Sequence modeling, vanishing gradients, gated architecturesTransformers & Attention Mechanism
Self-attention, multi-head attention, positional encodingPretrained Language Models & Transfer Learning
BERT, RoBERTa, fine-tuning, feature extractionGPT Models & Text Generation
Autoregressive generation, prompting, GPT architectureCore NLP Tasks
NER, POS tagging, sentiment analysis, text classificationAdvanced NLP Tasks
Question answering, summarization, machine translationMultilingual & Cross-lingual NLP
mBERT, XLM-R, zero-shot transfer, language diversityEvaluation, Ethics & Responsible NLP
BLEU, ROUGE, bias detection, fairness, responsible AINLP Systems, Optimization & Production
Model serving, quantization, distillation, deploymentCutting-Edge & Research Topics
LLMs, multimodal NLP, reasoning, emerging researchQuestion Answering
Question Answering (QA) is one of the most impactful applications of NLP, enabling machines to understand questions posed in natural language and retrieve or generate accurate answers. QA systems power search engines, virtual assistants like Siri and Alexa, and enterprise knowledge management tools. The fundamental challenge lies in understanding the semantic intent of the question, locating relevant information, and presenting it in a useful format.
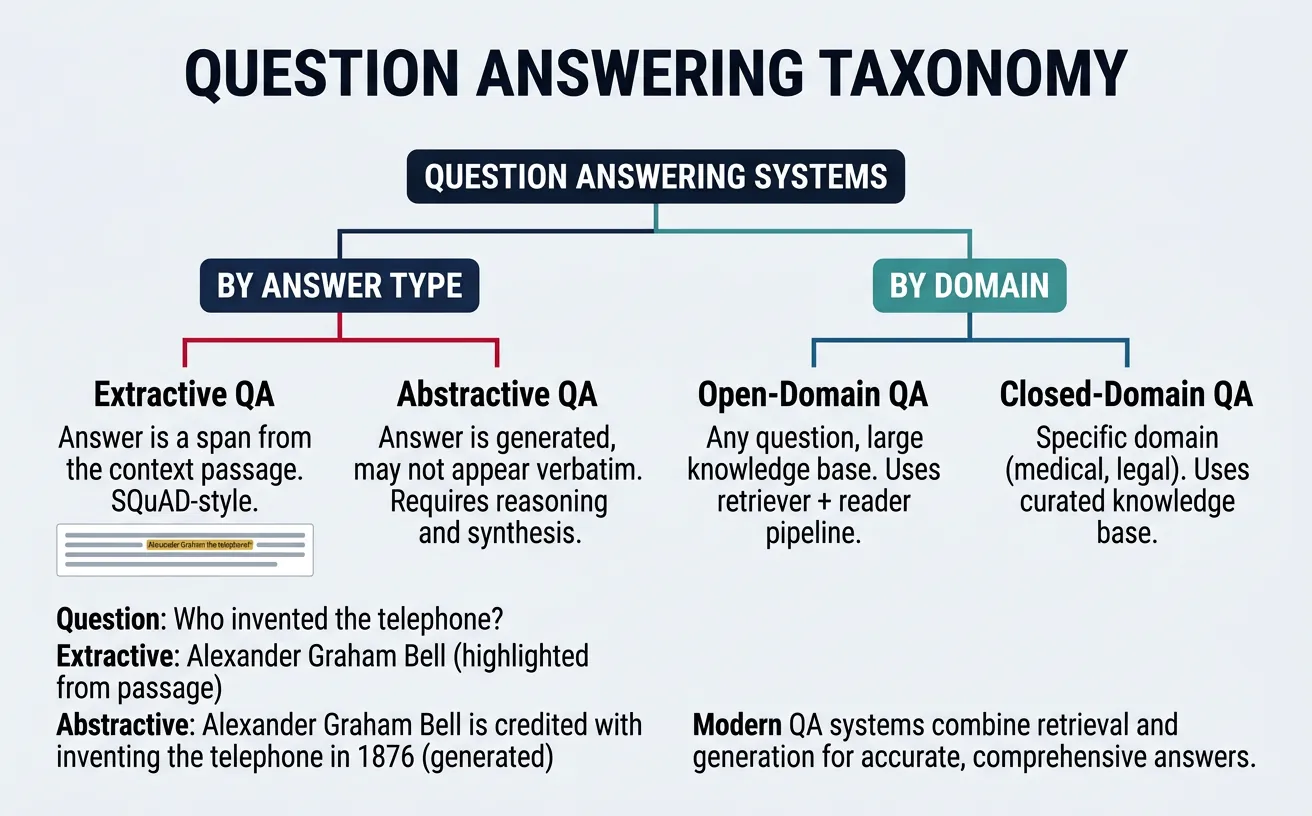
QA systems can be categorized by their answer source: closed-domain systems answer questions from a specific knowledge base (medical, legal), while open-domain systems can answer questions from broad knowledge sources like Wikipedia. They can also be categorized by answer generation method: extractive systems select spans from source documents, while abstractive systems generate novel text. Modern systems often combine retrieval and generation in sophisticated pipelines.
QA System Types
Reading Comprehension: Given a passage and question, find the answer within the passage. Knowledge Base QA: Query structured knowledge graphs (Wikidata, Freebase). Open-Domain QA: Retrieve relevant documents then extract/generate answers. Conversational QA: Answer questions in dialogue context with follow-ups.
Extractive QA
Extractive Question Answering identifies the exact span of text within a context passage that answers the question. This approach was popularized by the SQuAD (Stanford Question Answering Dataset) benchmark, where models predict start and end positions of answer spans. Extractive QA is highly interpretable since answers come directly from source text, making it suitable for applications requiring verifiable, citation-backed responses.
Modern extractive QA systems use transformer models fine-tuned on QA datasets. The model receives both the question and context passage, then predicts probability distributions over all tokens for being the answer's start and end positions. BERT-based models excel at this task because their bidirectional attention allows understanding the relationship between question tokens and all context tokens simultaneously.
SQuAD Dataset Structure
SQuAD 1.1: 100,000+ question-answer pairs from 500+ Wikipedia articles. Every question has an answer span in the passage. SQuAD 2.0: Adds 50,000+ unanswerable questions where the model must recognize that the passage doesn't contain the answer. This requires models to understand when to say "I don't know."
# Extractive QA with Hugging Face Transformers
from transformers import pipeline
# Load pre-trained extractive QA model
qa_pipeline = pipeline(
"question-answering",
model="distilbert-base-cased-distilled-squad"
)
# Example context and question
context = """
The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France.
It is named after the engineer Gustave Eiffel, whose company designed and built the tower.
Constructed from 1887 to 1889, it was initially criticized by some of France's leading
artists and intellectuals. It has become a global cultural icon of France and one of the
most recognizable structures in the world. The tower is 330 metres (1,083 ft) tall.
"""
question = "Who designed the Eiffel Tower?"
# Get answer
result = qa_pipeline(question=question, context=context)
print(f"Answer: {result['answer']}")
print(f"Confidence: {result['score']:.4f}")
print(f"Start position: {result['start']}, End position: {result['end']}")
# Output:
# Answer: Gustave Eiffel
# Confidence: 0.9842
# Start position: 147, End position: 161# Multiple questions on the same context
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="deepset/roberta-base-squad2" # SQuAD 2.0 model handles unanswerable
)
context = """
Natural language processing (NLP) is a subfield of linguistics, computer science,
and artificial intelligence concerned with the interactions between computers and
human language. The goal is to enable computers to understand, interpret, and
generate human language in a way that is both meaningful and useful. NLP combines
computational linguistics with statistical, machine learning, and deep learning models.
Major NLP tasks include speech recognition, natural language understanding, and
natural language generation.
