Introduction to Generative Models
GPT (Generative Pre-trained Transformer) models represent a paradigm shift in NLP, demonstrating that large-scale autoregressive language models can learn to perform diverse tasks through in-context learning without task-specific fine-tuning.
Key Insight
GPT models predict the next token autoregressively, learning rich representations of language that enable few-shot and zero-shot learning across virtually any text-based task.
NLP Mastery
NLP Fundamentals & Linguistic Basics
Phonology, morphology, syntax, semantics, pragmaticsTokenization & Text Cleaning
Subword tokenization, BPE, stopwords, normalizationText Representation & Feature Engineering
Bag-of-words, TF-IDF, feature extraction, vectorizationWord Embeddings
Word2Vec, GloVe, FastText, embedding spaces, analogiesStatistical Language Models & N-grams
Probability chains, smoothing, perplexity, Markov modelsNeural Networks for NLP
Feedforward nets, backpropagation, activation functionsRNNs, LSTMs & GRUs
Sequence modeling, vanishing gradients, gated architecturesTransformers & Attention Mechanism
Self-attention, multi-head attention, positional encodingPretrained Language Models & Transfer Learning
BERT, RoBERTa, fine-tuning, feature extractionGPT Models & Text Generation
Autoregressive generation, prompting, GPT architectureCore NLP Tasks
NER, POS tagging, sentiment analysis, text classificationAdvanced NLP Tasks
Question answering, summarization, machine translationMultilingual & Cross-lingual NLP
mBERT, XLM-R, zero-shot transfer, language diversityEvaluation, Ethics & Responsible NLP
BLEU, ROUGE, bias detection, fairness, responsible AINLP Systems, Optimization & Production
Model serving, quantization, distillation, deploymentCutting-Edge & Research Topics
LLMs, multimodal NLP, reasoning, emerging researchAutoregressive Language Modeling
Autoregressive language modeling is the foundational approach behind GPT models, where text is generated one token at a time by predicting the next token based on all previous tokens. Unlike masked language models (BERT) that can see context from both directions, autoregressive models maintain a strict left-to-right generation process, making them naturally suited for text generation tasks.
The core mathematical formulation models the probability of a sequence as a product of conditional probabilities:
$$P(x_1, x_2, \ldots, x_T) = \prod_{t=1}^{T} P(x_t \mid x_1, \ldots, x_{t-1})$$
During training, the model learns to maximize the likelihood of predicting each token given its preceding context. This causal (unidirectional) attention mechanism ensures that predictions for position $i$ can only attend to positions less than $i$, preventing "peeking" at future tokens.

Autoregressive vs. Masked Language Models
Autoregressive (GPT): Predicts next token using only left context ? Natural for generation
Masked (BERT): Predicts masked tokens using bidirectional context ? Better for understanding
The autoregressive approach trades off bidirectional context for the ability to generate coherent, long-form text sequences naturally.
import torch
import torch.nn.functional as F
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load a pre-trained GPT-2 model and tokenizer
model_name = "gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set model to evaluation mode
model.eval()
# Example: Compute next-token probabilities
input_text = "The future of artificial intelligence"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# Get logits for next token prediction
with torch.no_grad():
outputs = model(input_ids)
next_token_logits = outputs.logits[:, -1, :] # Logits for last position
# Convert to probabilities
probs = F.softmax(next_token_logits, dim=-1)
# Get top 10 predicted tokens
top_k = 10
top_probs, top_indices = torch.topk(probs, top_k)
print(f"Input: '{input_text}'")
print(f"\nTop {top_k} predictions for next token:")
for i in range(top_k):
token = tokenizer.decode(top_indices[0][i])
prob = top_probs[0][i].item()
print(f" '{token}' - probability: {prob:.4f}")The autoregressive approach enables several key capabilities that make GPT models so powerful. First, it allows for arbitrary-length generation—the model can continue generating tokens indefinitely until a stop condition is met. Second, the training objective is simple and scalable: predict the next word given all previous words. Third, this formulation naturally handles variable-length inputs and outputs without requiring fixed sequence lengths during generation.
