Introduction to Cutting-Edge NLP
The NLP landscape evolves rapidly, with breakthroughs in large language models, multimodal understanding, and reasoning capabilities. This final guide surveys the frontier of NLP research and emerging directions.
Key Insight
Modern NLP research increasingly focuses on capabilities that emerge at scale—reasoning, instruction-following, and multimodal understanding—while addressing challenges of alignment, efficiency, and responsible deployment.
NLP Mastery
NLP Fundamentals & Linguistic Basics
Phonology, morphology, syntax, semantics, pragmaticsTokenization & Text Cleaning
Subword tokenization, BPE, stopwords, normalizationText Representation & Feature Engineering
Bag-of-words, TF-IDF, feature extraction, vectorizationWord Embeddings
Word2Vec, GloVe, FastText, embedding spaces, analogiesStatistical Language Models & N-grams
Probability chains, smoothing, perplexity, Markov modelsNeural Networks for NLP
Feedforward nets, backpropagation, activation functionsRNNs, LSTMs & GRUs
Sequence modeling, vanishing gradients, gated architecturesTransformers & Attention Mechanism
Self-attention, multi-head attention, positional encodingPretrained Language Models & Transfer Learning
BERT, RoBERTa, fine-tuning, feature extractionGPT Models & Text Generation
Autoregressive generation, prompting, GPT architectureCore NLP Tasks
NER, POS tagging, sentiment analysis, text classificationAdvanced NLP Tasks
Question answering, summarization, machine translationMultilingual & Cross-lingual NLP
mBERT, XLM-R, zero-shot transfer, language diversityEvaluation, Ethics & Responsible NLP
BLEU, ROUGE, bias detection, fairness, responsible AINLP Systems, Optimization & Production
Model serving, quantization, distillation, deploymentCutting-Edge & Research Topics
LLMs, multimodal NLP, reasoning, emerging researchLarge Language Models
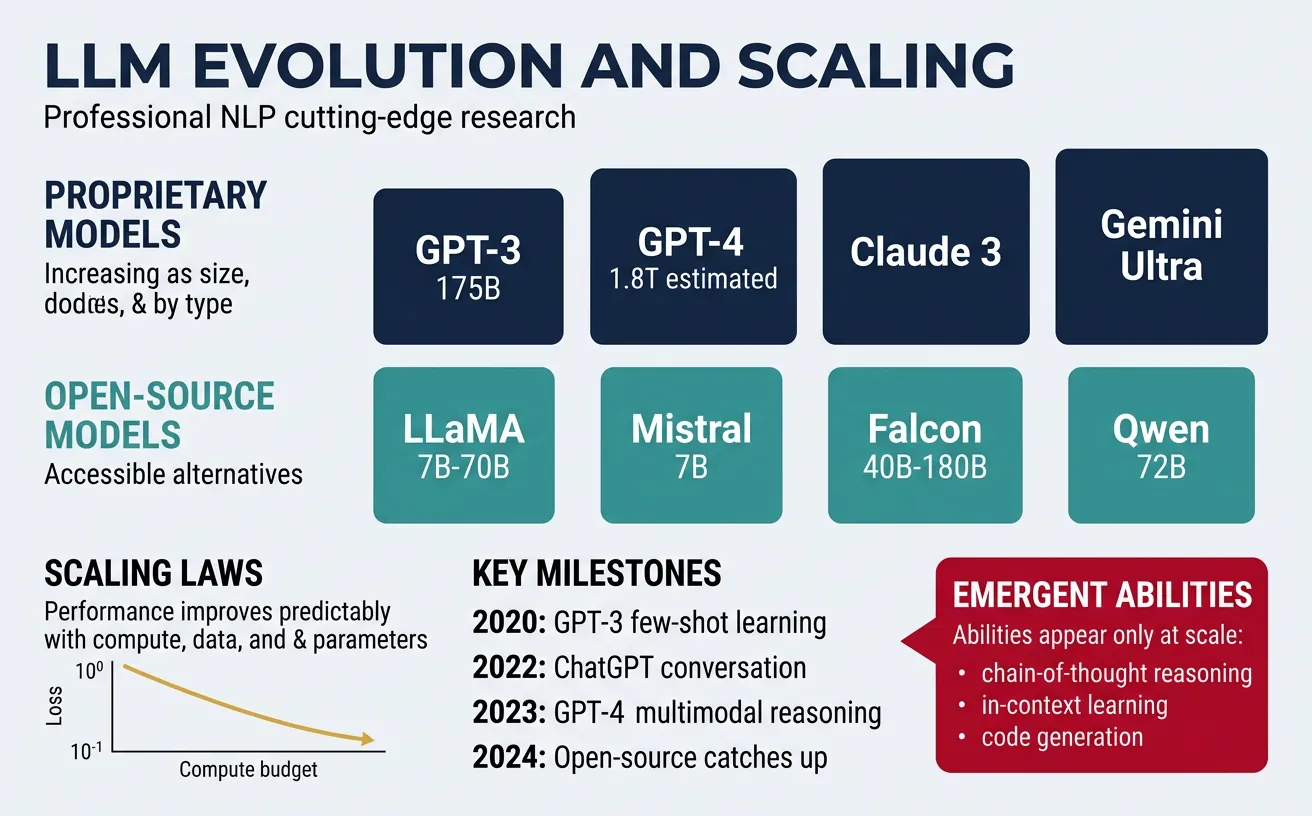
Large Language Models (LLMs) represent a paradigm shift in artificial intelligence, demonstrating that scaling model parameters, training data, and compute leads to qualitatively different capabilities. From GPT-3's 175 billion parameters to more recent models with trillions of parameters, the field has discovered that "more is different"—capabilities emerge that weren't explicitly programmed or even predicted.
The modern LLM landscape includes both proprietary models (GPT-4, Claude, Gemini) and open-source alternatives (LLaMA, Mistral, Falcon). These models have fundamentally changed how we approach NLP tasks, shifting from task-specific fine-tuning to prompting general-purpose models. Understanding the principles behind LLMs—scaling laws, architecture choices, and training methodologies—is essential for anyone working in modern NLP.
LLM Landscape Overview
| Model Family | Organization | Parameters | Key Features |
|---|---|---|---|
| GPT-4/4o | OpenAI | ~1.8T (estimated) | Multimodal, strong reasoning |
| Claude 3 | Anthropic | ~137B-1T | Constitutional AI, long context |
| Gemini | ~1T+ | Native multimodal, code execution | |
| LLaMA 3 | Meta | 8B-405B | Open weights, efficient |
| Mistral/Mixtral | Mistral AI | 7B-46.7B | MoE architecture, open |
Scaling Laws
Scaling laws, first systematically studied by OpenAI (Kaplan et al., 2020) and later refined by DeepMind (Hoffmann et al., 2022), describe how model performance improves predictably with increases in model parameters, training data, and compute. The original "Kaplan scaling laws" suggested that model size should scale faster than dataset size, leading to increasingly large models trained on relatively fixed datasets.
DeepMind's "Chinchilla" paper revised these findings, demonstrating that models were significantly undertrained—optimal scaling should increase parameters and training tokens roughly equally. This "compute-optimal" approach led to more efficient models: Chinchilla, with 70B parameters trained on 1.4T tokens, outperformed the 280B parameter Gopher trained on fewer tokens. These insights now guide modern LLM development.
# Understanding Scaling Laws - Loss Prediction
import numpy as np
import matplotlib.pyplot as plt
# Scaling law: L(N, D) ˜ A/N^a + B/D^ß + E
# where N = parameters, D = data tokens, L = loss
def kaplan_scaling_loss(params_billions, tokens_billions):
"""Approximate Kaplan scaling law for loss prediction."""
# Empirical constants (simplified from paper)
A = 0.076 # Parameter efficiency
B = 0.103 # Data efficiency
alpha = 0.076 # Parameter exponent
beta = 0.095 # Data exponent
E = 1.69 # Irreducible entropy
N = params_billions * 1e9
D = tokens_billions * 1e9
loss = (A / (N ** alpha)) + (B / (D ** beta)) + E
return loss
# Compare different model configurations
configs = [
("1.5B params, 300B tokens", 1.5, 300),
("7B params, 1T tokens", 7, 1000),
("70B params, 1.4T tokens", 70, 1400), # Chinchilla-optimal
("175B params, 300B tokens", 175, 300), # GPT-3 style
("405B params, 15T tokens", 405, 15000), # LLaMA 3.1 405B
]
print("Scaling Law Loss Predictions:")
print("=" * 50)
for name, params, tokens in configs:
loss = kaplan_scaling_loss(params, tokens)
print(f"{name:30s} -> Predicted Loss: {loss:.4f}")
# Compute-optimal frontier: roughly equal scaling
print("\nCompute-Optimal Analysis (Chinchilla):")
for compute_budget in [1e22, 1e23, 1e24, 1e25]:
# Optimal allocation: ~1.4 tokens per parameter
optimal_params = (compute_budget / 6) ** 0.5 / 1e9
optimal_tokens = optimal_params * 20 # ~20 tokens per param for optimal
print(f"Budget {compute_budget:.0e} FLOPs -> ~{optimal_params:.1f}B params, {optimal_tokens:.0f}B tokens")Chinchilla Scaling Laws
Key insight from the Chinchilla paper: For a given compute budget, model size and training data should scale roughly equally. A 70B model trained on 1.4T tokens outperforms a 280B model trained on 300B tokens, despite using the same compute. This revolutionized how organizations think about training efficiency.
Emergent Abilities
Emergent abilities are capabilities that appear suddenly as models scale, rather than improving gradually. These abilities—such as arithmetic, multi-step reasoning, and following complex instructions—seem absent in smaller models but appear abruptly once a certain scale threshold is crossed. This phenomenon, documented by Wei et al. (2022), suggests that LLMs undergo qualitative transitions, not just quantitative improvements.
Examples of emergent abilities include: solving math word problems (emerging around 10B parameters), performing multi-step logical reasoning, in-context learning with few examples, code generation from natural language descriptions, and cross-lingual transfer without explicit multilingual training. Recent research debates whether emergence is truly discontinuous or if it appears sudden due to evaluation metrics that have sharp thresholds.
# Demonstrating Emergent Abilities: Few-Shot Learning
import json
def create_few_shot_prompt(task, examples, test_input):
"""Create a few-shot prompt for demonstrating in-context learning."""
prompt_parts = [f"Task: {task}\n\nExamples:\n"]
for i, (inp, out) in enumerate(examples, 1):
prompt_parts.append(f"Input: {inp}")
prompt_parts.append(f"Output: {out}\n")
prompt_parts.append(f"Input: {test_input}")
prompt_parts.append("Output:")
return "\n".join(prompt_parts)
# Example 1: Arithmetic (emergent at ~10B params)
arithmetic_examples = [
("What is 23 + 47?", "70"),
("What is 156 - 89?", "67"),
("What is 12 * 8?", "96"),
]
arithmetic_prompt = create_few_shot_prompt(
"Solve arithmetic problems",
arithmetic_examples,
"What is 234 + 567?"
)
print("Few-Shot Arithmetic Prompt:")
print(arithmetic_prompt)
print("\n" + "="*50 + "\n")
# Example 2: Chain-of-thought reasoning (emergent at ~100B params)
cot_examples = [
("If John has 3 apples and buys 2 more, then gives half to Mary, how many does he have?",
"Let's think step by step. John starts with 3 apples. He buys 2 more: 3 + 2 = 5. He gives half to Mary: 5 / 2 = 2.5. Since we can't have half an apple, he gives 2 to Mary and keeps 3. Answer: 3"),
]
cot_prompt = create_few_shot_prompt(
"Solve word problems step by step",
cot_examples,
"A store has 45 books. If they sell 1/3 of them and then receive a shipment of 20 more, how many books do they have?"
)
print("Chain-of-Thought Prompt:")
print(cot_prompt)Emergent Abilities by Scale
| Capability | Emergence Scale | Description |
|---|---|---|
| Basic Few-Shot | ~1B params | Learning simple patterns from examples |
| Arithmetic | ~10B params | Multi-digit addition, subtraction |
| Word Problems | ~50B params | Simple multi-step reasoning |
| Chain-of-Thought | ~100B params | Explicit reasoning chains |
| Instruction Following | ~50-100B params | Zero-shot task execution |
| Complex Reasoning | ~500B+ params | Multi-hop, abstract reasoning |
Architecture Innovations
Modern LLM architectures have evolved significantly from the original Transformer. Key innovations include: Rotary Position Embeddings (RoPE) for better length generalization, Grouped Query Attention (GQA) for memory efficiency, Flash Attention for computational speedups, and Mixture of Experts (MoE) for scaling without proportional compute costs. These advances enable longer context windows (128K+ tokens) and more efficient inference.