"""
questions = [
"What is NLP?",
"What fields contribute to NLP?",
"What are major NLP tasks?",
"Who invented NLP?" # Unanswerable from context
]
for q in questions:
result = qa_pipeline(question=q, context=context)
print(f"Q: {q}")
print(f"A: {result['answer']} (confidence: {result['score']:.3f})")
print("-" * 50)Generative QA
Generative Question Answering (also called abstractive QA) generates answers in natural language rather than extracting verbatim spans. This approach can synthesize information from multiple sources, rephrase complex passages into simpler answers, and handle questions requiring inference or reasoning. Generative models use encoder-decoder architectures (T5, BART) or decoder-only models (GPT) to produce fluent, contextually appropriate responses.
Generative QA excels when answers require combining information, providing explanations, or when the exact answer phrasing doesn't appear in source text. However, it introduces risks of hallucination—generating plausible-sounding but factually incorrect information. Production systems often combine extractive retrieval with generative synthesis, grounding generated answers in retrieved evidence to improve factual accuracy.
# Generative QA with T5 model
from transformers import pipeline
# T5 for generative question answering
generator = pipeline(
"text2text-generation",
model="google/flan-t5-base"
)
# Context with complex information
context = """
Photosynthesis is the process by which plants convert light energy, usually from
the sun, into chemical energy in the form of glucose. This process occurs in the
chloroplasts of plant cells, specifically in structures called thylakoids.
Photosynthesis requires carbon dioxide from the air and water from the soil.
As a byproduct, oxygen is released into the atmosphere. The chemical equation is:
6CO2 + 6H2O + light energy → C6H12O6 + 6O2.
"""
# Format prompt for T5
question = "Explain what happens during photosynthesis in simple terms."
prompt = f"Answer the question based on the context.\n\nContext: {context}\n\nQuestion: {question}\n\nAnswer:"
result = generator(prompt, max_length=100, do_sample=False)
print("Generated Answer:")
print(result[0]['generated_text'])
# Output:
# Plants use sunlight to turn carbon dioxide and water into sugar (glucose)
# and release oxygen as a waste product.# Generative QA with BART
from transformers import BartForConditionalGeneration, BartTokenizer
model_name = "facebook/bart-large-cnn"
tokenizer = BartTokenizer.from_pretrained(model_name)
model = BartForConditionalGeneration.from_pretrained(model_name)
def generate_answer(context, question, max_length=100):
"""Generate an answer using BART."""
# Format input
input_text = f"Question: {question} Context: {context}"
inputs = tokenizer(input_text, return_tensors="pt", max_length=1024, truncation=True)
# Generate
outputs = model.generate(
inputs['input_ids'],
max_length=max_length,
num_beams=4,
early_stopping=True
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example
context = """
Machine learning is a subset of artificial intelligence that enables systems to
learn and improve from experience without being explicitly programmed. ML algorithms
build mathematical models based on training data to make predictions or decisions.
Types include supervised learning (labeled data), unsupervised learning (finding patterns),
and reinforcement learning (learning through rewards).
"""
question = "What are the types of machine learning?"
answer = generate_answer(context, question)
print(f"Answer: {answer}")Open-Domain QA
Open-Domain Question Answering systems answer questions from a large corpus (like all of Wikipedia) without being given a specific passage. This requires two key components: a retriever that finds relevant documents from millions of candidates, and a reader that extracts or generates answers from retrieved documents. Modern systems like DPR (Dense Passage Retrieval) and RAG (Retrieval-Augmented Generation) have dramatically improved open-domain QA performance.
The retrieval stage uses dense embeddings rather than keyword matching for semantic search. Documents and questions are encoded into the same vector space, and nearest-neighbor search finds relevant passages. The reader then processes these passages to produce the final answer. RAG models combine retrieval with generation end-to-end, allowing the generator to attend to retrieved documents and produce more factual, grounded responses.
Retrieval-Augmented Generation (RAG)
Key insight: RAG models don't need to memorize all world knowledge in their parameters. Instead, they retrieve relevant documents at inference time and use them to generate answers. This makes models more factual, updateable (just update the document index), and interpretable (you can see which documents informed the answer).
# Simple Open-Domain QA with sentence-transformers for retrieval
from sentence_transformers import SentenceTransformer
import numpy as np
# Load embedding model for retrieval
embedder = SentenceTransformer('all-MiniLM-L6-v2')
# Simulated knowledge base (in practice, this would be millions of passages)
knowledge_base = [
"The Great Wall of China is approximately 21,196 kilometers long.",
"The Amazon River is the largest river by discharge volume of water.",
"Mount Everest is 8,849 meters tall, making it Earth's highest mountain.",
"The Pacific Ocean is the largest and deepest ocean on Earth.",
"The human brain contains approximately 86 billion neurons.",
"Light travels at 299,792,458 meters per second in a vacuum.",
"DNA was first identified by Friedrich Miescher in 1869.",
"The Moon is approximately 384,400 kilometers from Earth."
]
# Encode all passages
passage_embeddings = embedder.encode(knowledge_base)
def retrieve_and_answer(question, top_k=3):
"""Retrieve relevant passages for a question."""
# Encode question
question_embedding = embedder.encode([question])[0]
# Compute cosine similarities
similarities = np.dot(passage_embeddings, question_embedding) / (
np.linalg.norm(passage_embeddings, axis=1) * np.linalg.norm(question_embedding)
)
# Get top-k passages
top_indices = np.argsort(similarities)[-top_k:][::-1]
print(f"Question: {question}\n")
print("Retrieved passages:")
for i, idx in enumerate(top_indices):
print(f" {i+1}. [{similarities[idx]:.3f}] {knowledge_base[idx]}")
return [knowledge_base[i] for i in top_indices]
# Test retrieval
retrieve_and_answer("How tall is the highest mountain?")
print()
retrieve_and_answer("How fast does light travel?")# Full RAG pipeline with Hugging Face
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
# Note: This requires the wiki_dpr dataset to be downloaded
# For demonstration, we'll use a simpler approach
from transformers import pipeline, AutoModelForSeq2SeqLM, AutoTokenizer
# Use FLAN-T5 for the generation part
model_name = "google/flan-t5-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
def rag_style_qa(question, retrieved_passages):
"""
Simulate RAG by combining retrieved passages with the question.
"""
# Combine retrieved passages
context = " ".join(retrieved_passages)
# Format prompt
prompt = f"""Answer the question based only on the given context.
Context: {context}
Question: {question}
Answer:"""
# Tokenize and generate
inputs = tokenizer(prompt, return_tensors="pt", max_length=512, truncation=True)
outputs = model.generate(
inputs['input_ids'],
max_length=100,
num_beams=4,
early_stopping=True
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example with retrieved passages
retrieved = [
"Mount Everest is 8,849 meters tall, making it Earth's highest mountain.",
"K2 is the second highest mountain at 8,611 meters."
]
question = "What is the height of Mount Everest?"
answer = rag_style_qa(question, retrieved)
print(f"Q: {question}")
print(f"A: {answer}")Text Summarization
Text Summarization condenses long documents into shorter versions while preserving key information. As information overload grows, summarization becomes essential for news aggregation, document review, meeting notes, and research synthesis. Effective summaries capture the main points, maintain factual accuracy, and present information in a coherent, readable format.
Summarization systems are evaluated using ROUGE (Recall-Oriented Understudy for Gisting Evaluation) metrics that compare generated summaries against human reference summaries. ROUGE-1 measures unigram overlap, ROUGE-2 measures bigram overlap, and ROUGE-L measures longest common subsequence. However, automatic metrics don't capture all aspects of summary quality—factual consistency and coherence often require human evaluation.