Understanding Causal Self-Attention
GPT uses causal (masked) self-attention where each position can only attend to earlier positions. This is implemented using a triangular attention mask:
import torch
import torch.nn.functional as F
def causal_self_attention(query, key, value, mask=None):
"""
Implements causal self-attention for autoregressive models.
Args:
query, key, value: Tensors of shape (batch, seq_len, d_model)
mask: Optional attention mask
"""
d_k = query.size(-1)
seq_len = query.size(1)
# Compute attention scores
scores = torch.matmul(query, key.transpose(-2, -1)) / (d_k ** 0.5)
# Create causal mask (lower triangular)
# This prevents attending to future positions
causal_mask = torch.tril(torch.ones(seq_len, seq_len))
causal_mask = causal_mask.unsqueeze(0).unsqueeze(0) # Add batch and head dims
# Apply mask: set future positions to -infinity
scores = scores.masked_fill(causal_mask == 0, float('-inf'))
# Apply softmax to get attention weights
attention_weights = F.softmax(scores, dim=-1)
# Compute weighted sum of values
output = torch.matmul(attention_weights, value)
return output, attention_weights
# Example usage
batch_size, seq_len, d_model = 1, 5, 64
q = k = v = torch.randn(batch_size, seq_len, d_model)
output, weights = causal_self_attention(q, k, v)
print("Attention weights (causal mask applied):")
print(weights[0, 0].detach().numpy().round(3))
print("\nNote: Each row shows attention to previous positions only")
print("Position 0 attends only to itself, position 4 attends to all positions")GPT Architecture Evolution
The GPT family represents a remarkable progression in language model capabilities, driven primarily by scaling model size, training data, and compute. Each generation introduced architectural refinements and demonstrated emergent capabilities that weren't present in smaller models. Understanding this evolution provides insight into how modern large language models achieve their impressive performance.

GPT-1: Generative Pre-Training
Released by OpenAI in 2018, GPT-1 introduced the paradigm of generative pre-training followed by discriminative fine-tuning. With 117 million parameters and 12 transformer layers, GPT-1 demonstrated that unsupervised pre-training on large text corpora (BooksCorpus, ~7,000 books) could produce representations useful for downstream tasks. The key innovation was showing that a single architecture could be fine-tuned for multiple tasks including natural language inference, question answering, and semantic similarity.
The architecture used a decoder-only transformer with learned positional embeddings, GELU activation functions, and byte-pair encoding (BPE) tokenization. GPT-1 established the "pre-train then fine-tune" paradigm that would dominate NLP for years, though it still required task-specific fine-tuning for each downstream application.
GPT-1 Key Specifications
Parameters: 117 million | Layers: 12 | Hidden Size: 768 | Attention Heads: 12
Training Data: BooksCorpus (~5GB) | Context Length: 512 tokens
Innovation: Demonstrated transfer learning from unsupervised pre-training to supervised tasks
GPT-2: Zero-Shot Task Transfer
GPT-2 (2019) scaled up to 1.5 billion parameters and introduced a crucial insight: with sufficient scale and diverse training data, language models could perform tasks zero-shot—without any fine-tuning or examples. Trained on WebText (40GB of web pages filtered for quality), GPT-2 demonstrated that tasks like summarization, translation, and question answering emerged naturally from the language modeling objective.
The paper "Language Models are Unsupervised Multitask Learners" showed that framing tasks as text completion allowed zero-shot transfer. For example, for translation: "Translate English to French: [English text] =" would generate the French translation. This discovery foreshadowed the prompt engineering techniques that would become central to using larger models.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
# Load GPT-2 (multiple sizes available: gpt2, gpt2-medium, gpt2-large, gpt2-xl)
model_name = "gpt2-medium" # 355M parameters
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
model.eval()
# Zero-shot task examples with GPT-2
tasks = [
# Translation (zero-shot)
"Translate English to French:\nEnglish: Hello, how are you?\nFrench:",
# Summarization (zero-shot)
"Summarize the following text:\nText: The quick brown fox jumps over the lazy dog. This sentence contains every letter of the alphabet and is often used for typing practice.\nSummary:",
# Question answering (zero-shot)
"Answer the question based on context.\nContext: Paris is the capital of France. It is known for the Eiffel Tower.\nQuestion: What is Paris known for?\nAnswer:",
]
def generate_completion(prompt, max_new_tokens=50):
"""Generate text completion for a prompt."""