The Mixture of Experts architecture, popularized by Mixtral, activates only a subset of parameters for each token, allowing models to scale to trillions of parameters while maintaining reasonable inference costs. Meanwhile, innovations like sliding window attention (Mistral) and multi-head latent attention (DeepSeek) continue to push efficiency boundaries. Understanding these architectural choices is crucial for selecting and deploying models effectively.
# Modern LLM Architecture Components
import numpy as np
# 1. Rotary Position Embeddings (RoPE)
def compute_rope_frequencies(dim, seq_len, base=10000):
"""Compute rotary position embedding frequencies."""
# Frequencies: theta_i = base^(-2i/dim)
frequencies = 1.0 / (base ** (np.arange(0, dim, 2) / dim))
positions = np.arange(seq_len)
# Outer product: position × frequency
angles = np.outer(positions, frequencies)
return np.cos(angles), np.sin(angles)
def apply_rope(query, key, cos, sin):
"""Apply RoPE to query and key (simplified)."""
# Rotate pairs of dimensions
q_rot = query * cos - np.roll(query, 1, axis=-1) * sin
k_rot = key * cos - np.roll(key, 1, axis=-1) * sin
return q_rot, k_rot
print("RoPE Frequencies (dim=64, seq_len=5):")
cos_freq, sin_freq = compute_rope_frequencies(64, 5)
print(f"Cos shape: {cos_freq.shape}, Sin shape: {sin_freq.shape}")
print(f"First position frequencies: {cos_freq[0, :4]}")
print("\n" + "="*50 + "\n")
# 2. Grouped Query Attention (GQA)
def gqa_memory_comparison(num_layers, hidden_dim, num_heads, seq_len, batch_size=1):
"""Compare memory usage: MHA vs GQA vs MQA."""
head_dim = hidden_dim // num_heads
# Multi-Head Attention: each head has its own K, V
mha_kv_memory = 2 * num_layers * num_heads * seq_len * head_dim * batch_size
# Grouped Query Attention: share K, V across groups
num_kv_heads = num_heads // 8 # Typical: 8x fewer KV heads
gqa_kv_memory = 2 * num_layers * num_kv_heads * seq_len * head_dim * batch_size
# Multi-Query Attention: single K, V for all heads
mqa_kv_memory = 2 * num_layers * 1 * seq_len * head_dim * batch_size
return {
'MHA': mha_kv_memory,
'GQA': gqa_kv_memory,
'MQA': mqa_kv_memory
}
# Example: LLaMA 2 70B-style configuration
memory = gqa_memory_comparison(
num_layers=80, hidden_dim=8192,
num_heads=64, seq_len=4096
)
print("KV Cache Memory Comparison (70B-style model, 4K context):")
for method, mem in memory.items():
print(f" {method}: {mem / (1024**3):.2f} GB")
print("\n" + "="*50 + "\n")
# 3. Mixture of Experts (MoE)
def moe_computation(total_params, num_experts, top_k, input_size):
"""Simulate MoE forward pass computation."""
expert_params = total_params / num_experts
# Only top_k experts are activated per token
active_params = expert_params * top_k + (total_params * 0.3) # Shared params
dense_flops = total_params * input_size * 2
moe_flops = active_params * input_size * 2
return {
'total_params': total_params,
'active_params': active_params,
'dense_flops': dense_flops,
'moe_flops': moe_flops,
'speedup': dense_flops / moe_flops
}
# Mixtral 8x7B configuration
moe_stats = moe_computation(
total_params=46.7e9, num_experts=8,
top_k=2, input_size=4096
)
print("Mixture of Experts (Mixtral 8x7B):")
print(f" Total parameters: {moe_stats['total_params']/1e9:.1f}B")
print(f" Active per token: {moe_stats['active_params']/1e9:.1f}B")
print(f" Effective speedup: {moe_stats['speedup']:.2f}x vs dense model")Reasoning & Chain-of-Thought
Chain-of-Thought (CoT) prompting, introduced by Wei et al. (2022), represents one of the most significant prompt engineering discoveries. By instructing models to "think step by step" or providing examples that demonstrate intermediate reasoning, LLMs achieve dramatically better performance on complex reasoning tasks. This technique unlocks reasoning capabilities that appear absent when using direct question-answering prompts.
CoT has evolved into numerous variants: Zero-Shot CoT (simply adding "Let's think step by step"), Self-Consistency (sampling multiple reasoning paths and taking majority vote), Tree of Thoughts (exploring multiple reasoning branches), and ReAct (interleaving reasoning with actions). These techniques have become essential for complex tasks like math problem solving, logical deduction, and multi-step planning.

# Chain-of-Thought Prompting Techniques
def standard_prompt(question):
"""Standard direct prompting (no CoT)."""
return f"""Question: {question}
Answer:"""
def zero_shot_cot(question):
"""Zero-shot Chain-of-Thought - add magic phrase."""
return f"""Question: {question}
Let's think step by step:"""
def few_shot_cot(question):
"""Few-shot CoT with reasoning examples."""
return f"""I'll solve math word problems by thinking step by step.
Q: There are 15 trees in the grove. Grove workers will plant trees
today. After they are done, there will be 21 trees. How many trees
did the workers plant today?
A: Let's think step by step.
- We start with 15 trees
- After planting, we have 21 trees
- Trees planted = 21 - 15 = 6
The answer is 6.
Q: If there are 3 cars in the parking lot and 2 more cars arrive,
how many cars are in the parking lot?
A: Let's think step by step.
- We start with 3 cars
- 2 more cars arrive
- Total cars = 3 + 2 = 5
The answer is 5.
Q: {question}
A: Let's think step by step."""
# Test question
test_question = """A farmer has 24 chickens. She buys 8 more chickens,
then sells 1/4 of all her chickens. How many chickens does she have left?"""
print("=" * 60)
print("STANDARD PROMPT (No CoT):")
print("=" * 60)
print(standard_prompt(test_question))
print("\n" + "=" * 60)
print("ZERO-SHOT CHAIN-OF-THOUGHT:")
print("=" * 60)
print(zero_shot_cot(test_question))
print("\n" + "=" * 60)
print("FEW-SHOT CHAIN-OF-THOUGHT:")
print("=" * 60)
print(few_shot_cot(test_question))CoT Performance Gains
Chain-of-Thought prompting can improve accuracy by 50%+ on complex reasoning tasks. On the GSM8K math benchmark, CoT improved GPT-3 from ~18% to ~58% accuracy. The gains are particularly dramatic for tasks requiring multi-step reasoning, symbolic manipulation, or careful logical deduction.
# Self-Consistency: Multiple Reasoning Paths
import random
from collections import Counter
def simulate_self_consistency(question, num_samples=5):
"""Simulate self-consistency with diverse reasoning paths."""
# Simulated model responses (in practice, these come from the LLM)
# Each represents a different reasoning path that might arrive at an answer
simulated_paths = [
{"reasoning": "24 + 8 = 32 chickens. 32 × 1/4 = 8 sold. 32 - 8 = 24", "answer": 24},
{"reasoning": "Start: 24. Buy 8: 32. Sell quarter: 32/4 = 8. Left: 24", "answer": 24},
{"reasoning": "24 + 8 = 32. 1/4 of 32 = 8. 32 - 8 = 24 remaining", "answer": 24},
{"reasoning": "Total = 24+8=32. Sells 32÷4=8. Keeps 32-8=24", "answer": 24},
{"reasoning": "24+8=32 total. Sold 25%=8. Has 32-8=24", "answer": 24},
# Occasional errors (realistic)
{"reasoning": "24 chickens, sell 1/4 = 6, buy 8 = 26", "answer": 26}, # Wrong order
{"reasoning": "24 + 8 = 32. 32/4 = 8 kept", "answer": 8}, # Misread
]
# Sample responses (simulating temperature sampling)
samples = random.choices(simulated_paths, k=num_samples)
answers = [s["answer"] for s in samples]
# Majority voting
vote_counts = Counter(answers)
final_answer = vote_counts.most_common(1)[0][0]
print(f"Question: {question[:50]}...\n")
print("Sampled Reasoning Paths:")
for i, sample in enumerate(samples, 1):
print(f" Path {i}: {sample['reasoning'][:50]}... -> {sample['answer']}")
print(f"\nVote Distribution: {dict(vote_counts)}")
print(f"Final Answer (majority): {final_answer}")
return final_answer
question = "A farmer has 24 chickens, buys 8 more, then sells 1/4. How many left?"
random.seed(42)
result = simulate_self_consistency(question, num_samples=5)# ReAct: Reasoning and Acting
def create_react_prompt(question, tools_description):
"""Create a ReAct-style prompt combining reasoning and tool use."""
return f"""You have access to the following tools:
{tools_description}
Use the following format:
Question: the input question you must answer
Thought: think about what to do
Action: the action to take (tool name)
Action Input: the input to the tool
Observation: the result of the action
... (repeat Thought/Action/Observation as needed)
Thought: I now know the final answer
Final Answer: the final answer to the question
Question: {question}
Thought:"""
# Example ReAct interaction
tools = """
1. search[query]: Search for information about a topic
2. calculate[expression]: Evaluate a mathematical expression
3. lookup[term]: Look up a specific term or definition
"""
react_prompt = create_react_prompt(
"What is the population of France divided by the population of Belgium?",
tools
)
print("ReAct Prompt Structure:")
print("=" * 60)
print(react_prompt)
# Simulated ReAct execution trace
print("\n" + "=" * 60)
print("Simulated ReAct Execution:")
print("=" * 60)
react_trace = """
Thought: I need to find the populations of France and Belgium, then divide them.
Action: search[population of France]
Action Input: population of France
Observation: France has a population of approximately 67.75 million (2024)
Thought: Now I need the population of Belgium
Action: search[population of Belgium]
Action Input: population of Belgium
Observation: Belgium has a population of approximately 11.6 million (2024)
Thought: Now I can calculate the ratio
Action: calculate[67.75 / 11.6]
Action Input: 67.75 / 11.6
Observation: 5.84
Thought: I now know the final answer
Final Answer: France's population is about 5.84 times that of Belgium's.
"""
print(react_trace)Tree of Thoughts (ToT)
Tree of Thoughts extends CoT by exploring multiple reasoning branches using search algorithms (BFS/DFS). At each step, the model generates several possible "thoughts" and evaluates which are most promising. This is particularly effective for tasks requiring exploration and backtracking, like puzzle solving or creative writing.