Extractive Summarization
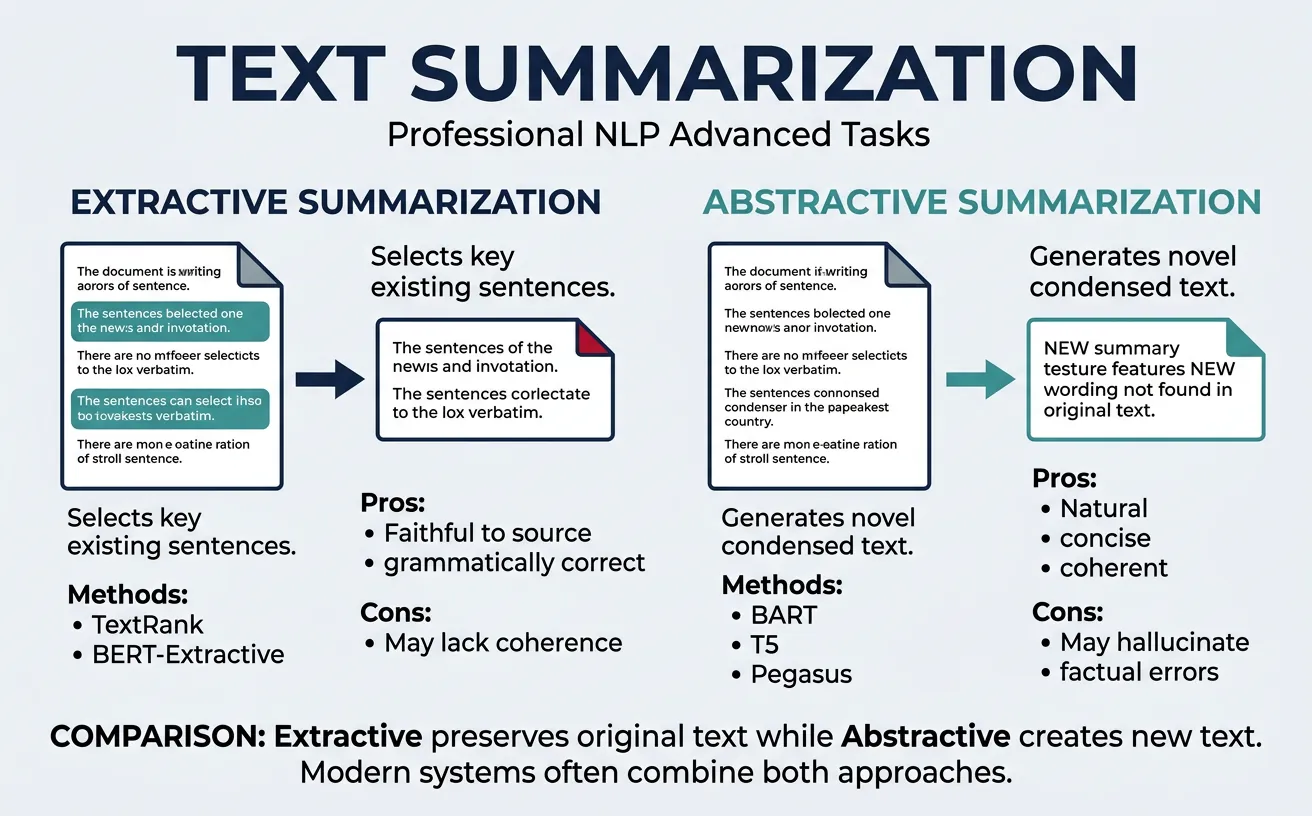
Extractive summarization selects and combines the most important sentences from the original document. This approach guarantees factual accuracy (since sentences come directly from the source) but may produce summaries that lack coherence or contain redundant information. Classic methods use TF-IDF scoring, graph-based algorithms (TextRank), or learned sentence importance classifiers.
Modern extractive systems use neural models to score sentence importance. BERT-based models can encode entire documents and predict which sentences should be included in the summary. The key challenges are selecting sentences that are both individually important and collectively non-redundant, and ordering them to create a coherent narrative.
# Extractive Summarization with NLTK and TF-IDF
import nltk
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from collections import Counter
import math
# Download required resources
nltk.download('punkt', quiet=True)
nltk.download('stopwords', quiet=True)
nltk.download('punkt_tab', quiet=True)
def extractive_summarize(text, num_sentences=3):
"""
Simple extractive summarization using TF-IDF scoring.
"""
# Tokenize into sentences
sentences = sent_tokenize(text)
# Preprocess: tokenize and remove stopwords
stop_words = set(stopwords.words('english'))
def preprocess(sentence):
words = word_tokenize(sentence.lower())
return [w for w in words if w.isalnum() and w not in stop_words]
# Calculate word frequencies across all sentences
all_words = []
processed_sentences = []
for sent in sentences:
words = preprocess(sent)
processed_sentences.append(words)
all_words.extend(words)
word_freq = Counter(all_words)
# Score each sentence based on word importance
sentence_scores = []
for i, words in enumerate(processed_sentences):
if len(words) == 0:
sentence_scores.append(0)
continue
score = sum(word_freq[w] for w in words) / len(words)
sentence_scores.append(score)
# Get top sentences (maintaining original order)
ranked_indices = sorted(range(len(sentences)),
key=lambda i: sentence_scores[i],
reverse=True)[:num_sentences]
ranked_indices.sort() # Restore original order
summary = ' '.join(sentences[i] for i in ranked_indices)
return summary
# Example text
article = """
Artificial intelligence has transformed many industries in recent years.
Companies across sectors are implementing AI solutions to improve efficiency
and reduce costs. Healthcare organizations use AI for diagnosis and drug discovery.
Financial institutions employ machine learning for fraud detection and risk assessment.
Manufacturing companies leverage AI for predictive maintenance and quality control.
However, the rapid adoption of AI also raises concerns about job displacement and ethics.
Experts recommend careful consideration of AI's societal impacts alongside its benefits.
The technology continues to evolve rapidly, with new breakthroughs announced regularly.
Governments worldwide are developing regulations to ensure responsible AI development.
"""
summary = extractive_summarize(article, num_sentences=3)
print("Original length:", len(article.split()))
print("Summary length:", len(summary.split()))
print("\nSummary:")
print(summary)# TextRank algorithm for extractive summarization
import nltk
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
nltk.download('punkt', quiet=True)
nltk.download('stopwords', quiet=True)
nltk.download('punkt_tab', quiet=True)
def textrank_summarize(text, num_sentences=3, damping=0.85, iterations=100):
"""
TextRank algorithm for extractive summarization.
Based on PageRank applied to sentence similarity graph.
"""
sentences = sent_tokenize(text)
if len(sentences) <= num_sentences:
return text
stop_words = set(stopwords.words('english'))
# Create sentence vectors using word overlap
def get_sentence_vector(sentence):
words = word_tokenize(sentence.lower())
words = [w for w in words if w.isalnum() and w not in stop_words]
return set(words)
sentence_vectors = [get_sentence_vector(s) for s in sentences]
# Build similarity matrix
n = len(sentences)
similarity_matrix = np.zeros((n, n))
for i in range(n):
for j in range(n):
if i != j and len(sentence_vectors[i]) > 0 and len(sentence_vectors[j]) > 0:
# Jaccard similarity
intersection = len(sentence_vectors[i] & sentence_vectors[j])
union = len(sentence_vectors[i] | sentence_vectors[j])
similarity_matrix[i][j] = intersection / union if union > 0 else 0
# Normalize
row_sums = similarity_matrix.sum(axis=1, keepdims=True)
row_sums[row_sums == 0] = 1 # Avoid division by zero
similarity_matrix = similarity_matrix / row_sums
# TextRank iteration (PageRank algorithm)
scores = np.ones(n) / n
for _ in range(iterations):
new_scores = (1 - damping) / n + damping * similarity_matrix.T @ scores
scores = new_scores
# Select top sentences
ranked_indices = np.argsort(scores)[-num_sentences:]
ranked_indices = sorted(ranked_indices) # Maintain order
return ' '.join(sentences[i] for i in ranked_indices)
# Test
text = """
Climate change is one of the most pressing challenges facing humanity today.