input_ids = tokenizer.encode(prompt, return_tensors="pt")
with torch.no_grad():
output = model.generate(
input_ids,
max_new_tokens=max_new_tokens,
num_return_sequences=1,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.7,
top_p=0.9
)
generated = tokenizer.decode(output[0], skip_special_tokens=True)
return generated[len(prompt):] # Return only generated part
print("GPT-2 Zero-Shot Task Examples")
print("=" * 60)
for i, task in enumerate(tasks, 1):
print(f"\nTask {i}:")
print(f"Prompt: {task}")
print(f"Generated: {generate_completion(task, max_new_tokens=30)}")GPT-3 & In-Context Learning
GPT-3 (2020) marked a watershed moment with 175 billion parameters—over 100x larger than GPT-2. The landmark paper "Language Models are Few-Shot Learners" demonstrated in-context learning: the ability to learn new tasks from just a few examples provided in the prompt, without any gradient updates. This "few-shot" capability emerged purely from scale and training data diversity (300 billion tokens from filtered Common Crawl, books, and Wikipedia).
GPT-3 introduced the formal distinction between zero-shot, one-shot, and few-shot prompting. With few-shot examples, GPT-3 approached or exceeded fine-tuned model performance on many benchmarks. The model also exhibited surprising emergent capabilities including basic arithmetic, code generation, and complex reasoning—abilities not explicitly trained but arising from the language modeling objective at scale.
In-Context Learning: Few-Shot Prompting
In-context learning allows the model to learn task patterns from examples in the prompt:
from transformers import pipeline
import torch
# Using GPT-2 to demonstrate the concept (GPT-3 API works similarly)
# For actual GPT-3, use OpenAI API
generator = pipeline('text-generation', model='gpt2-large')
# Few-shot prompt structure
few_shot_prompt = """Classify the sentiment of the review.
Review: This movie was absolutely fantastic! Best film I've seen all year.
Sentiment: Positive
Review: Terrible waste of time. The acting was wooden and the plot made no sense.
Sentiment: Negative
Review: It was okay, nothing special but not bad either.
Sentiment: Neutral
Review: I loved every minute of this brilliant masterpiece!
Sentiment:"""
# Generate completion
result = generator(
few_shot_prompt,
max_new_tokens=5,
num_return_sequences=1,
temperature=0.3,
do_sample=True,
pad_token_id=50256 # GPT-2 EOS token
)
print("Few-Shot Sentiment Classification")
print("=" * 50)
print(result[0]['generated_text'])
# Zero-shot vs One-shot vs Few-shot comparison
print("\n" + "=" * 50)
print("Prompting Strategies Comparison:")
print("=" * 50)
strategies = {
"Zero-shot": "Classify sentiment: 'Great product!'\nSentiment:",
"One-shot": """Classify sentiment.
Example: 'Terrible!' -> Negative
Classify: 'Great product!' -> """,
"Few-shot": """Classify sentiment.
'Terrible!' -> Negative
'Amazing!' -> Positive
'It's fine' -> Neutral
'Great product!' ->"""
}
for strategy, prompt in strategies.items():
print(f"\n{strategy}:")
print(f"Prompt structure: {prompt[:60]}...")GPT-4 & Beyond
GPT-4 (2023) represented another significant leap, though OpenAI disclosed fewer technical details. GPT-4 demonstrated substantially improved reasoning, reduced hallucination, and notably introduced multimodal capabilities—accepting both text and images as input. On professional benchmarks like the bar exam and medical licensing tests, GPT-4 scored in the top percentiles, suggesting human-level performance on many complex reasoning tasks.