Process: Generate thoughts ? Evaluate states ? Select promising paths ? Backtrack if needed ? Continue until solution found
Multimodal Models
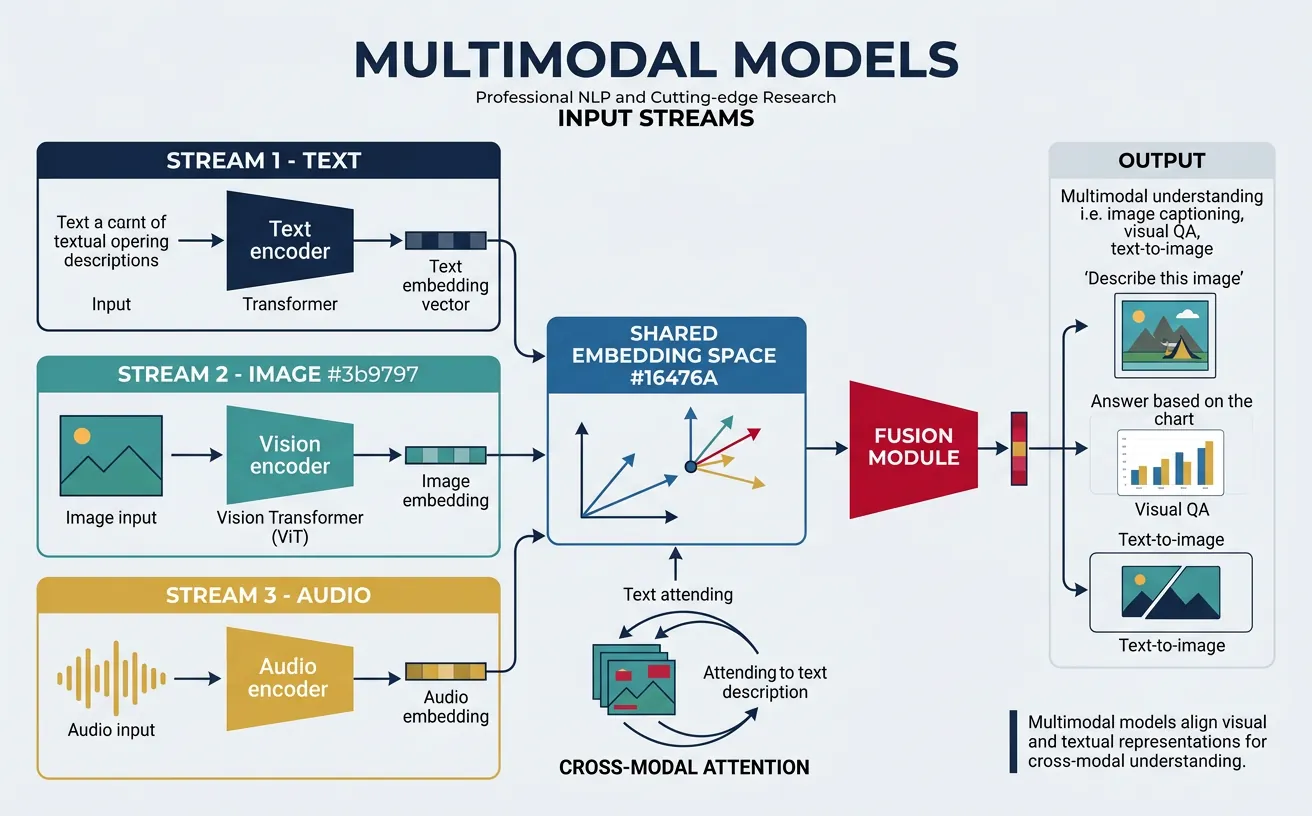
Multimodal NLP extends language models to understand and generate content across modalities—text, images, audio, and video. Pioneered by models like CLIP (Contrastive Language-Image Pre-training) and DALL-E, the field has progressed to unified architectures like GPT-4V, Gemini, and Claude 3 that natively process multiple modalities. These models can describe images, answer visual questions, generate images from text, and reason across modalities.
The core insight behind multimodal learning is that vision and language share common semantic structures. By aligning visual and textual representations in a shared embedding space, models learn rich cross-modal associations. This enables powerful applications: visual question answering, image captioning, text-to-image generation, document understanding, and video comprehension. Understanding multimodal architectures is increasingly essential as NLP expands beyond pure text.
# CLIP-style Contrastive Learning for Vision-Language
import numpy as np
class SimpleCLIP:
"""Simplified CLIP model demonstrating contrastive learning."""
def __init__(self, embed_dim=512):
self.embed_dim = embed_dim
# Simulated encoders (in practice, these are neural networks)
np.random.seed(42)
self.temperature = 0.07 # CLIP's learned temperature
def encode_image(self, image_features):
"""Project image features to shared embedding space."""
# Normalize to unit sphere
norm = np.linalg.norm(image_features)
return image_features / norm if norm > 0 else image_features
def encode_text(self, text_features):
"""Project text features to shared embedding space."""
norm = np.linalg.norm(text_features)
return text_features / norm if norm > 0 else text_features
def compute_similarity(self, image_embeds, text_embeds):
"""Compute cosine similarity matrix between images and texts."""
# image_embeds: (n_images, embed_dim)
# text_embeds: (n_texts, embed_dim)
similarity = np.dot(image_embeds, text_embeds.T)
return similarity / self.temperature
def contrastive_loss(self, image_embeds, text_embeds):
"""Compute symmetric contrastive loss (InfoNCE)."""
logits = self.compute_similarity(image_embeds, text_embeds)
n = logits.shape[0]
labels = np.arange(n) # Diagonal is positive pairs
# Image-to-text loss
i2t_probs = np.exp(logits) / np.exp(logits).sum(axis=1, keepdims=True)
i2t_loss = -np.log(i2t_probs[range(n), labels] + 1e-10).mean()
# Text-to-image loss
t2i_probs = np.exp(logits.T) / np.exp(logits.T).sum(axis=1, keepdims=True)
t2i_loss = -np.log(t2i_probs[range(n), labels] + 1e-10).mean()
return (i2t_loss + t2i_loss) / 2
# Demonstrate CLIP contrastive learning
clip = SimpleCLIP(embed_dim=64)
# Simulated batch of 4 image-text pairs
np.random.seed(42)
image_features = np.random.randn(4, 64) # 4 images
text_features = np.random.randn(4, 64) # 4 matching captions
# Make matching pairs more similar (simulating trained encoders)
for i in range(4):
text_features[i] = image_features[i] * 0.8 + np.random.randn(64) * 0.2
# Encode and normalize
image_embeds = np.array([clip.encode_image(img) for img in image_features])
text_embeds = np.array([clip.encode_text(txt) for txt in text_features])
# Compute similarity matrix
similarity_matrix = clip.compute_similarity(image_embeds, text_embeds)
print("CLIP Similarity Matrix (images × texts):")
print(f"Shape: {similarity_matrix.shape}")
print("\nSimilarity scores (higher = more similar):")
for i in range(4):
print(f" Image {i}: [{', '.join([f'{s:.2f}' for s in similarity_matrix[i]])}]")
print(f"\nDiagonal (matching pairs) should be highest:")
print(f" Diagonal values: {[f'{similarity_matrix[i,i]:.2f}' for i in range(4)]}")
loss = clip.contrastive_loss(image_embeds, text_embeds)
print(f"\nContrastive Loss: {loss:.4f}")Zero-Shot Image Classification with CLIP
CLIP's key innovation: By training on 400M image-text pairs from the internet, CLIP learns general visual concepts that transfer to any image classification task without fine-tuning. Simply embed class names as text ("a photo of a dog", "a photo of a cat") and find which text embedding best matches the image embedding.
# Vision-Language Applications
import numpy as np
def zero_shot_classification(image_embedding, class_names, text_encoder):
"""Zero-shot image classification using CLIP-style model."""
# Create prompts for each class
prompts = [f"a photo of a {name}" for name in class_names]
# Encode class prompts (simulated)
np.random.seed(42)
text_embeddings = []
for i, prompt in enumerate(prompts):
# Simulate different embeddings for different classes
embed = np.random.randn(512)
text_embeddings.append(embed / np.linalg.norm(embed))
text_embeddings = np.array(text_embeddings)
# Compute similarities
similarities = np.dot(text_embeddings, image_embedding)
# Convert to probabilities
probs = np.exp(similarities * 100) / np.exp(similarities * 100).sum()
return list(zip(class_names, probs))
# Example: classify an image
np.random.seed(123)
image_embed = np.random.randn(512)
image_embed = image_embed / np.linalg.norm(image_embed)
classes = ["dog", "cat", "bird", "fish", "horse"]
results = zero_shot_classification(image_embed, classes, None)
print("Zero-Shot Classification Results:")
print("=" * 40)
for class_name, prob in sorted(results, key=lambda x: -x[1]):
bar = "¦" * int(prob * 30)
print(f" {class_name:10s}: {prob:.2%} {bar}")
print("\n" + "=" * 40)
# Visual Question Answering Prompt Structure
def create_vqa_prompt(image_description, question):
"""Create a VQA prompt for multimodal models."""
return f"""{image_description}
Question: {question}
Please analyze the image and answer the question based on what you observe.
Answer:"""
vqa_prompt = create_vqa_prompt(
"A busy city street with people walking, cars, and storefronts",
"How many people are visible in the image?"
)
print("VQA Prompt Structure:")
print(vqa_prompt)# Multimodal Embeddings: Unified Representation
import numpy as np
class MultimodalEmbedder:
"""Unified embedding space for text, images, and audio."""
def __init__(self, embed_dim=768):
self.embed_dim = embed_dim
np.random.seed(42)
def embed_text(self, text):
"""Embed text into unified space."""
# Simulate text encoding (in practice: transformer encoder)
np.random.seed(hash(text) % 2**32)
embed = np.random.randn(self.embed_dim)
return embed / np.linalg.norm(embed)
def embed_image(self, image_path):
"""Embed image into unified space."""
# Simulate image encoding (in practice: ViT or CNN)
np.random.seed(hash(image_path) % 2**32)
embed = np.random.randn(self.embed_dim)
return embed / np.linalg.norm(embed)
def embed_audio(self, audio_path):
"""Embed audio into unified space."""
# Simulate audio encoding (in practice: Whisper-style encoder)
np.random.seed(hash(audio_path) % 2**32)
embed = np.random.randn(self.embed_dim)
return embed / np.linalg.norm(embed)
def cross_modal_similarity(self, embed1, embed2):
"""Compute similarity between any two modality embeddings."""
return np.dot(embed1, embed2)
def find_similar(self, query_embed, candidates, top_k=3):
"""Find most similar items across modalities."""
similarities = [(cand, np.dot(query_embed, cand['embed']))
for cand in candidates]
return sorted(similarities, key=lambda x: -x[1])[:top_k]
# Create multimodal database
embedder = MultimodalEmbedder(embed_dim=768)
database = [
{'type': 'text', 'content': 'A golden retriever playing fetch',
'embed': embedder.embed_text('A golden retriever playing fetch')},
{'type': 'image', 'content': 'dog_park.jpg',
'embed': embedder.embed_image('dog_park.jpg')},
{'type': 'text', 'content': 'Sunset over the ocean with sailboats',
'embed': embedder.embed_text('Sunset over the ocean with sailboats')},
{'type': 'audio', 'content': 'ocean_waves.mp3',
'embed': embedder.embed_audio('ocean_waves.mp3')},
{'type': 'image', 'content': 'beach_sunset.jpg',
'embed': embedder.embed_image('beach_sunset.jpg')},
]
# Cross-modal search: text query to find images/audio
query = embedder.embed_text("beach and ocean scenery")
results = embedder.find_similar(query, database, top_k=3)
print("Cross-Modal Search Results:")
print("Query: 'beach and ocean scenery' (text)")
print("=" * 50)
for item, score in results:
print(f" [{item['type']:6s}] {item['content']:40s} (sim: {score:.4f})")Vision-Language Model Architectures
| Architecture | Approach | Examples |
|---|---|---|
| Dual Encoder | Separate encoders, shared embedding space | CLIP, ALIGN |
| Fusion Encoder | Cross-attention between modalities | BLIP, Flamingo |
| Unified Decoder | Single autoregressive model for all modalities | GPT-4V, Gemini |
| Diffusion | Iterative denoising for generation | Stable Diffusion, DALL-E 3 |
Audio Models & Speech Generation
The multimodal frontier has expanded dramatically beyond vision-language pairs to include audio understanding and generation. Modern audio models can transcribe speech, generate natural-sounding voices, compose music, translate between languages in real time, and even understand environmental sounds — all within a single unified architecture.
The key enabling technology is the audio tokenizer — a neural codec that compresses raw audio waveforms into discrete tokens, just as BPE tokenizes text. Once audio is tokenized, the same transformer architecture used for text generation can produce high-quality speech, music, and sound effects.
| Model | Organization | Capability | Key Innovation |
|---|---|---|---|
| Whisper | OpenAI | Speech recognition (99+ languages) | Weakly supervised on 680K hours of web audio |
| EnCodec | Meta | Audio tokenization (codec) | Residual Vector Quantization (RVQ) for high-fidelity audio tokens |
| MusicGen | Meta | Text-to-music generation | Single-stage transformer over EnCodec tokens |
| VALL-E / VALL-E 2 | Microsoft | Zero-shot text-to-speech | 3-second voice cloning via codec language modeling |
| AudioPaLM | Speech-to-speech translation | Fuses PaLM text LLM with AudioLM speech model | |
| Gemini 2.0 | Native audio I/O in LLM | Audio as first-class modality — listen, speak, reason |
Audio Tokenization: The Bridge from Waveforms to Language Models
Why tokenize audio? Raw audio at CD quality is 44,100 samples/second × 16 bits = 705,600 bits/second. A 10-second clip has 441,000 float values — far too many for a transformer. Neural audio codecs like EnCodec and SoundStream compress this to ~50-75 tokens/second using Residual Vector Quantization (RVQ), making audio tractable for language-model-style generation. Each token captures ~20 ms of audio, analogous to how a BPE token captures a word fragment in text.
import numpy as np
import matplotlib.pyplot as plt
def demonstrate_audio_tokenization():
"""Demonstrate the concept of audio tokenization via
Residual Vector Quantization (RVQ) — the core of
EnCodec, SoundStream, and similar neural audio codecs.