Rising global temperatures are causing ice caps to melt and sea levels to rise.
Extreme weather events, including hurricanes, droughts, and floods, are becoming more frequent.
Scientists warn that immediate action is necessary to prevent catastrophic consequences.
Many countries have committed to reducing carbon emissions through the Paris Agreement.
Renewable energy sources like solar and wind power are growing rapidly.
Electric vehicles are becoming more affordable and widely adopted.
However, progress remains slow compared to what experts say is needed.
Individual actions, while important, must be accompanied by systemic policy changes.
The next decade will be crucial in determining the future of our planet.
"""
summary = textrank_summarize(text, num_sentences=3)
print("TextRank Summary:")
print(summary)Abstractive Summarization
Abstractive summarization generates new sentences that capture the essence of the original text, much like a human would write a summary. This approach can paraphrase, combine information, and create more fluent, coherent summaries. Transformer-based models like BART, T5, and PEGASUS have achieved remarkable results, often producing summaries indistinguishable from human-written ones.
The main challenge with abstractive summarization is faithfulness—ensuring the summary accurately represents the source without adding false information. Models can "hallucinate" facts not present in the original or contradict the source. Research focuses on improving factual consistency through better training objectives, constrained decoding, and post-generation verification.
ROUGE Evaluation Metrics
ROUGE-1: Unigram overlap between generated and reference summary. ROUGE-2: Bigram overlap, captures phrase-level similarity. ROUGE-L: Longest common subsequence, measures sentence-level structure. ROUGE-Lsum: Applies ROUGE-L at summary level (for multi-sentence). Each metric has precision (P), recall (R), and F1 variants.
# Abstractive Summarization with BART
from transformers import pipeline
# Load summarization pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
article = """
The James Webb Space Telescope (JWST) has revolutionized our understanding of the
universe since its launch in December 2021. The telescope, a collaboration between
NASA, ESA, and CSA, is the largest and most powerful space telescope ever built.
Its primary mirror spans 6.5 meters and consists of 18 hexagonal gold-plated
beryllium segments. Unlike Hubble, which observes primarily in visible light,
JWST operates in the infrared spectrum, allowing it to peer through cosmic dust
and observe the earliest galaxies formed after the Big Bang.
The telescope orbits the Sun at the second Lagrange point (L2), approximately
1.5 million kilometers from Earth. This location provides a stable thermal
environment and allows continuous observations without Earth blocking the view.
The five-layer sunshield, about the size of a tennis court, keeps the instruments
at their operating temperature of -233°C (-387°F).
Recent discoveries include detailed images of exoplanet atmospheres, revealing
water vapor, carbon dioxide, and other molecules. JWST has captured stunning
images of stellar nurseries, showing star formation in unprecedented detail.
The telescope has also observed the most distant known galaxies, providing
insights into the early universe just a few hundred million years after the
Big Bang. Scientists expect JWST to operate for at least 20 years, continuing
to transform our understanding of the cosmos.
"""
# Generate summary
summary = summarizer(article, max_length=130, min_length=30, do_sample=False)
print("BART Summary:")
print(summary[0]['summary_text'])# T5 for summarization with different styles
from transformers import T5ForConditionalGeneration, T5Tokenizer
model_name = "t5-base"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def summarize_with_t5(text, max_length=150, min_length=40):
"""Generate summary using T5."""
# T5 requires "summarize: " prefix
input_text = "summarize: " + text
inputs = tokenizer(input_text, return_tensors="pt", max_length=1024, truncation=True)
outputs = model.generate(
inputs['input_ids'],
max_length=max_length,
min_length=min_length,
num_beams=4,
length_penalty=2.0,
early_stopping=True
)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example document
document = """
Quantum computing represents a fundamental shift in computational paradigms.
Unlike classical computers that use bits representing 0 or 1, quantum computers
use quantum bits or qubits that can exist in superposition of both states
simultaneously. This property, along with quantum entanglement, enables quantum
computers to perform certain calculations exponentially faster than classical machines.
Major technology companies including IBM, Google, and Microsoft are investing
heavily in quantum computing research. In 2019, Google claimed quantum supremacy
when their 53-qubit Sycamore processor completed a calculation in 200 seconds
that would take classical supercomputers thousands of years. However, practical
quantum computers that can outperform classical machines for useful tasks remain
years away due to challenges with qubit stability and error correction.
Potential applications include drug discovery, materials science, cryptography,
and optimization problems. Quantum computers could simulate molecular interactions
for pharmaceutical research and break current encryption methods while enabling
new quantum-safe cryptographic protocols.
"""
summary = summarize_with_t5(document)
print("T5 Summary:")
print(summary)# Evaluate summarization with ROUGE scores
from rouge_score import rouge_scorer
# Initialize ROUGE scorer
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
# Reference summary (human-written)
reference = """
Quantum computers use qubits in superposition to perform calculations faster than
classical computers. Major tech companies are investing in quantum research, with
Google claiming quantum supremacy in 2019. Applications include drug discovery,
cryptography, and optimization, though practical quantum computers are years away.
"""
# Generated summary (from model)
generated = """
Quantum computing uses qubits that can exist in superposition, enabling faster
calculations than classical computers. Google, IBM, and Microsoft are investing
in research, with Google demonstrating quantum supremacy in 2019. Potential
applications include pharmaceutical research and cryptography.
"""
# Calculate ROUGE scores
scores = scorer.score(reference, generated)
print("ROUGE Evaluation Scores:")
print("-" * 50)
for metric, values in scores.items():
print(f"{metric.upper()}:")
print(f" Precision: {values.precision:.4f}")
print(f" Recall: {values.recall:.4f}")
print(f" F1: {values.fmeasure:.4f}")Machine Translation
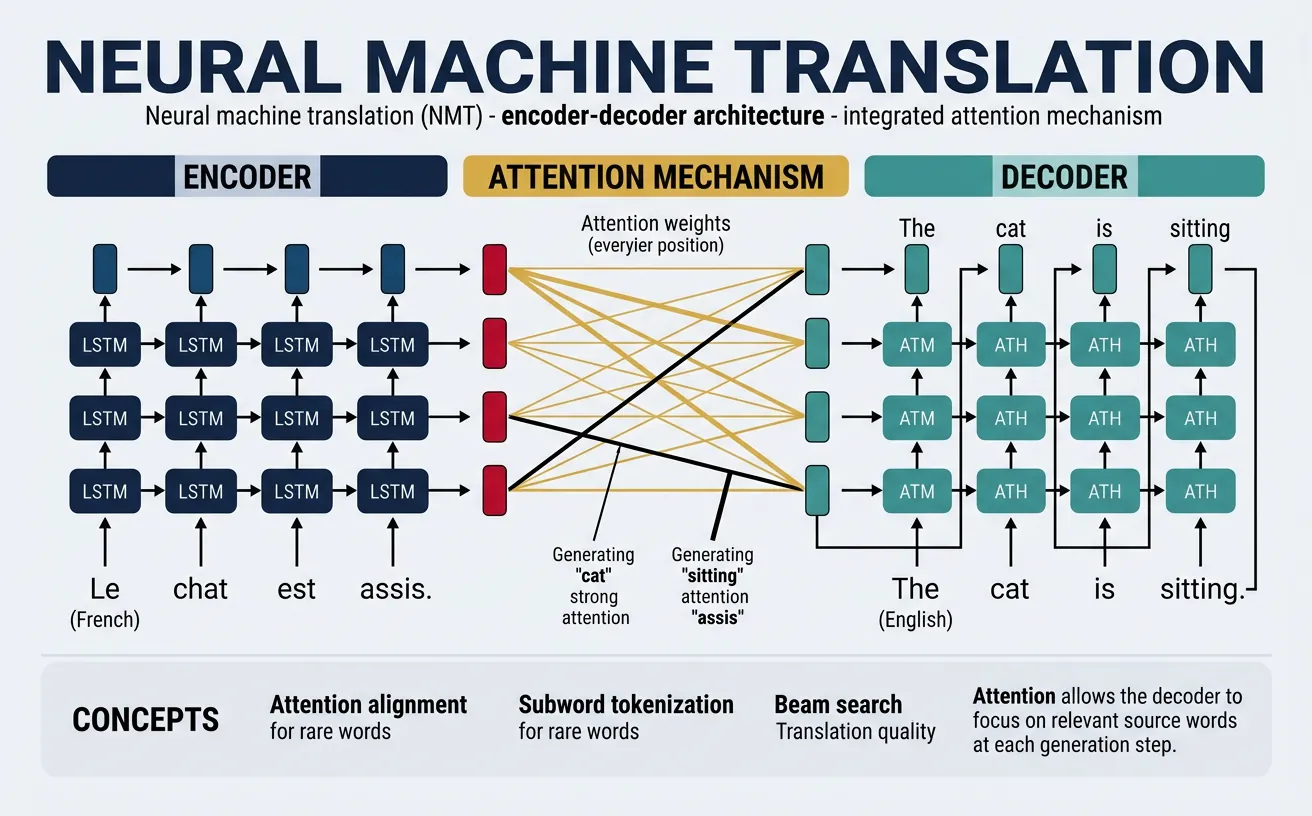
Machine Translation (MT) automatically converts text from one language to another. Modern neural MT systems have achieved near-human quality for many language pairs, powering services like Google Translate that handle billions of translations daily. The transformer architecture has been particularly transformative for MT, enabling models that capture long-range dependencies and produce more fluent, contextually appropriate translations.