The GPT-4 era also brought important developments in safety and alignment. Extensive red-teaming, RLHF (Reinforcement Learning from Human Feedback), and constitutional AI techniques made GPT-4 more helpful, harmless, and honest than predecessors. The model showed improved instruction-following, better calibration of uncertainty, and reduced tendency to produce harmful or false content.
GPT Model Evolution Summary
| Model | Year | Parameters | Key Innovation |
|---|---|---|---|
| GPT-1 | 2018 | 117M | Pre-train ? Fine-tune paradigm |
| GPT-2 | 2019 | 1.5B | Zero-shot task transfer |
| GPT-3 | 2020 | 175B | In-context learning, few-shot |
| GPT-4 | 2023 | ~1.7T* | Multimodal, improved reasoning |
*GPT-4 size is estimated; OpenAI hasn't confirmed exact parameters
# Working with OpenAI API (GPT-3.5/GPT-4)
# pip install openai
from openai import OpenAI
import os
# Initialize client (set OPENAI_API_KEY environment variable)
# client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# Example API call structure for GPT-4
def call_gpt4(prompt, system_message="You are a helpful assistant."):
"""
Example function to call GPT-4 API.
Requires valid OpenAI API key.
"""
# Uncomment to use with valid API key:
# response = client.chat.completions.create(
# model="gpt-4",
# messages=[
# {"role": "system", "content": system_message},
# {"role": "user", "content": prompt}
# ],
# temperature=0.7,
# max_tokens=500
# )
# return response.choices[0].message.content
# Placeholder for demonstration
return f"[GPT-4 response to: {prompt[:50]}...]"
# Example prompts showcasing GPT-4 capabilities
examples = {
"Complex Reasoning": """
If all bloops are razzies and all razzies are lazzies,
are all bloops definitely lazzies? Explain your reasoning step by step.
""",
"Code Generation": """
Write a Python function that finds the longest palindromic
substring in a given string using dynamic programming.
""",
"Creative Writing": """
Write a haiku about machine learning that captures both
its technical nature and philosophical implications.
"""
}
print("GPT-4 Capability Examples")
print("=" * 60)
for capability, prompt in examples.items():
print(f"\n{capability}:")
print(f"Prompt: {prompt.strip()[:60]}...")
print(f"Response: {call_gpt4(prompt)}")GPT Building Blocks: Inside a Transformer Block
Understanding GPT's power requires looking inside its Transformer blocks. Each block is a precisely engineered stack of components: Layer Normalization, Multi-Head Causal Self-Attention, a Feed-Forward Network with GELU activation, and residual connections. Let's examine each component and how they compose.
Layer Normalization (Pre-Norm)
GPT-2 and all modern GPT variants use Pre-LayerNorm — normalizing inputs before each sub-layer rather than after. LayerNorm normalizes across the feature dimension (not the batch dimension like BatchNorm), making it independent of batch size and suitable for variable-length sequences. The normalization stabilizes activations and enables training of very deep networks (GPT-3 has 96 layers).
$$\text{LayerNorm}(x) = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta$$Where $\mu$ and $\sigma^2$ are the mean and variance computed across the feature dimension for each token independently, and $\gamma$, $\beta$ are learnable scale and shift parameters.