"""
np.random.seed(42)
sr = 16000 # 16 kHz sample rate
duration = 0.1 # 100 ms of audio
t = np.linspace(0, duration, int(sr * duration), endpoint=False)
# Synthesize a simple audio signal (vowel-like)
signal = (0.6 * np.sin(2 * np.pi * 200 * t) + # fundamental
0.3 * np.sin(2 * np.pi * 400 * t) + # 2nd harmonic
0.1 * np.sin(2 * np.pi * 800 * t) + # 4th harmonic
0.05 * np.random.randn(len(t))) # noise
# --- Simulate RVQ: progressive residual quantization ---
codebook_size = 256 # tokens per quantizer level
n_quantizers = 4 # number of RVQ levels
frame_size = 320 # samples per frame (~20 ms at 16 kHz)
n_frames = len(signal) // frame_size
frames = signal[:n_frames * frame_size].reshape(n_frames, frame_size)
# Simple quantization: map each frame to nearest codebook entry
all_tokens = []
residual = frames.copy()
print("Residual Vector Quantization (RVQ) Demo")
print("=" * 55)
print(f"Input: {len(signal)} samples at {sr} Hz = {duration*1000:.0f} ms")
print(f"Frame size: {frame_size} samples ({frame_size/sr*1000:.0f} ms)")
print(f"Frames: {n_frames}, Codebook: {codebook_size} entries × {n_quantizers} levels\n")
for q in range(n_quantizers):
# Create random codebook (in practice, learned via VQ-VAE)
codebook = np.random.randn(codebook_size, frame_size) * (0.5 ** q)
tokens_q = []
new_residual = np.zeros_like(residual)
for i in range(n_frames):
# Find nearest codebook entry
distances = np.sum((codebook - residual[i]) ** 2, axis=1)
best_idx = np.argmin(distances)
tokens_q.append(best_idx)
new_residual[i] = residual[i] - codebook[best_idx]
quantization_error = np.mean(new_residual ** 2)
all_tokens.append(tokens_q)
residual = new_residual
print(f" Level {q+1}: tokens = {tokens_q}, "
f"residual MSE = {quantization_error:.6f}")
total_tokens = n_frames * n_quantizers
token_rate = total_tokens / duration
compression = (len(signal) * 16) / (total_tokens * np.log2(codebook_size))
print(f"\nTotal tokens: {n_frames} frames × {n_quantizers} levels = {total_tokens}")
print(f"Token rate: {token_rate:.0f} tokens/sec "
f"(vs {sr} samples/sec raw)")
print(f"Compression ratio: ~{compression:.0f}×")
print(f"\nThese {total_tokens} tokens can now be modeled by a")
print("transformer — same architecture as GPT for text!")
demonstrate_audio_tokenization()
Video Generation Models
Video generation extends image synthesis to the temporal dimension, producing coherent sequences of frames from text descriptions, images, or other videos. This is one of the hardest generative AI challenges: the model must understand physics, object permanence, 3D consistency, and temporal causality to produce realistic motion.
The dominant approach uses diffusion models (the same family as Stable Diffusion and DALL-E 3), extended with temporal attention layers that enforce consistency across frames. More recent work explores autoregressive video transformers that predict video tokens frame-by-frame, similar to how GPT predicts text tokens word-by-word.
| Model | Organization | Approach | Key Capability |
|---|---|---|---|
| Sora | OpenAI | Diffusion Transformer (DiT) | 60-second photorealistic video from text prompts |
| Veo 2 | Google DeepMind | Diffusion + temporal attention | 4K resolution, cinematic camera control |
| Runway Gen-3 Alpha | Runway | Latent diffusion | Image-to-video, motion brush control |
| Kling | Kuaishou | 3D VAE + diffusion | Physics-aware generation, object permanence |
| Cosmos | NVIDIA | World Foundation Model | Physical world simulation for robotics & AV training |
| Movie Gen | Meta | Transformer + flow matching | 30B model, joint video + audio generation |
Joint Audio-Visual Representations & Tokenizer Innovations
The next frontier in multimodal AI is learning joint representations across audio and visual modalities simultaneously — not just processing them separately and merging outputs, but learning a unified embedding space where a dog barking, a video of a dog, and the text "a dog barks" all map to nearby points.
| Method | Modalities | Key Technique | Application |
|---|---|---|---|
| ImageBind | 6 modalities (image, text, audio, depth, thermal, IMU) | Binding all modalities to images via contrastive learning | Cross-modal retrieval, zero-shot audio classification |
| AudioCLIP | Audio + image + text | Extends CLIP contrastive learning to audio spectrograms | Audio-visual correspondence, sound classification |
| ONE-PEACE | Vision + language + audio | Shared transformer with modality-specific adapters | Unified understanding and generation |
| 4M (4 Modalities) | RGB + depth + semantics + normals | Tokenize all modalities, train single multimodal transformer | Any-to-any modality prediction |
Tokenizer innovations are equally critical for generation quality. Better tokenizers directly improve model output — a tokenizer that captures fine-grained detail produces higher-fidelity generation, while an efficient tokenizer reduces sequence length and training cost.
Tokenizer Innovations for Better Generation
| Innovation | Domain | Problem Solved | Quality Impact |
|---|---|---|---|
| Finite Scalar Quantization (FSQ) | Images / Video | Replaces VQ-VAE codebook with simple scalar binning — no codebook collapse | More stable training, comparable FID scores with simpler design |
| Residual Vector Quantization (RVQ) | Audio | Progressive refinement: each layer encodes the residual from the previous | High-fidelity audio at <6 kbps (vs 64 kbps MP3) |
| Lookup-Free Quantization (LFQ) | Images | Eliminates codebook lookup entirely — each dimension independently quantized to {-1, +1} | Scales to massive codebook sizes (2^18+) without memory issues |
| Visual Tokenizer (MAGVIT-v2) | Images + Video | Unified tokenizer for both images and video using causal 3D CNN | Enables a single model to generate images AND video |
| Multi-scale Tokenization | Text | Variable-length tokens (byte-level to word-level) for better multilingual coverage | 50% fewer tokens for non-Latin scripts, faster inference |
The AI/ML Conference Landscape
Many of these advances debut at top-tier research conferences. Understanding the conference landscape helps you follow the right venues for different areas:
- NeurIPS (Neural Information Processing Systems) — Broadest ML venue; covers theory, methods, applications. ~14,000 attendees, ~3,500 papers/year.
- ICML (International Conference on Machine Learning) — Core ML methods, optimization, learning theory. Peer of NeurIPS.
- ICLR (International Conference on Learning Representations) — Focused on deep learning and representation learning. Known for open peer review.
- CVPR (Computer Vision and Pattern Recognition) — Premier vision conference; where diffusion models, ViTs, and video generation advances typically appear.
- ECCV (European Conference on Computer Vision) — Top European vision venue, biennial. Strong in 3D vision, video understanding, and embodied AI.
- ACL / EMNLP / NAACL — Top NLP-specific conferences for language models, evaluation, and linguistic analysis.
- ICRA / IROS / CoRL — Robotics conferences covering manipulation, navigation, and robot learning.
Retrieval-Augmented Generation
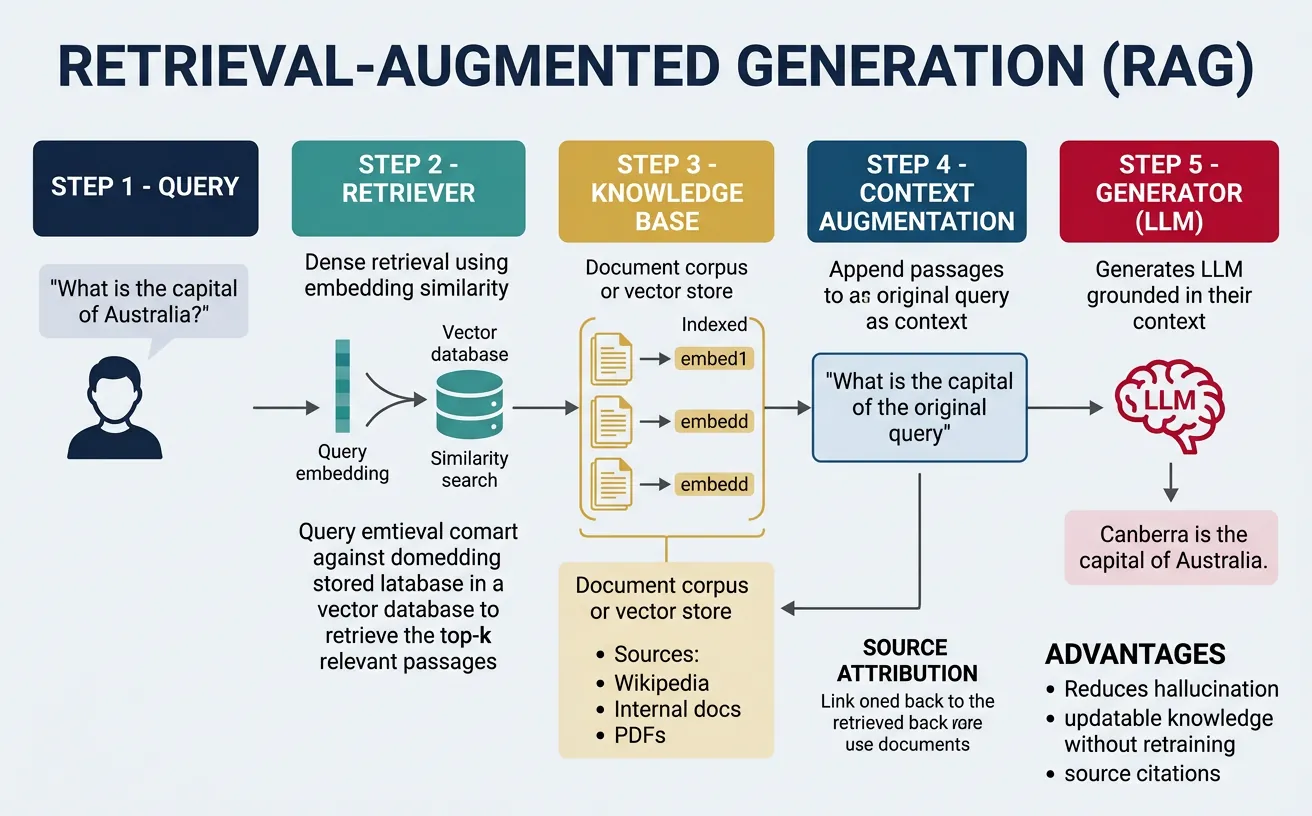
Retrieval-Augmented Generation (RAG) addresses key limitations of LLMs: knowledge cutoffs, hallucinations, and lack of source attribution. By combining retrieval systems with generative models, RAG grounds generation in external documents, enabling accurate answers with citations. First formalized by Lewis et al. (2020), RAG has become essential for building reliable LLM applications that need up-to-date or domain-specific knowledge.
A RAG system has three components: a retriever that finds relevant documents given a query, a knowledge base (vector database) storing document embeddings, and a generator (LLM) that produces answers conditioned on retrieved context. Modern RAG systems use dense retrievers (embedding-based similarity) rather than sparse methods (BM25), though hybrid approaches often work best. The field continues to evolve with advanced techniques like query rewriting, re-ranking, and iterative retrieval.