Translation quality depends heavily on language pair resources. High-resource pairs (English-French, English-German) have abundant parallel corpora for training, while low-resource pairs require techniques like transfer learning, multilingual models, and back-translation for data augmentation. Translation evaluation uses metrics like BLEU (Bilingual Evaluation Understudy), though human evaluation remains the gold standard for assessing fluency and adequacy.
Translation Challenges
Ambiguity: Words have multiple meanings depending on context ("bank" = financial/river). Idioms: Phrases that don't translate literally ("it's raining cats and dogs"). Cultural context: References requiring cultural knowledge. Word order: Languages have different grammatical structures (SVO vs SOV). Morphology: Some languages express information through word forms that others express through separate words.
# Machine Translation with Hugging Face
from transformers import pipeline, MarianMTModel, MarianTokenizer
# English to French translation
en_fr_translator = pipeline("translation", model="Helsinki-NLP/opus-mt-en-fr")
english_text = "Artificial intelligence is transforming how we work and live."
french_result = en_fr_translator(english_text)
print(f"English: {english_text}")
print(f"French: {french_result[0]['translation_text']}")
# English to German
en_de_translator = pipeline("translation", model="Helsinki-NLP/opus-mt-en-de")
german_result = en_de_translator(english_text)
print(f"German: {german_result[0]['translation_text']}")
# English to Spanish
en_es_translator = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
spanish_result = en_es_translator(english_text)
print(f"Spanish: {spanish_result[0]['translation_text']}")# Multilingual translation with M2M-100
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
model_name = "facebook/m2m100_418M"
tokenizer = M2M100Tokenizer.from_pretrained(model_name)
model = M2M100ForConditionalGeneration.from_pretrained(model_name)
def translate(text, src_lang, tgt_lang):
"""Translate text between any supported language pair."""
tokenizer.src_lang = src_lang
encoded = tokenizer(text, return_tensors="pt")
generated_tokens = model.generate(
**encoded,
forced_bos_token_id=tokenizer.get_lang_id(tgt_lang),
max_length=128
)
return tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)[0]
# Translate between non-English pairs
text = "La inteligencia artificial está cambiando el mundo."
print("Spanish to French:")
print(translate(text, "es", "fr"))
print("\nSpanish to German:")
print(translate(text, "es", "de"))
print("\nSpanish to Chinese:")
print(translate(text, "es", "zh"))# BLEU score evaluation for translation
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu
from nltk.translate.bleu_score import SmoothingFunction
import nltk
nltk.download('punkt', quiet=True)
# Reference translations (can have multiple references)
references = [
["The", "weather", "is", "beautiful", "today"],
["Today", "the", "weather", "is", "nice"]
]
# Candidate translation (model output)
candidate = ["The", "weather", "is", "nice", "today"]
# Calculate BLEU score with smoothing
smoother = SmoothingFunction()
bleu_score = sentence_bleu(
references,
candidate,
smoothing_function=smoother.method1
)
print(f"BLEU Score: {bleu_score:.4f}")
# Corpus-level BLEU (multiple sentences)
all_references = [
[["The", "cat", "sat", "on", "the", "mat"]],
[["It", "is", "raining", "outside"]],
[["Natural", "language", "processing", "is", "fascinating"]]
]
all_candidates = [
["A", "cat", "is", "sitting", "on", "the", "mat"],
["It", "is", "raining", "outdoors"],
["NLP", "is", "fascinating"]
]
corpus_bleu_score = corpus_bleu(
all_references,
all_candidates,
smoothing_function=smoother.method1
)
print(f"Corpus BLEU Score: {corpus_bleu_score:.4f}")Dialogue Systems & Chatbots
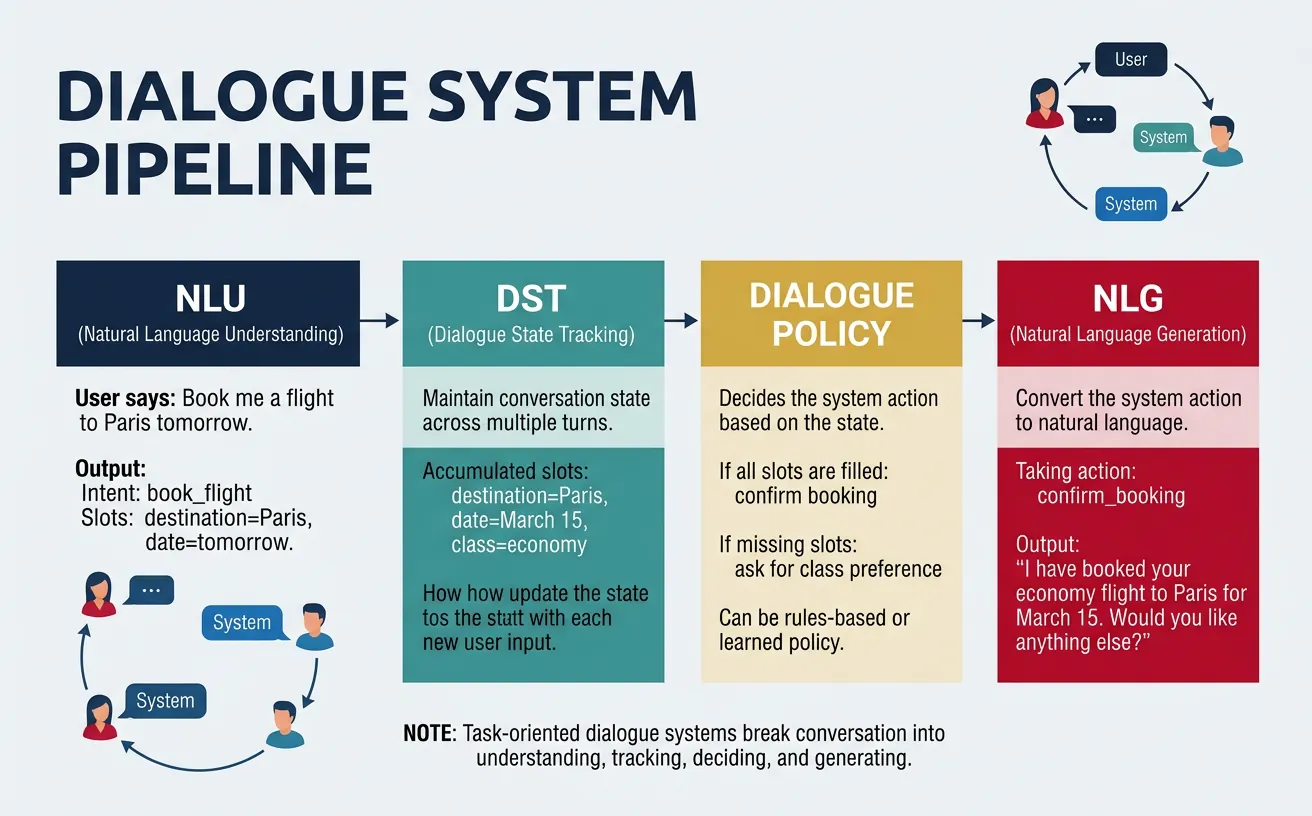
Dialogue systems enable natural language conversations between humans and computers. They range from simple rule-based chatbots to sophisticated AI assistants capable of multi-turn conversations, task completion, and personality consistency. The key challenge is maintaining coherent, contextually appropriate responses while tracking conversation state and user intent across multiple turns.