# Complete RAG Pipeline Implementation
import numpy as np
from typing import List, Dict, Tuple
class SimpleVectorStore:
"""Simple in-memory vector store for RAG."""
def __init__(self, embed_dim=384):
self.embed_dim = embed_dim
self.documents = [] # List of document dicts
self.embeddings = [] # Corresponding embeddings
np.random.seed(42)
def _embed_text(self, text: str) -> np.ndarray:
"""Simulate text embedding (in practice: sentence-transformers)."""
# Create deterministic embedding based on text content
np.random.seed(hash(text) % 2**32)
embed = np.random.randn(self.embed_dim)
return embed / np.linalg.norm(embed)
def add_documents(self, documents: List[Dict]):
"""Add documents to the vector store."""
for doc in documents:
embedding = self._embed_text(doc['content'])
self.documents.append(doc)
self.embeddings.append(embedding)
print(f"Added {len(documents)} documents. Total: {len(self.documents)}")
def search(self, query: str, top_k: int = 3) -> List[Tuple[Dict, float]]:
"""Search for most relevant documents."""
query_embed = self._embed_text(query)
# Compute cosine similarities
similarities = []
for i, doc_embed in enumerate(self.embeddings):
sim = np.dot(query_embed, doc_embed)
similarities.append((self.documents[i], sim))
# Sort by similarity and return top_k
similarities.sort(key=lambda x: -x[1])
return similarities[:top_k]
# Create and populate vector store
store = SimpleVectorStore(embed_dim=384)
# Knowledge base documents
knowledge_base = [
{"id": "1", "content": "Python was created by Guido van Rossum and released in 1991. It emphasizes code readability and simplicity.", "source": "python_history.txt"},
{"id": "2", "content": "The Transformer architecture was introduced in 'Attention Is All You Need' (2017) by Vaswani et al.", "source": "ml_history.txt"},
{"id": "3", "content": "BERT (Bidirectional Encoder Representations from Transformers) was released by Google in 2018.", "source": "ml_history.txt"},
{"id": "4", "content": "GPT-4 is a multimodal large language model created by OpenAI, released in March 2023.", "source": "llm_info.txt"},
{"id": "5", "content": "RAG combines retrieval with generation to provide grounded, factual responses with source attribution.", "source": "rag_overview.txt"},
{"id": "6", "content": "Vector databases like Pinecone, Weaviate, and Chroma are optimized for similarity search at scale.", "source": "infrastructure.txt"},
]
store.add_documents(knowledge_base)
# Test retrieval
query = "When was the Transformer model introduced?"
results = store.search(query, top_k=3)
print(f"\nQuery: '{query}'")
print("\nRetrieved Documents:")
print("=" * 60)
for doc, score in results:
print(f"[Score: {score:.4f}] {doc['source']}")
print(f" {doc['content'][:80]}...\n")RAG vs Fine-Tuning
When to use RAG: Frequently changing information, need for citations, domain-specific knowledge without training data. When to fine-tune: Consistent task format, style adaptation, no need for attribution. Often, the best approach combines both: fine-tune for style/format, use RAG for factual knowledge.
# RAG Prompt Engineering and Generation
def create_rag_prompt(query: str, retrieved_docs: List[Tuple[Dict, float]],
max_context_length: int = 2000) -> str:
"""Create a RAG prompt with retrieved context."""
# Build context from retrieved documents
context_parts = []
current_length = 0
for doc, score in retrieved_docs:
doc_text = f"[Source: {doc['source']}]\n{doc['content']}"
if current_length + len(doc_text) < max_context_length:
context_parts.append(doc_text)
current_length += len(doc_text)
context = "\n\n".join(context_parts)
prompt = f"""Use the following context to answer the question. If the answer cannot be found in the context, say "I don't have enough information to answer this question." Always cite your sources.
Context:
{context}
Question: {query}
Answer (with citations):"""
return prompt
# Generate RAG prompt
query = "When was the Transformer architecture introduced and by whom?"
retrieved = store.search(query, top_k=3)
rag_prompt = create_rag_prompt(query, retrieved)
print("RAG Prompt:")
print("=" * 60)
print(rag_prompt)
print("\n" + "=" * 60)
# Simulated RAG response
simulated_response = """
Based on the provided context, the Transformer architecture was introduced
in 2017 in the paper "Attention Is All You Need" by Vaswani et al.
[Source: ml_history.txt]
The Transformer represented a significant departure from recurrent architectures,
relying entirely on self-attention mechanisms for sequence processing.
"""
print("\nSimulated RAG Response:")
print(simulated_response)# Advanced RAG: Query Rewriting and HyDE
import numpy as np
def query_expansion(original_query: str) -> List[str]:
"""Expand query with related terms for better retrieval."""
# In practice, use an LLM to generate expansions
expansions = {
"transformer": ["attention mechanism", "self-attention", "Vaswani"],
"python": ["programming language", "Guido van Rossum", "scripting"],
"rag": ["retrieval augmented", "vector search", "knowledge grounding"],
}
expanded_queries = [original_query]
for keyword, related in expansions.items():
if keyword.lower() in original_query.lower():
for term in related:
expanded_queries.append(f"{original_query} {term}")
return expanded_queries
def hyde_query(original_query: str) -> str:
"""Hypothetical Document Embeddings (HyDE): Generate hypothetical answer."""
# In practice, LLM generates a hypothetical answer without retrieval
# This answer is then used as the search query
hypothetical_templates = {
"when": "The {topic} was introduced/created in [YEAR] by [PERSON/ORG].",
"what": "{topic} is a [TYPE] that [DESCRIPTION].",
"how": "To accomplish {topic}, you need to [STEPS].",
}
# Simple pattern matching (LLM would do this better)
query_lower = original_query.lower()
if query_lower.startswith("when"):
return f"Hypothetical: The topic mentioned was introduced at a specific time by researchers."
elif query_lower.startswith("what"):
return f"Hypothetical: This is a specific concept or technology with defined characteristics."
else:
return f"Hypothetical answer to: {original_query}"
# Demonstrate advanced retrieval techniques
original = "When was transformer introduced?"
print("Advanced RAG Techniques")
print("=" * 60)
print(f"\nOriginal Query: {original}")
print("\n1. Query Expansion:")
for q in query_expansion(original):
print(f" - {q}")
print("\n2. HyDE (Hypothetical Document):")
hyde_doc = hyde_query(original)
print(f" {hyde_doc}")
print("\n3. Multi-Query Retrieval:")
queries = query_expansion(original)
all_results = []
for q in queries[:3]:
results = store.search(q, top_k=2)
all_results.extend(results)
print(f" Retrieved {len(all_results)} documents from {len(queries[:3])} queries")RAG System Architecture
Ingestion Pipeline: Documents ? Chunking ? Embedding ? Vector DB
Query Pipeline: Query ? (Optional: Rewrite) ? Embed ? Retrieve ? (Optional: Rerank) ? Generate
Key Optimizations:
- Chunking Strategy: Semantic chunking with overlap (512-1024 tokens)
- Hybrid Search: Combine dense (embeddings) + sparse (BM25)
- Re-ranking: Use cross-encoder for more accurate scoring
- Caching: Cache frequent queries and embeddings
RLHF & Instruction Tuning
Raw language models — pretrained on internet text — are surprisingly unhelpful. They can complete sentences, but they don't naturally answer questions, follow instructions, or refuse harmful requests. Instruction tuning and Reinforcement Learning from Human Feedback (RLHF) are the techniques that transform a text-completion engine into an AI assistant. ChatGPT, Claude, Gemini, and every major conversational AI use some variant of these methods.
Analogy: Training a Dog vs. Training a Model
Imagine training a dog (the base model) that already knows how to run, sit, and fetch. Without training, it chases anything that moves — unhelpful and unpredictable. Instruction tuning is like teaching it basic commands using demonstrations (SFT). RLHF is like refining its behaviour by rewarding good behaviour and discouraging bad — not by writing rules, but by learning what you prefer from pairs of behaviours you compare. The result: a dog that does what you actually want, not just what it was predisposed to do.
Instruction Tuning (Supervised Fine-Tuning)
The first step is Supervised Fine-Tuning (SFT) on instruction-following demonstrations. Human annotators write (or curate) thousands of (instruction, ideal response) pairs, and the model is fine-tuned to predict those responses. This teaches the model the format of being an assistant — it learns to answer questions directly, use markdown, admit uncertainty, and follow multi-step instructions. Models trained with SFT alone include early InstructGPT, FLAN-T5, and Alpaca.
# Understanding Instruction Tuning: SFT data format
# This shows what the training data looks like for instruction tuning
def format_instruction(instruction, input_text="", output=""):
"""
Standard instruction tuning format (Alpaca-style).
The model learns to complete this template.
"""
if input_text:
prompt = (
f"### Instruction:\n{instruction}\n\n"
f"### Input:\n{input_text}\n\n"
f"### Response:\n{output}"
)
else:
prompt = (
f"### Instruction:\n{instruction}\n\n"
f"### Response:\n{output}"
)
return prompt
# Examples of SFT training data
sft_examples = [
{
"instruction": "Summarize the following article in 2 sentences.",
"input": "Scientists have discovered a new exoplanet in the habitable zone of a nearby star...",
"output": "Scientists found an exoplanet orbiting a nearby star in the habitable zone, where liquid water could exist. The discovery increases the chances of finding life beyond Earth."
},
{
"instruction": "Translate the following English text to French.",
"input": "The weather today is beautiful.",
"output": "Le temps aujourd'hui est magnifique."
},
{
"instruction": "Write a Python function to reverse a string.",
"input": "",
"output": "def reverse_string(s):\n return s[::-1]\n\n# Example usage\nprint(reverse_string('hello')) # Output: 'olleh'"
},
{
"instruction": "Is the following statement true or false? Explain why.",
"input": "The Earth is the largest planet in our solar system.",
"output": "False. Jupiter is the largest planet in our solar system. The Earth is the fifth largest, with a diameter of about 12,742 km compared to Jupiter's 139,820 km."
},
]
print("Instruction Tuning (SFT) Training Examples")
print("=" * 60)
for i, ex in enumerate(sft_examples, 1):
print(f"\nExample {i}:")
formatted = format_instruction(ex["instruction"], ex["input"], ex["output"])
# Show first 200 characters
print(formatted[:220] + "..." if len(formatted) > 220 else formatted)
print()
print(f"Total training examples: {len(sft_examples)} (real datasets have 50k-500k)")
print("After SFT: model generates responses in the correct format.")
print("Limitation: it doesn't learn which responses are PREFERRED by humans.")
Reward Model Training
SFT teaches format but not quality. The second stage trains a Reward Model (RM) — a separate neural network that scores responses on a scale from "bad" to "excellent". Human annotators compare pairs of model responses to the same prompt and indicate which they prefer. The RM learns to predict these preferences, effectively internalizing human quality judgement. This reward model will later serve as the "critic" in the RL stage, guiding the LLM toward better responses.
# Reward Model: architecture and preference learning
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
class RewardModel(nn.Module):
"""
Simplified reward model architecture.
In practice, this is an LM with a scalar head added.
E.g., take a 7B LLaMA, replace the token prediction head
with a single Linear(hidden_size, 1) layer.
"""
def __init__(self, hidden_size=256, vocab_size=100):
super().__init__()
# Simplified: embedding + transformer layers + scalar output
self.embedding = nn.Embedding(vocab_size, hidden_size)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=hidden_size, nhead=4, batch_first=True),
num_layers=2
)
# Scalar head: maps from hidden_size to 1 reward value
self.reward_head = nn.Linear(hidden_size, 1)
def forward(self, input_ids):
# Embed tokens
x = self.embedding(input_ids)
# Apply transformer
x = self.transformer(x)
# Pool over sequence (mean pooling) and get reward
x = x.mean(dim=1)
reward = self.reward_head(x).squeeze(-1)
return reward
def preference_loss(reward_chosen, reward_rejected):
"""
Bradley-Terry loss for learning from preference pairs.
The model is trained to assign higher reward to the chosen response.