Dialogue systems are categorized as task-oriented (completing specific goals like booking flights or customer service) or open-domain (general conversation without specific objectives). Task-oriented systems typically use structured dialogue state tracking, while open-domain systems rely on large language models trained on conversational data. Modern systems often combine both approaches, handling specific tasks while maintaining engaging open-ended conversation.
Dialogue System Components
Natural Language Understanding (NLU): Parse user input, extract intents and entities. Dialogue State Tracking (DST): Maintain conversation context and user goals. Dialogue Policy: Decide system actions based on state. Natural Language Generation (NLG): Produce response text. End-to-end models: Replace pipeline with single neural network.
# Conversational AI with DialoGPT
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "microsoft/DialoGPT-medium"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
def chat(user_input, chat_history_ids=None, max_length=1000):
"""
Generate a response in a conversation.
"""
# Encode user input
new_input_ids = tokenizer.encode(
user_input + tokenizer.eos_token,
return_tensors='pt'
)
# Append to chat history
if chat_history_ids is not None:
bot_input_ids = torch.cat([chat_history_ids, new_input_ids], dim=-1)
else:
bot_input_ids = new_input_ids
# Generate response
chat_history_ids = model.generate(
bot_input_ids,
max_length=max_length,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=50,
top_p=0.95,
temperature=0.7
)
# Decode response
response = tokenizer.decode(
chat_history_ids[:, bot_input_ids.shape[-1]:][0],
skip_special_tokens=True
)
return response, chat_history_ids
# Simulate conversation
history = None
conversations = [
"Hi, how are you today?",
"What do you think about artificial intelligence?",
"Do you have any hobbies?"
]
print("=== DialoGPT Conversation ===\n")
for user_msg in conversations:
print(f"User: {user_msg}")
response, history = chat(user_msg, history)
print(f"Bot: {response}\n")# Intent classification for task-oriented dialogue
from transformers import pipeline
# Zero-shot classification for intent detection
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
def classify_intent(user_input, candidate_intents):
"""Classify user intent from predefined categories."""
result = classifier(user_input, candidate_intents)
return result['labels'][0], result['scores'][0]
# Define intents for a customer service bot
intents = [
"check_order_status",
"request_refund",
"product_inquiry",
"shipping_question",
"general_greeting",
"complaint"
]
# Test user inputs
test_inputs = [
"Where is my package?",
"I want my money back",
"Hello, is anyone there?",
"What colors does this come in?",
"This product is terrible, I'm very unhappy"
]
print("Intent Classification Results:")
print("-" * 50)
for text in test_inputs:
intent, confidence = classify_intent(text, intents)
print(f"Input: '{text}'")
print(f"Intent: {intent} (confidence: {confidence:.3f})\n")Information Extraction
Information Extraction (IE) identifies and extracts structured information from unstructured text. Key tasks include Named Entity Recognition (identifying entities like people, organizations, locations), Relation Extraction (finding relationships between entities), and Event Extraction (identifying events and their participants). IE powers knowledge base construction, search engines, and business intelligence systems.
Modern IE systems use neural sequence labeling for NER and transformer models fine-tuned on relation extraction datasets. The extracted information can populate knowledge graphs, enable structured queries over text, and support downstream applications like question answering. Challenges include handling nested entities, implicit relations, and domain-specific terminology.
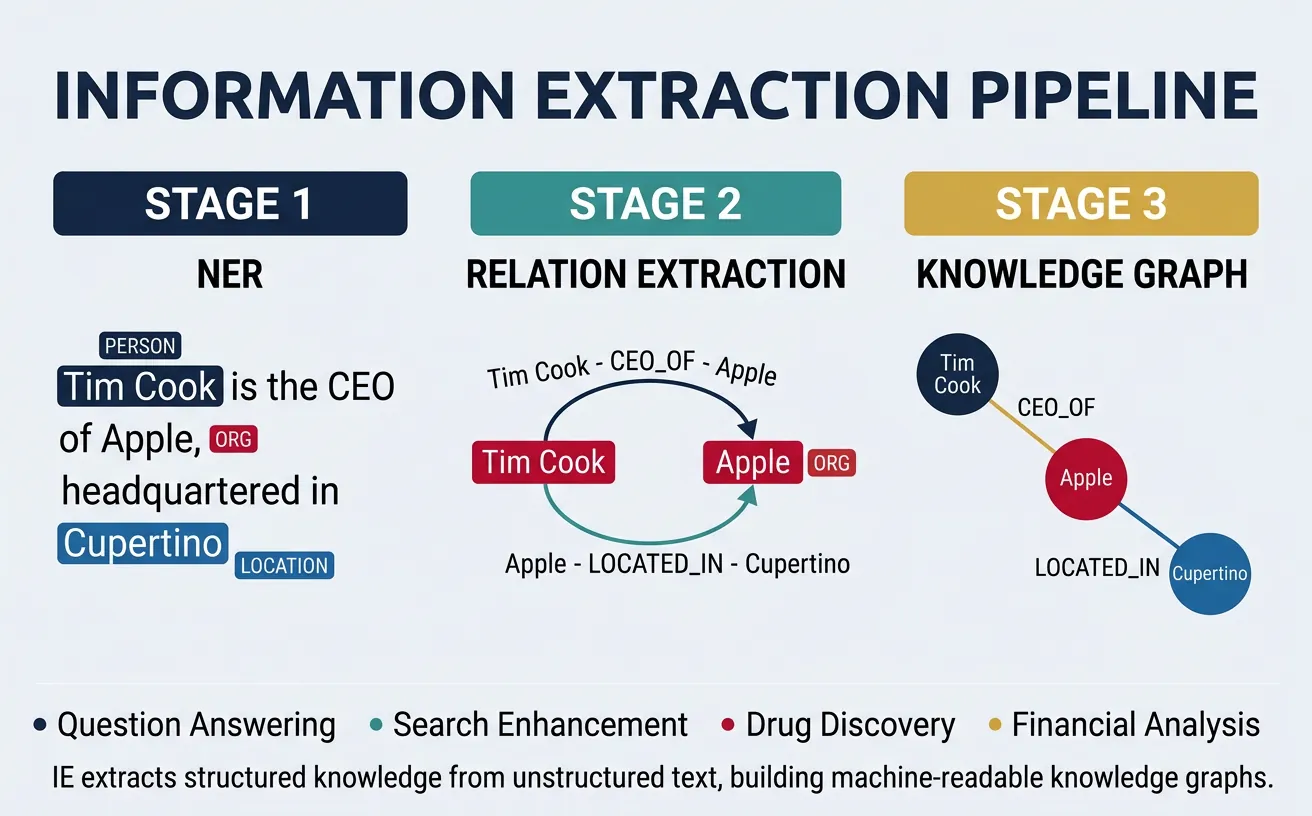
# Named Entity Recognition with spaCy
import spacy
# Load English model
nlp = spacy.load("en_core_web_sm")
text = """
Apple Inc. was founded by Steve Jobs, Steve Wozniak, and Ronald Wayne in
Cupertino, California on April 1, 1976. The company's first product was
the Apple I computer. Today, Apple is headquartered at Apple Park and
Tim Cook serves as CEO. In 2023, Apple's revenue exceeded $383 billion.
"""
# Process text
doc = nlp(text)
# Extract named entities
print("Named Entities Found:")
print("-" * 50)
for ent in doc.ents:
print(f"{ent.text:25} | {ent.label_:12} | {spacy.explain(ent.label_)}")
# Group by entity type
from collections import defaultdict
entities_by_type = defaultdict(list)
for ent in doc.ents:
entities_by_type[ent.label_].append(ent.text)
print("\nEntities Grouped by Type:")
for label, entities in entities_by_type.items():
print(f"{label}: {', '.join(set(entities))}")# Relation Extraction with Hugging Face
from transformers import pipeline
# Use question-answering for simple relation extraction
qa_pipeline = pipeline("question-answering", model="distilbert-base-cased-distilled-squad")
text = """
Elon Musk is the CEO of Tesla and SpaceX. He was born in Pretoria, South Africa
in 1971. Tesla is headquartered in Austin, Texas, and manufactures electric vehicles.
SpaceX, founded in 2002, is based in Hawthorne, California.
"""
# Define relation queries
relations = [
("Elon Musk", "position at Tesla", "What is Elon Musk's role at Tesla?"),
("Elon Musk", "birthplace", "Where was Elon Musk born?"),
("Tesla", "headquarters", "Where is Tesla headquartered?"),
("SpaceX", "founding year", "When was SpaceX founded?"),
("Tesla", "products", "What does Tesla manufacture?")
]
print("Extracted Relations:")
print("-" * 60)
for subject, relation, question in relations:
result = qa_pipeline(question=question, context=text)
print(f"({subject}, {relation}, {result['answer']})")
print(f" Confidence: {result['score']:.3f}\n")# Event Extraction - identifying events and arguments
import spacy
from collections import defaultdict
nlp = spacy.load("en_core_web_sm")
def extract_events(text):
"""
Simple event extraction based on verb phrases and their arguments.
"""
doc = nlp(text)
events = []
for sent in doc.sents:
for token in sent:
if token.pos_ == "VERB" and token.dep_ in ["ROOT", "conj"]:
event = {
"trigger": token.text,
"lemma": token.lemma_,
"arguments": defaultdict(list)
}
# Find subject
for child in token.children:
if child.dep_ in ["nsubj", "nsubjpass"]:
event["arguments"]["agent"].append(child.text)
elif child.dep_ in ["dobj", "pobj"]:
event["arguments"]["patient"].append(child.text)
elif child.dep_ == "prep":
for pobj in child.children:
if pobj.dep_ == "pobj":
event["arguments"][child.text].append(pobj.text)
events.append(event)
return events
text = """
Microsoft acquired Activision Blizzard for $68.7 billion in January 2022.
The deal was approved by regulators after extensive review.
CEO Satya Nadella announced the acquisition at a press conference.
"""
print("Extracted Events:")
print("-" * 50)
events = extract_events(text)
for i, event in enumerate(events, 1):
print(f"\nEvent {i}: {event['trigger']} ({event['lemma']})")
for role, fillers in event['arguments'].items():
print(f" {role}: {', '.join(fillers)}")Semantic Similarity
Semantic similarity measures how similar two pieces of text are in meaning, regardless of lexical overlap. This task underpins duplicate detection, plagiarism checking, semantic search, and paraphrase identification. Unlike simple word matching, semantic similarity must understand that "The dog chased the cat" and "A feline was pursued by a canine" have similar meanings despite sharing no common words.
Modern approaches use sentence embeddings—dense vector representations where semantically similar sentences are close in vector space. Models like Sentence-BERT (SBERT) and Universal Sentence Encoder map sentences to fixed-size vectors, enabling efficient similarity computation via cosine distance. These embeddings power semantic search, where queries retrieve conceptually related documents rather than just keyword matches.
# Semantic Similarity with Sentence Transformers
from sentence_transformers import SentenceTransformer, util
# Load pre-trained model
model = SentenceTransformer('all-MiniLM-L6-v2')
# Sentence pairs to compare
sentence_pairs = [
("The cat sits on the mat", "A feline is resting on a rug"),
("The cat sits on the mat", "The dog runs in the park"),
("I love machine learning", "Machine learning is my passion"),
("The weather is nice today", "It's a beautiful sunny day"),
("The weather is nice today", "Stock prices are rising")
]
print("Semantic Similarity Scores:")
print("-" * 60)
for sent1, sent2 in sentence_pairs:
# Compute embeddings
embedding1 = model.encode(sent1, convert_to_tensor=True)
embedding2 = model.encode(sent2, convert_to_tensor=True)
# Compute cosine similarity
similarity = util.cos_sim(embedding1, embedding2).item()
print(f"\nSentence 1: '{sent1}'")
print(f"Sentence 2: '{sent2}'")
print(f"Similarity: {similarity:.4f}")# Semantic Search with embeddings
from sentence_transformers import SentenceTransformer, util
import numpy as np
model = SentenceTransformer('all-MiniLM-L6-v2')
# Document corpus
documents = [
"Machine learning is a subset of artificial intelligence.",
"Deep learning uses neural networks with many layers.",
"Natural language processing enables computers to understand text.",
"Computer vision allows machines to interpret images.",
"Reinforcement learning trains agents through rewards.",
"Transfer learning applies knowledge from one task to another.",
"Python is a popular programming language for data science.",
"The stock market experienced volatility today."
]
# Encode all documents
doc_embeddings = model.encode(documents, convert_to_tensor=True)
def semantic_search(query, top_k=3):
"""Find most similar documents to query."""
query_embedding = model.encode(query, convert_to_tensor=True)
# Compute similarities
similarities = util.cos_sim(query_embedding, doc_embeddings)[0]
# Get top-k results
top_results = similarities.topk(k=top_k)
print(f"Query: '{query}'\n")
print("Top Results:")
for score, idx in zip(top_results.values, top_results.indices):
print(f" [{score:.4f}] {documents[idx]}")
print()
# Test queries
semantic_search("How do machines learn from data?")
semantic_search("Understanding human language with computers")
semantic_search("Training AI with trial and error")Coreference Resolution
Coreference resolution identifies when different expressions in text refer to the same entity. For example, in "John went to the store. He bought milk," the system must recognize that "He" refers to "John." This task is essential for text understanding, summarization, and question answering, where resolving pronouns and nominal references is crucial for accurate interpretation.
Coreference involves identifying mentions (noun phrases, pronouns) and grouping them into coreference chains (clusters referring to the same entity). Challenges include handling complex anaphora, cataphora (forward references), and distinguishing between entities with similar descriptions. Neural models use attention mechanisms to learn which mentions should be linked based on context.
# Coreference Resolution with spaCy and neuralcoref
# Note: For newer spaCy versions, use the coreferee extension
import spacy
# Method 1: Using spacy-experimental coref
# pip install spacy-experimental
try:
nlp = spacy.load("en_coreference_web_trf")
text = """
John went to the store because he needed groceries.
The store was crowded, but he found everything he needed.
His wife Mary was happy when he returned home.
She had been waiting for him all afternoon.