L = -log(sigmoid(r_chosen - r_rejected))
"""
return -F.logsigmoid(reward_chosen - reward_rejected).mean()
# Simulate training on preference pairs
reward_model = RewardModel(hidden_size=64, vocab_size=50)
optimizer = torch.optim.Adam(reward_model.parameters(), lr=1e-4)
print("Reward Model Training on Preference Pairs")
print("=" * 50)
print("Format: (prompt, chosen_response, rejected_response)")
print("Goal: reward_model(chosen) > reward_model(rejected)")
print()
# Simulate 5 training steps
losses = []
for step in range(5):
# Fake token sequences: chosen responses (seq_len=8), rejected (seq_len=8)
chosen_ids = torch.randint(0, 50, (4, 8)) # batch=4 preferred responses
rejected_ids = torch.randint(0, 50, (4, 8)) # batch=4 rejected responses
r_chosen = reward_model(chosen_ids)
r_rejected = reward_model(rejected_ids)
loss = preference_loss(r_chosen, r_rejected)
optimizer.zero_grad()
loss.backward()
optimizer.step()
accuracy = (r_chosen > r_rejected).float().mean().item()
losses.append(loss.item())
print(f"Step {step+1}: Loss={loss.item():.4f}, "
f"Accuracy={accuracy:.0%} (chosen scored higher than rejected)")
print(f"\nFinal reward gap: {(r_chosen - r_rejected).mean().item():.4f}")
print("A positive gap means the model learned to prefer the better responses.")
PPO: Optimizing the LLM with the Reward Signal
The third and most complex stage uses Proximal Policy Optimization (PPO) — a reinforcement learning algorithm — to update the LLM's weights using the reward model's scores as feedback. The LLM acts as the "policy" (it generates text), and the reward model acts as the "environment" (it scores the text). A KL divergence penalty prevents the LLM from drifting too far from the original SFT model, avoiding reward hacking where the model learns to exploit the reward model rather than genuinely improving.
# PPO-RLHF: Conceptual implementation showing key components
import torch
import numpy as np
class PPORLHFSimulator:
"""
Demonstrates the PPO-RLHF training loop components.
Simplified for clarity — real implementations use TRL library.
"""
def __init__(self, kl_coefficient=0.02):
"""
kl_coefficient: weight on KL divergence penalty
Higher = model stays closer to SFT baseline
Lower = model can diverge more to maximize reward
"""
self.kl_coef = kl_coefficient
self.policy_rewards = []
def compute_rlhf_reward(self, raw_reward, kl_divergence):
"""
RLHF reward = reward_model_score - beta * KL(policy || reference)
The KL term prevents reward hacking:
- Without it: model writes "I am helpful! I am safe!" repeatedly
- With it: model improves helpfulness while staying coherent
"""
return raw_reward - self.kl_coef * kl_divergence
def simulate_training_step(self, step):
"""Simulate one PPO step."""
# Simulate improving reward model scores over training
raw_reward = 0.3 + 0.1 * step + np.random.normal(0, 0.05)
# KL divergence increases as model drifts from SFT baseline
kl_divergence = 0.5 + 0.05 * step + np.random.normal(0, 0.02)
# Combined RLHF reward
rlhf_reward = self.compute_rlhf_reward(raw_reward, kl_divergence)
return {
'step': step,
'raw_reward': raw_reward,
'kl_divergence': kl_divergence,
'rlhf_reward': rlhf_reward
}
# Run simulation
trainer = PPORLHFSimulator(kl_coefficient=0.02)
print("PPO-RLHF Training Simulation")
print("=" * 60)
print(f"{'Step':>5} | {'Raw Reward':>12} | {'KL Divergence':>14} | {'RLHF Reward':>12}")
print("-" * 55)
for step in range(1, 11):
metrics = trainer.simulate_training_step(step)
print(f"{metrics['step']:>5} | {metrics['raw_reward']:>12.4f} | "
f"{metrics['kl_divergence']:>14.4f} | {metrics['rlhf_reward']:>12.4f}")
print("\nKey observations:")
print("- Raw reward increases (model gets better at pleasing humans)")
print("- KL divergence grows (model drifts from SFT baseline)")
print("- KL penalty moderates the total RLHF reward")
print("- Result: helpful model that stays coherent and safe")
# Using TRL library for RLHF training (production approach)
# pip install trl transformers
# This shows the real production RLHF setup using Hugging Face TRL
# Run this to see the structure - models are lightweight for demo
from trl import PPOConfig, PPOTrainer, AutoModelForCausalLMWithValueHead
from transformers import AutoTokenizer
import torch
print("Production RLHF with TRL Library")
print("=" * 50)
print()
# Step 1: Load SFT-trained model + reference model (frozen copy)
model_name = "gpt2" # Use your SFT-tuned model in practice
print(f"1. Loading policy model: {model_name}")
print(" - This is your SFT-tuned model (trainable)")
print(" - AutoModelForCausalLMWithValueHead adds a scalar head for PPO")
print()
print("2. Loading reference model (frozen copy of SFT model)")
print(" - Used to compute KL divergence penalty")
print(" - Prevents catastrophic forgetting and reward hacking")
print()
# Step 2: PPO Configuration
ppo_config = PPOConfig(
model_name=model_name,
learning_rate=1.41e-5,
batch_size=16, # Rollout batch size
mini_batch_size=4, # Mini-batch for PPO update
gradient_accumulation_steps=1,
optimize_cuda_cache=True,
early_stopping=False,
target_kl=6.0, # Stop early if KL divergence exceeds this
kl_penalty="kl", # Use full KL (vs 'abs', 'mse')
seed=42,
use_score_scaling=True, # Normalize rewards for stability
use_score_norm=True,
score_clip=0.5, # Clip rewards to [-0.5, 0.5]
)
print("3. PPO Configuration:")
for key in ['learning_rate', 'batch_size', 'target_kl', 'score_clip']:
print(f" {key}: {getattr(ppo_config, key)}")
print()
print("4. Training loop (pseudocode):")
print(" for each batch:")
print(" responses = policy.generate(prompts)")
print(" rewards = reward_model.score(prompts, responses)")
print(" ref_logprobs = reference_model.logprobs(responses)")
print(" policy_logprobs = policy.logprobs(responses)")
print(" kl = policy_logprobs - ref_logprobs")
print(" rlhf_rewards = rewards - beta * kl")
print(" ppo_trainer.step(prompts, responses, rlhf_rewards)")
print()
print("Result: Policy model that maximizes reward while staying")
print("close to the SFT reference (controlled by KL penalty).")
DPO: Simpler Alternative to PPO
Direct Preference Optimization (DPO), introduced in 2023, reformulates the RLHF objective into a supervised learning problem that trains the policy directly from preference data — no RL loop, no separate reward model, no complex PPO machinery. The key insight: the optimal policy under the RLHF objective has a closed-form relationship to the preference data, which DPO exploits. DPO has become popular for fine-tuning open-source models because it's stable, simple, and achieves competitive results.
# DPO Training: Comparing preference pairs directly
import torch
import torch.nn.functional as F
import numpy as np
def dpo_loss(
policy_chosen_logps: torch.Tensor,
policy_rejected_logps: torch.Tensor,
reference_chosen_logps: torch.Tensor,
reference_rejected_logps: torch.Tensor,
beta: float = 0.1
) -> torch.Tensor:
"""
Direct Preference Optimization loss.
Intuition: We want the policy to assign relatively MORE probability
to chosen responses vs rejected, compared to the reference model.
L_DPO = -E[log sigmoid(beta * (log π(chosen)/π_ref(chosen)
- log π(rejected)/π_ref(rejected)))]
Args:
policy_chosen_logps: Log probs of chosen responses under policy
policy_rejected_logps: Log probs of rejected responses under policy
reference_chosen_logps: Log probs of chosen under reference model
reference_rejected_logps: Log probs of rejected under reference model
beta: Temperature (0.1-0.5 typical; lower = larger updates)
Returns:
Scalar DPO loss
"""
# Log-ratio for chosen: how much MORE likely is chosen under policy vs reference?
chosen_log_ratio = policy_chosen_logps - reference_chosen_logps
# Log-ratio for rejected: how much MORE likely is rejected under policy vs reference?
rejected_log_ratio = policy_rejected_logps - reference_rejected_logps
# DPO loss: train policy to prefer chosen over rejected
logits = beta * (chosen_log_ratio - rejected_log_ratio)
loss = -F.logsigmoid(logits).mean()
# Implicit reward: how much does policy prefer chosen over reference?
reward_chosen = beta * chosen_log_ratio.detach()
reward_rejected = beta * rejected_log_ratio.detach()
reward_accuracy = (reward_chosen > reward_rejected).float().mean()
return loss, reward_accuracy
print("DPO vs PPO-RLHF Comparison")
print("=" * 60)
# Simulate training dynamics
print("\nSimulating training over 10 steps:")
print(f"{'Step':>5} | {'DPO Loss':>10} | {'Reward Acc':>12} | {'Comment'}")
print("-" * 55)
for step in range(1, 11):
# Simulate improving policy probabilities
base_prob = -3.0 + 0.2 * step # Chosen gets more probable
policy_chosen = torch.tensor([base_prob + np.random.normal(0, 0.1)])
policy_rejected = torch.tensor([base_prob - 0.5 + np.random.normal(0, 0.1)])
reference_chosen = torch.tensor([-3.0])
reference_rejected = torch.tensor([-3.0])
loss, acc = dpo_loss(policy_chosen, policy_rejected, reference_chosen, reference_rejected)
comment = "improving" if step > 5 else "learning"
print(f"{step:>5} | {loss.item():>10.4f} | {acc.item():>12.0%} | {comment}")
print("\n✓ DPO advantages over PPO:")
print(" - No separate reward model needed")
print(" - No RL loop or rollout buffer")
print(" - Stable supervised training signal")
print(" - Same data format as SFT (prompt, chosen, rejected)")
Case Study: InstructGPT — The Paper That Started It All
The Problem (2021): GPT-3 was powerful but poorly aligned. It would complete prompts literally ("write a story that is harmful..." → proceeds to write harmful content), refuse benign requests arbitrarily, and generate confident misinformation.
The Solution — InstructGPT (2022): OpenAI applied three-stage RLHF: (1) 13K instruction-following demonstrations for SFT, (2) 33K preference comparisons for reward model training, (3) PPO optimization. The result: a 1.3B parameter InstructGPT model was preferred over the 175B GPT-3 in 85% of evaluations despite being 100× smaller.
Key finding: "Alignment tax" was small — RLHF models barely degraded on standard NLP benchmarks while dramatically improving instruction following. This demonstrated RLHF's practical viability for production systems.
Downstream impact: ChatGPT (GPT-3.5 + RLHF), GPT-4, Claude (Constitutional AI + RLHF), Gemini, LLaMA-Chat, Mistral-Instruct — all use variants of this pipeline.
RLHF & Instruction Tuning Exercises
- [Beginner] Using the TRL library, fine-tune a small GPT-2 model with SFT on 100 (instruction, response) pairs from the Alpaca dataset. Compare outputs before and after fine-tuning.
- [Beginner] Implement the Bradley-Terry preference loss from scratch and train a simple reward model to distinguish "formal" from "informal" writing style.
- [Intermediate] Use TRL's
DPOTrainerto fine-tune a small model on theAnthropic/hh-rlhfpreference dataset. Compare DPO vs SFT on a set of test prompts. - [Intermediate] Experiment with DPO's
betaparameter (0.05, 0.1, 0.5). How does it affect the tradeoff between following preferences and maintaining the reference model's distribution? - [Advanced] Implement a full mini-RLHF pipeline: (1) SFT a GPT-2 on instructions, (2) Train a reward model on synthetic preference pairs, (3) Run PPO using TRL. Log reward and KL divergence over training.
- [Advanced] Compare RLHF, DPO, and KTO (Kahneman-Tversky Optimization) on a text summarization task. Which produces summaries that humans prefer in a blind evaluation?
Alignment & Constitutional AI
AI alignment ensures that AI systems behave in accordance with human intentions and values. As LLMs become more capable, alignment becomes critical—powerful models that don't align with human goals could cause significant harm. The field has developed several approaches: RLHF (Reinforcement Learning from Human Feedback), Constitutional AI, and Direct Preference Optimization. These methods transform raw pretrained models into helpful, harmless, and honest assistants.
RLHF, pioneered by OpenAI's InstructGPT paper, trains models to follow human preferences through a three-stage process: supervised fine-tuning, reward model training, and PPO optimization. Constitutional AI (Anthropic) extends this by using the model itself to generate and critique responses according to explicit principles. These techniques are fundamental to modern assistant models and represent active research areas as the field works toward more robust and scalable alignment methods.
# RLHF Pipeline Simulation
import numpy as np
from typing import List, Tuple
class RLHFSimulator:
"""Simplified RLHF training pipeline demonstration."""
def __init__(self):
np.random.seed(42)
self.reward_model_weights = np.random.randn(10) # Simple linear reward
def generate_response(self, prompt: str, policy_version: str = "base") -> str:
"""Simulate response generation from different policy versions."""
responses = {
"base": [
"Here's how to do that... [potentially unsafe]",
"I'll help with anything you ask.",
"Sure, here's the information without any caveats."
],
"sft": [
"I'd be happy to help with that. Here's a safe approach...",
"Let me provide a helpful and balanced response.",
"I can assist with that. Here are the key considerations..."
],
"rlhf": [
"I'd be glad to help! Here's a thorough, safe explanation...",
"Great question! Let me provide a helpful, harmless response.",
"I'll give you accurate information while noting important safety considerations."
]
}
return np.random.choice(responses.get(policy_version, responses["base"]))
def get_human_preference(self, response_a: str, response_b: str) -> int:
"""Simulate human preference labeling (0=A preferred, 1=B preferred)."""
# Simulate: prefer longer, more helpful responses
score_a = len(response_a) + (10 if "safe" in response_a.lower() else 0)
score_b = len(response_b) + (10 if "safe" in response_b.lower() else 0)
return 0 if score_a > score_b else 1
def compute_reward(self, response: str) -> float:
"""Compute reward model score for a response."""
# Simple heuristics (in practice: learned neural network)
score = 0.0
score += 0.01 * len(response) # Longer is slightly better
score += 0.5 if "help" in response.lower() else 0
score += 0.5 if "safe" in response.lower() else 0
score += 0.3 if "!" in response else 0 # Enthusiasm
score -= 0.8 if "unsafe" in response.lower() else 0
return score
# Demonstrate RLHF stages
rlhf = RLHFSimulator()
print("RLHF Training Pipeline Demonstration")
print("=" * 60)
# Stage 1: Supervised Fine-Tuning (SFT)
print("\n?? STAGE 1: Supervised Fine-Tuning (SFT)")
print("-" * 40)
sft_data = [
("Explain photosynthesis", "Photosynthesis is the process by which plants..."),
("Write a poem about spring", "In spring's gentle embrace, flowers bloom..."),
]
print("Training on human-written demonstrations:")
for prompt, response in sft_data:
print(f" Prompt: {prompt[:30]}...")
print(f" Demo: {response[:40]}...\n")
# Stage 2: Reward Model Training
print("\n?? STAGE 2: Reward Model Training")
print("-" * 40)
print("Collecting human preferences on response pairs:")
for i in range(3):
prompt = f"Sample prompt {i+1}"
resp_a = rlhf.generate_response(prompt, "sft")
resp_b = rlhf.generate_response(prompt, "base")
pref = rlhf.get_human_preference(resp_a, resp_b)
print(f" Comparison {i+1}: {'Response A' if pref == 0 else 'Response B'} preferred")
# Stage 3: PPO Optimization
print("\n?? STAGE 3: PPO Optimization")
print("-" * 40)
print("Optimizing policy using reward model:")
for version in ["base", "sft", "rlhf"]:
response = rlhf.generate_response("Help me learn", version)
reward = rlhf.compute_reward(response)
print(f" {version.upper():6s} policy: reward = {reward:.2f}")
print(f" response: '{response[:50]}...'\n")The Three H's of AI Assistants
Helpful: Provides useful, accurate information. Harmless: Refuses dangerous requests, avoids harmful content. Honest: Acknowledges uncertainty, doesn't fabricate information. These principles, articulated by Anthropic, guide modern AI assistant development and evaluation.
# Constitutional AI: Self-Critique and Revision
class ConstitutionalAI:
"""Demonstrate Constitutional AI principles."""
def __init__(self):
# The "constitution" - explicit principles
self.principles = [
"Responses should be helpful and informative.",
"Responses should not help with illegal activities.",
"Responses should be honest about uncertainty.",
"Responses should not be deceptive or manipulative.",
"Responses should respect user privacy.",
"Responses should promote safety and well-being.",
]
def generate_initial_response(self, prompt: str) -> str:
"""Simulate initial response generation."""
# In practice, this comes from the base model
return f"Here's a response to '{prompt}' that might need revision."
def critique_response(self, response: str, principle: str) -> str:
"""Self-critique: evaluate response against a principle."""
return f"Critique: Does this response adhere to '{principle}'? " \
f"Let me evaluate..."
def revise_response(self, original: str, critique: str) -> str:
"""Revise response based on critique."""
return f"Revised response that better adheres to the principle: " \
f"'{original}' [improved based on: {critique[:50]}...]"
def constitutional_process(self, prompt: str) -> dict:
"""Run the full Constitutional AI process."""
result = {
'prompt': prompt,
'initial_response': self.generate_initial_response(prompt),
'critiques': [],
'revisions': []
}
# Apply each principle
current_response = result['initial_response']
for principle in self.principles[:3]: # First 3 for demo
critique = self.critique_response(current_response, principle)
revision = self.revise_response(current_response, critique)
result['critiques'].append({'principle': principle, 'critique': critique})
result['revisions'].append(revision)
current_response = revision
result['final_response'] = current_response
return result
# Demonstrate Constitutional AI
cai = ConstitutionalAI()
print("Constitutional AI Process")
print("=" * 60)
print("\nPrinciples (Constitution):")
for i, p in enumerate(cai.principles, 1):
print(f" {i}. {p}")
result = cai.constitutional_process("How do I access restricted information?")
print(f"\nPrompt: {result['prompt']}")
print(f"\nInitial Response: {result['initial_response'][:60]}...")
print("\nCritique & Revision Process:")
for i, (crit, rev) in enumerate(zip(result['critiques'], result['revisions']), 1):
print(f"\n Round {i}:")
print(f" Principle: {crit['principle'][:50]}...")
print(f" Revision: {rev[:60]}...")
print(f"\nFinal Response: {result['final_response'][:80]}...")# Direct Preference Optimization (DPO)
import numpy as np
def dpo_loss(policy_logprobs_chosen: float, policy_logprobs_rejected: float,
ref_logprobs_chosen: float, ref_logprobs_rejected: float,
beta: float = 0.1) -> float:
"""
Compute Direct Preference Optimization loss.
DPO directly optimizes the policy without a separate reward model,
using a closed-form solution derived from RLHF objective.
Args:
policy_logprobs_chosen: Log prob of chosen response under policy
policy_logprobs_rejected: Log prob of rejected response under policy
ref_logprobs_chosen: Log prob of chosen response under reference
ref_logprobs_rejected: Log prob of rejected response under reference
beta: Temperature parameter (controls KL penalty strength)
"""
# Compute log ratios
policy_ratio = policy_logprobs_chosen - policy_logprobs_rejected
ref_ratio = ref_logprobs_chosen - ref_logprobs_rejected
# DPO loss: -log(sigmoid(beta * (policy_ratio - ref_ratio)))
logit = beta * (policy_ratio - ref_ratio)
loss = -np.log(1 / (1 + np.exp(-logit)))
return loss
# Demonstrate DPO
print("Direct Preference Optimization (DPO)")
print("=" * 60)
print("\nDPO simplifies RLHF by directly optimizing preferences")
print("without training a separate reward model.\n")
# Simulated log probabilities
preference_examples = [
{"chosen": (-2.5, -2.8), "rejected": (-3.2, -3.0), "desc": "Clear preference"},
{"chosen": (-2.5, -2.5), "rejected": (-2.6, -2.6), "desc": "Slight preference"},
{"chosen": (-2.5, -3.5), "rejected": (-2.5, -2.5), "desc": "Policy improved"},
]
for ex in preference_examples:
loss = dpo_loss(
ex["chosen"][0], ex["rejected"][0], # Policy
ex["chosen"][1], ex["rejected"][1], # Reference
beta=0.1
)
print(f"{ex['desc']:20s}: DPO Loss = {loss:.4f}")
print("\nLower loss = policy better captures human preferences")Alignment Techniques Comparison
| Method | Pros | Cons |
|---|---|---|
| RLHF (PPO) | Well-studied, effective | Complex, unstable training |
| DPO | Simpler, more stable | Less flexible than RL |
| Constitutional AI | Scalable, principled | Depends on principle quality |
| RLAIF | Less human labeling | AI feedback limitations |
Future Directions
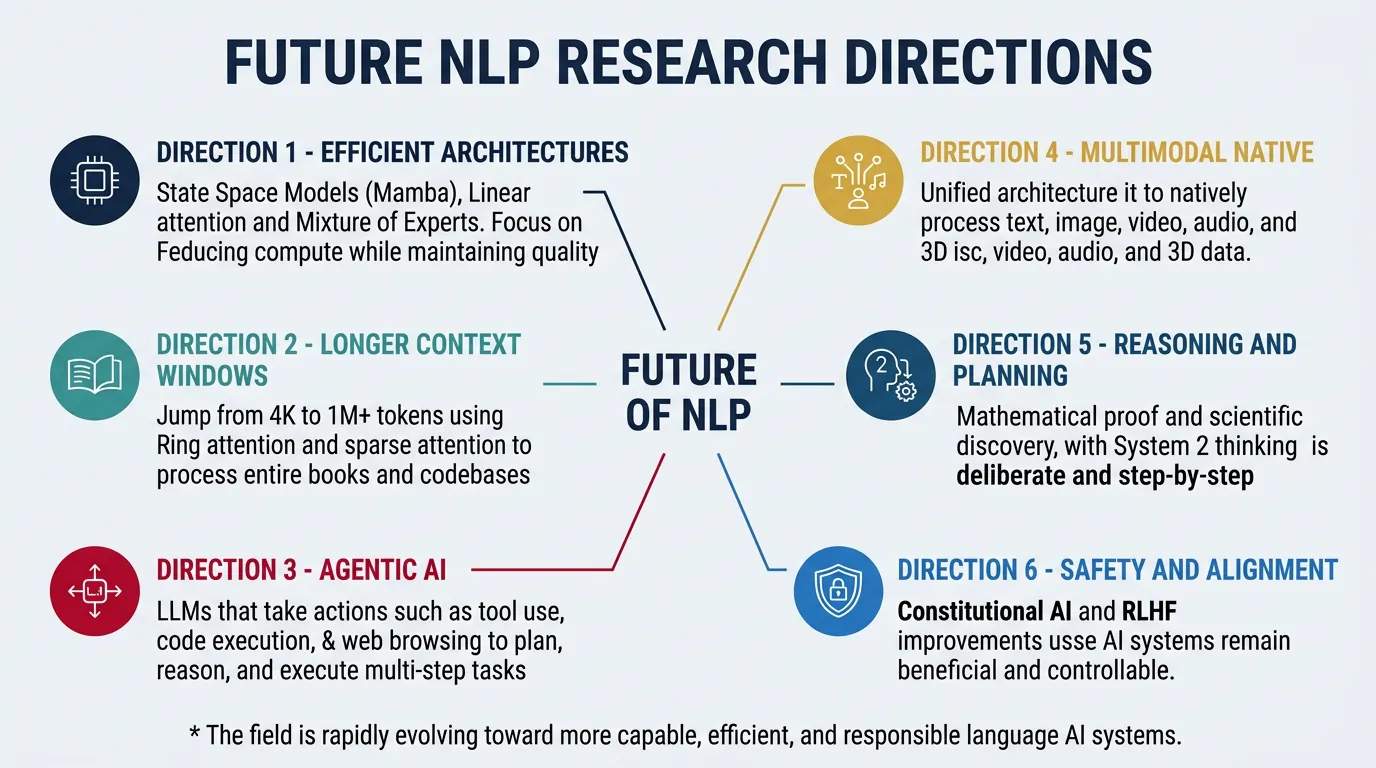
The NLP research frontier continues to expand rapidly. Key emerging areas include: Efficient architectures (state space models like Mamba, sparse attention), longer context (million-token windows), improved reasoning (program synthesis, neurosymbolic approaches), and agentic AI (autonomous systems that plan and execute multi-step tasks). The field is also grappling with fundamental questions about what capabilities can emerge from scale versus requiring architectural innovations.