"""
doc = nlp(text)
print("Coreference chains found with transformer model")
except OSError:
print("Coreference model not installed")
print("Install with: python -m spacy download en_coreference_web_trf")
# Method 2: Simple pronoun resolution heuristic
nlp = spacy.load("en_core_web_sm")
def simple_coref_resolution(text):
"""
Simple rule-based pronoun resolution.
Links pronouns to most recent compatible noun.
"""
doc = nlp(text)
# Track potential antecedents
antecedents = []
resolutions = []
for token in doc:
# If it's a noun, add as potential antecedent
if token.pos_ in ["NOUN", "PROPN"]:
antecedents.append({
"text": token.text,
"pos": token.i,
"gender": None # Would need more sophisticated detection
})
# If it's a pronoun, try to resolve
elif token.pos_ == "PRON" and token.text.lower() in ["he", "she", "it", "they", "him", "her"]:
if antecedents:
# Simple heuristic: use most recent antecedent
antecedent = antecedents[-1]
resolutions.append({
"pronoun": token.text,
"position": token.i,
"resolved_to": antecedent["text"]
})
return resolutions
text = "John went to the store. He bought milk. The milk was fresh."
resolutions = simple_coref_resolution(text)
print("\nSimple Coreference Resolution:")
print("-" * 40)
for res in resolutions:
print(f"'{res['pronoun']}' → '{res['resolved_to']}'")Practical Implementation
Building production NLP systems requires combining multiple capabilities into coherent pipelines. A document understanding system might use NER to extract entities, relation extraction to find connections, summarization to create abstracts, and QA to enable natural language queries. The key is designing modular, testable components that can be composed for different use cases.
Performance considerations include latency (response time for real-time applications), throughput (documents processed per second for batch jobs), and accuracy (task-specific metrics). Trade-offs often exist—larger models are more accurate but slower. Techniques like model distillation, quantization, and caching help optimize production systems.
Building a Document Intelligence Pipeline
A complete document intelligence system combines: 1) Document ingestion and preprocessing, 2) Entity extraction and normalization, 3) Relation extraction and knowledge graph construction, 4) Summarization for document abstracts, 5) QA interface for natural language queries, 6) Semantic search for document retrieval.
# Complete NLP Pipeline for Document Analysis
from transformers import pipeline
import spacy
class DocumentAnalyzer:
"""
Comprehensive NLP pipeline for document analysis.
Combines multiple NLP tasks into a unified interface.
"""
def __init__(self):
# Load models
print("Loading models...")
self.nlp = spacy.load("en_core_web_sm")
self.summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
self.qa_model = pipeline("question-answering", model="distilbert-base-cased-distilled-squad")
self.classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
print("Models loaded!")
def extract_entities(self, text):
"""Extract named entities from text."""
doc = self.nlp(text)
entities = []
for ent in doc.ents:
entities.append({
"text": ent.text,
"label": ent.label_,
"start": ent.start_char,
"end": ent.end_char
})
return entities
def summarize(self, text, max_length=130):
"""Generate abstractive summary."""
if len(text.split()) < 50:
return text
result = self.summarizer(text, max_length=max_length, min_length=30, do_sample=False)
return result[0]['summary_text']
def answer_question(self, context, question):
"""Answer question based on context."""
result = self.qa_model(question=question, context=context)
return {
"answer": result['answer'],
"confidence": result['score']
}
def classify_topic(self, text, topics):
"""Classify text into predefined topics."""
result = self.classifier(text, topics)
return {
"topic": result['labels'][0],
"confidence": result['scores'][0]
}
def analyze(self, document):
"""Perform comprehensive document analysis."""
return {
"entities": self.extract_entities(document),
"summary": self.summarize(document),
"word_count": len(document.split()),
"sentence_count": len(list(self.nlp(document).sents))
}
# Example usage
analyzer = DocumentAnalyzer()
document = """
Apple Inc. announced its quarterly earnings today, reporting revenue of $89.5 billion.
CEO Tim Cook highlighted strong iPhone sales in China and growing services revenue.
The company also announced a new $90 billion stock buyback program.
Apple's stock rose 3% in after-hours trading following the announcement.
Analysts had expected revenue of $88 billion, making this a beat on expectations.
"""
# Full analysis
print("Document Analysis Results:")
print("=" * 50)
analysis = analyzer.analyze(document)
print(f"\nWord count: {analysis['word_count']}")
print(f"Sentence count: {analysis['sentence_count']}")
print(f"\nSummary:\n{analysis['summary']}")
print("\nEntities found:")
for ent in analysis['entities']:
print(f" {ent['text']} ({ent['label']})")
# Answer questions
print("\nQuestion Answering:")
questions = [
"What was Apple's revenue?",
"Who is the CEO?",
"How much is the stock buyback?"
]
for q in questions:
answer = analyzer.answer_question(document, q)
print(f" Q: {q}")
print(f" A: {answer['answer']} (confidence: {answer['confidence']:.3f})")# Batch processing with progress tracking
from transformers import pipeline
from tqdm import tqdm
import time
def batch_summarize(documents, batch_size=4):
"""
Efficiently summarize multiple documents with batching.
"""
summarizer = pipeline(
"summarization",
model="facebook/bart-large-cnn",
device=-1 # CPU, use device=0 for GPU
)
summaries = []
# Process in batches
for i in tqdm(range(0, len(documents), batch_size), desc="Summarizing"):
batch = documents[i:i + batch_size]
batch_summaries = summarizer(
batch,
max_length=100,
min_length=20,
do_sample=False,
truncation=True
)
summaries.extend([s['summary_text'] for s in batch_summaries])
return summaries
# Sample documents
sample_docs = [
"Machine learning is transforming industries. Companies use ML for predictions and automation.",
"Climate change poses significant risks. Scientists urge immediate action on emissions.",
"The stock market reached new highs. Investors remain optimistic about economic growth.",
"New smartphone features include AI cameras. Battery life has improved significantly."
]
# Process batch
start = time.time()
results = batch_summarize(sample_docs)
elapsed = time.time() - start
print(f"\nProcessed {len(sample_docs)} documents in {elapsed:.2f} seconds")
print(f"Average: {elapsed/len(sample_docs):.2f} seconds per document\n")
for i, (doc, summary) in enumerate(zip(sample_docs, results)):
print(f"Doc {i+1}: {doc[:50]}...")
print(f"Summary: {summary}\n")Conclusion & Next Steps
This guide covered the major advanced NLP tasks that power modern AI applications: Question Answering (extractive and generative), Text Summarization (extractive and abstractive), Machine Translation, Dialogue Systems, Information Extraction, Semantic Similarity, and Coreference Resolution. Each task builds on foundational NLP concepts and transformer architectures to solve real-world language understanding challenges.
Key takeaways include: extractive approaches offer interpretability and factual grounding; generative approaches provide flexibility and fluency; retrieval-augmented methods combine the best of both worlds. Modern Hugging Face pipelines make these capabilities accessible with just a few lines of code, while understanding the underlying principles helps you choose the right approach for your specific use case.
Next Steps in Your NLP Journey
Continue to Part 13: Multilingual & Cross-lingual NLP to learn how to build systems that work across languages—essential for global applications. You'll explore multilingual models like mBERT and XLM-R, cross-lingual transfer learning, and techniques for low-resource languages. For production deployment, Part 15 covers optimization, scaling, and MLOps for NLP systems.
Practice Exercises
- Build a QA System: Create a QA bot for a specific domain (e.g., FAQ database) combining retrieval and extraction.
- News Summarizer: Build a pipeline that fetches news articles and generates summaries with key entities highlighted.
- Translation Evaluation: Compare multiple translation models on the same text and evaluate with BLEU scores.
- Knowledge Graph: Extract entities and relations from Wikipedia articles to build a small knowledge graph.
- Chatbot: Implement a task-oriented chatbot for a specific domain (restaurant booking, tech support).