Multimodal and embodied AI represent major growth areas, with models increasingly processing video, audio, code, and real-world sensor data. Personalization and memory enable models to maintain context across sessions and adapt to individual users. Meanwhile, interpretability and safety research works to understand model internals and ensure reliable behavior. The coming years will likely see continued rapid progress across all these dimensions.
# State Space Models (SSMs) - The Mamba Revolution
import numpy as np
def ssm_step(x, h, A, B, C, D):
"""
Single step of a State Space Model.
State equation: h' = Ah + Bx
Output equation: y = Ch + Dx
SSMs like Mamba achieve linear complexity O(n) vs
Transformer's quadratic O(n²) attention.
"""
# State update
h_new = A @ h + B @ x
# Output
y = C @ h_new + D @ x
return y, h_new
def run_ssm_sequence(inputs, state_dim=16, input_dim=4):
"""Run SSM over a sequence."""
np.random.seed(42)
seq_len = len(inputs)
# Initialize SSM parameters
A = np.eye(state_dim) * 0.9 + np.random.randn(state_dim, state_dim) * 0.1
B = np.random.randn(state_dim, input_dim) * 0.1
C = np.random.randn(input_dim, state_dim) * 0.1
D = np.zeros((input_dim, input_dim))
# Initial hidden state
h = np.zeros(state_dim)
outputs = []
for x in inputs:
y, h = ssm_step(x, h, A, B, C, D)
outputs.append(y)
return np.array(outputs)
# Compare complexity
print("State Space Models vs Transformers")
print("=" * 60)
seq_lengths = [1000, 10000, 100000, 1000000]
print("\nComputational Complexity Comparison:")
print(f"{'Sequence Length':<20} {'Transformer O(n²)':<20} {'SSM O(n)':<15}")
print("-" * 55)
for n in seq_lengths:
transformer_ops = n * n # Quadratic attention
ssm_ops = n # Linear recurrence
print(f"{n:<20,} {transformer_ops:<20,} {ssm_ops:<15,}")
# Run example
print("\n" + "=" * 60)
print("\nSSM Example Run:")
inputs = [np.random.randn(4) for _ in range(5)]
outputs = run_ssm_sequence(inputs)
print(f"Input shape: {len(inputs)} steps × 4 dims")
print(f"Output shape: {outputs.shape}")
print(f"Final output: {outputs[-1].round(3)}")Mamba and Selective State Spaces
Mamba (Gu & Dao, 2023) introduces selective state spaces that dynamically adjust parameters based on input. This achieves Transformer-quality results with linear complexity, enabling efficient processing of very long sequences. Mamba-based models are increasingly competitive with Transformers on language tasks while being significantly faster.
# Agentic AI: Tool Use and Planning
class SimpleAgent:
"""Demonstrate agentic AI patterns."""
def __init__(self):
self.tools = {
'search': self._search,
'calculate': self._calculate,
'write_file': self._write_file,
'read_file': self._read_file,
}
self.memory = [] # Conversation/action history
def _search(self, query: str) -> str:
return f"Search results for '{query}': [simulated results]"
def _calculate(self, expression: str) -> str:
try:
# Safe evaluation of simple expressions
result = eval(expression, {"__builtins__": {}}, {})
return f"Result: {result}"
except:
return "Calculation error"
def _write_file(self, content: str) -> str:
return f"File written with {len(content)} characters"
def _read_file(self, filename: str) -> str:
return f"Contents of {filename}: [simulated content]"
def plan(self, goal: str) -> list:
"""Generate a plan to achieve the goal."""
# Simplified planning (in practice: LLM generates this)
if "research" in goal.lower():
return [
{"thought": "Need to gather information", "action": "search", "input": goal},
{"thought": "Analyze findings", "action": "calculate", "input": "len('findings')"},
{"thought": "Save results", "action": "write_file", "input": "research_summary"},
]
return [{"thought": "Generic task", "action": "search", "input": goal}]
def execute(self, goal: str) -> dict:
"""Plan and execute actions to achieve goal."""
plan = self.plan(goal)
results = []
for step in plan:
tool = self.tools.get(step['action'])
if tool:
result = tool(step['input'])
step['result'] = result
results.append(step)
self.memory.append(step)
return {'goal': goal, 'steps': results}
# Demonstrate agent execution
agent = SimpleAgent()
print("Agentic AI: Planning and Tool Use")
print("=" * 60)
goal = "Research the latest advances in quantum computing"
print(f"\nGoal: {goal}\n")
execution = agent.execute(goal)
print("Execution Trace:")
for i, step in enumerate(execution['steps'], 1):
print(f"\n Step {i}:")
print(f" Thought: {step['thought']}")
print(f" Action: {step['action']}({step['input'][:30]}...)")
print(f" Result: {step['result'][:50]}...")
print(f"\n\nAgent memory contains {len(agent.memory)} actions")# Long Context: Extending to Millions of Tokens
import numpy as np
def analyze_context_scaling():
"""Analyze memory and compute requirements for long context."""
model_configs = [
{"name": "Standard (4K)", "context": 4096, "layers": 32, "hidden": 4096, "heads": 32},
{"name": "Extended (32K)", "context": 32768, "layers": 32, "hidden": 4096, "heads": 32},
{"name": "Long (128K)", "context": 131072, "layers": 32, "hidden": 4096, "heads": 32},
{"name": "Million (1M)", "context": 1048576, "layers": 32, "hidden": 4096, "heads": 32},
]
print("Long Context Scaling Analysis")
print("=" * 70)
print(f"{'Model':<20} {'Context':<12} {'KV Cache':<15} {'Attention FLOPs':<18}")
print("-" * 70)
for config in model_configs:
ctx = config["context"]
layers = config["layers"]
hidden = config["hidden"]
heads = config["heads"]
head_dim = hidden // heads
# KV cache memory (per batch)
kv_cache_bytes = 2 * layers * ctx * hidden * 2 # 2 for K,V; 2 bytes per float16
kv_cache_gb = kv_cache_bytes / (1024**3)
# Attention FLOPs (quadratic in context)
attention_flops = 2 * ctx * ctx * hidden # Simplified
print(f"{config['name']:<20} {ctx:<12,} {kv_cache_gb:<15.2f} GB {attention_flops:<18,.0f}")
return model_configs
configs = analyze_context_scaling()
print("\n" + "=" * 70)
print("\nTechniques for Long Context:")
techniques = [
("Sliding Window Attention", "Limit attention to local window + global tokens"),
("Sparse Attention", "Attend to subset of tokens (strided, random, learned)"),
("Linear Attention", "Replace softmax with kernel approximation"),
("Ring Attention", "Distribute attention across devices"),
("Memory Compression", "Compress older KV states"),
("Landmark Attention", "Store summaries at key positions"),
]
for tech, desc in techniques:
print(f" • {tech}: {desc}")Research Frontiers in NLP (2025-2026)
| Area | Key Questions | Notable Work |
|---|---|---|
| Efficient Architectures | Can we match Transformers with O(n) complexity? | Mamba, RWKV, RetNet |
| World Models | Can LLMs learn accurate world representations? | Genie, JEPA |
| Reasoning | How to achieve robust, verifiable reasoning? | AlphaProof, Program Synthesis |
| Agents | How to build reliable autonomous systems? | AutoGPT, Claude Artifacts |
| Interpretability | Can we understand what models learn? | Mechanistic Interpretability |
| Efficiency | Smaller, faster models with same capabilities? | Distillation, Pruning, Quantization |
Conclusion & Series Recap
This exploration of cutting-edge NLP research concludes our comprehensive 16-part journey through natural language processing. From the foundational concepts of tokenization and linguistic analysis to the frontier of large language models and AI alignment, we've covered the full spectrum of modern NLP. The field has transformed dramatically—what once required task-specific models and extensive feature engineering now leverages powerful pretrained models that can be prompted or lightly fine-tuned for virtually any language task.
The technologies we've explored are not merely academic—they power the AI assistants, search engines, translation services, and content creation tools used by billions. Understanding these systems, from their mathematical foundations to their practical deployment, equips you to build, evaluate, and responsibly deploy NLP applications. As the field continues its rapid evolution, the principles covered in this series provide a solid foundation for engaging with whatever innovations emerge next.
# Complete NLP Series Summary
series_overview = {
"Part 1: Fundamentals": {
"topics": ["Linguistics basics", "Morphology", "Syntax", "Semantics"],
"key_concept": "Language structure and meaning"
},
"Part 2: Tokenization": {
"topics": ["Word tokenization", "Subword (BPE, WordPiece)", "Text cleaning"],
"key_concept": "Converting text to processable units"
},
"Part 3: Text Representation": {
"topics": ["Bag-of-Words", "TF-IDF", "Feature engineering"],
"key_concept": "Numerical encoding of text"
},
"Part 4: Word Embeddings": {
"topics": ["Word2Vec", "GloVe", "FastText"],
"key_concept": "Dense semantic representations"
},
"Part 5: Language Models": {
"topics": ["N-grams", "Perplexity", "Smoothing"],
"key_concept": "Predicting word sequences"
},
"Part 6: Neural Networks": {
"topics": ["Feedforward NNs", "Backpropagation", "Text classification"],
"key_concept": "Deep learning fundamentals for NLP"
},
"Part 7: RNNs & LSTMs": {
"topics": ["Sequence modeling", "LSTM", "GRU", "Bidirectional"],
"key_concept": "Processing sequential data"
},
"Part 8: Transformers": {
"topics": ["Self-attention", "Multi-head attention", "Positional encoding"],
"key_concept": "The architecture revolution"
},
"Part 9: Pretrained Models": {
"topics": ["BERT", "RoBERTa", "Transfer learning", "Fine-tuning"],
"key_concept": "Learning from massive text corpora"
},
"Part 10: GPT & Generation": {
"topics": ["Autoregressive LMs", "GPT architecture", "Sampling methods"],
"key_concept": "Text generation at scale"
},
"Part 11: Core Tasks": {
"topics": ["Classification", "NER", "POS tagging", "Parsing"],
"key_concept": "Fundamental NLP applications"
},
"Part 12: Advanced Tasks": {
"topics": ["QA", "Summarization", "Translation", "Dialogue"],
"key_concept": "Complex language understanding & generation"
},
"Part 13: Multilingual NLP": {
"topics": ["Cross-lingual transfer", "mBERT", "Language-agnostic models"],
"key_concept": "NLP across 100+ languages"
},
"Part 14: Evaluation & Ethics": {
"topics": ["Metrics", "Bias", "Fairness", "Responsible AI"],
"key_concept": "Measuring and improving NLP systems"
},
"Part 15: Production": {
"topics": ["Optimization", "Deployment", "MLOps", "Scaling"],
"key_concept": "Real-world NLP systems"
},
"Part 16: Cutting-Edge": {
"topics": ["LLMs", "CoT", "RAG", "Multimodal", "Alignment"],
"key_concept": "The research frontier"
}
}
print("Complete NLP Series: 16 Parts of NLP Mastery")
print("=" * 60)
for part, info in series_overview.items():
print(f"\n?? {part}")
print(f" Key: {info['key_concept']}")
print(f" Topics: {', '.join(info['topics'][:3])}...")
print("\n" + "=" * 60)
print("\n?? Your NLP Journey: From Tokens to Transformers to Tomorrow!")Your NLP Learning Path Forward
To deepen your expertise:
- Build Projects: Implement RAG systems, fine-tune models, create chatbots
- Read Papers: Follow arXiv, attend NeurIPS/ACL/EMNLP virtually
- Experiment: Try new models on Hugging Face, benchmark on standard datasets
- Specialize: Pick an area (dialogue, retrieval, efficiency) and go deep
- Contribute: Open source, write tutorials, share knowledge
Key Resources: Hugging Face Hub, Papers With Code, LangChain/LlamaIndex docs, OpenAI/Anthropic cookbooks
Thank you for following this comprehensive series. The NLP field moves fast, but the fundamentals endure: understanding language structure, representing text mathematically, modeling sequences, and leveraging scale. With these foundations, you're prepared to learn any new technique, evaluate any new model, and build applications that understand and generate human language. The future of NLP is being written now—go make your contribution!
Congratulations!
You've completed the 16-part Complete NLP Series! From linguistic basics to cutting-edge research, you now have a comprehensive foundation in natural language processing. Continue exploring, building, and pushing the boundaries of what's possible with NLP.