import torch
import torch.nn as nn
# LayerNorm: normalize across features for EACH token independently
batch_size, seq_len, d_model = 2, 5, 768
x = torch.randn(batch_size, seq_len, d_model)
# PyTorch's built-in LayerNorm
layer_norm = nn.LayerNorm(d_model)
# Manual implementation to show what's happening
def manual_layer_norm(x, eps=1e-5):
# Compute mean and variance across last dimension (features)
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
# Normalize
x_norm = (x - mean) / torch.sqrt(var + eps)
return x_norm
# Compare
auto_result = layer_norm(x)
manual_result = manual_layer_norm(x)
# They match (ignoring learned gamma/beta which start as 1/0)
print(f"Input shape: {x.shape}")
print(f"After LayerNorm: {auto_result.shape}")
print(f"Each token normalized independently:")
print(f" Token [0,0] mean: {auto_result[0, 0].mean().item():.6f} (should be ~0)")
print(f" Token [0,0] std: {auto_result[0, 0].std().item():.4f} (should be ~1)")
print(f" Token [0,3] mean: {auto_result[0, 3].mean().item():.6f}")
print(f" Token [0,3] std: {auto_result[0, 3].std().item():.4f}")
print(f"\nNote: BatchNorm normalizes across batch, LayerNorm across features")
print(f" This makes LayerNorm batch-size independent (works with batch=1)")
The Feed-Forward Network with GELU
After attention aggregates information across tokens, the feed-forward network (FFN) transforms each token's representation independently. The FFN expands to 4x the model dimension, applies GELU activation, then projects back down. This "expand-activate-contract" pattern gives each token more capacity to compute complex features:
$$\text{FFN}(x) = \text{GELU}(xW_1 + b_1)W_2 + b_2$$Where $W_1 \in \mathbb{R}^{d_{model} \times 4 \cdot d_{model}}$ expands the representation and $W_2 \in \mathbb{R}^{4 \cdot d_{model} \times d_{model}}$ projects it back. The 4x expansion ratio is used in GPT-2, GPT-3, BERT, and most Transformers.
import torch
import torch.nn as nn
class GPTBlock(nn.Module):
"""A single GPT-2 style Transformer block with Pre-LayerNorm."""
def __init__(self, d_model=768, n_heads=12, dropout=0.1):
super().__init__()
# Pre-LayerNorm before each sub-layer
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
# Multi-head causal self-attention
self.attn = nn.MultiheadAttention(
embed_dim=d_model, num_heads=n_heads,
dropout=dropout, batch_first=True
)
# Feed-Forward Network: expand 4x, GELU, contract back
self.ffn = nn.Sequential(
nn.Linear(d_model, 4 * d_model),
nn.GELU(),
nn.Linear(4 * d_model, d_model),
nn.Dropout(dropout),
)
def forward(self, x, attn_mask=None):
# Sub-layer 1: Pre-Norm -> Attention -> Residual
x_norm = self.ln1(x)
attn_out, _ = self.attn(x_norm, x_norm, x_norm, attn_mask=attn_mask)
x = x + attn_out # Residual connection
# Sub-layer 2: Pre-Norm -> FFN -> Residual
x_norm = self.ln2(x)
ffn_out = self.ffn(x_norm)
x = x + ffn_out # Residual connection
return x
# Build a mini GPT (similar to GPT-2 small)
d_model = 768
n_layers = 12
block = GPTBlock(d_model=d_model, n_heads=12)
# Count parameters in one block
block_params = sum(p.numel() for p in block.parameters())
print(f"One GPT block: {block_params:,} parameters")
print(f"Full GPT-2 (12 blocks): ~{block_params * n_layers:,} parameters (blocks only)")
print(f"\nArchitecture:")
print(f" d_model = {d_model}")
print(f" FFN inner dim = {4 * d_model}")
print(f" n_heads = 12 (head_dim = {d_model // 12})")
print(f"\nForward pass:")
x = torch.randn(2, 10, d_model) # batch=2, seq=10
# Create causal mask
seq_len = 10
causal_mask = torch.triu(torch.ones(seq_len, seq_len) * float('-inf'), diagonal=1)
out = block(x, attn_mask=causal_mask)
print(f" Input: {x.shape}")
print(f" Output: {out.shape}")
GPT Architecture Summary (Decoder-Only)
GPT models are decoder-only Transformers. Unlike the original Transformer (encoder + decoder), GPT uses only the decoder stack with causal masking. The full architecture is: Token Embedding + Position Embedding → N × [LayerNorm → Causal Self-Attention → Residual → LayerNorm → FFN → Residual] → LayerNorm → Linear (vocab logits). The final linear layer projects back to vocabulary size, producing logits over the next token. This is called the language model head.
Decoding Strategies
Decoding strategies determine how we select tokens from the model's predicted probability distribution during text generation. The choice of decoding method dramatically affects output quality—whether it's coherent, diverse, creative, or deterministic. Understanding these strategies is crucial for getting optimal results from any language model.
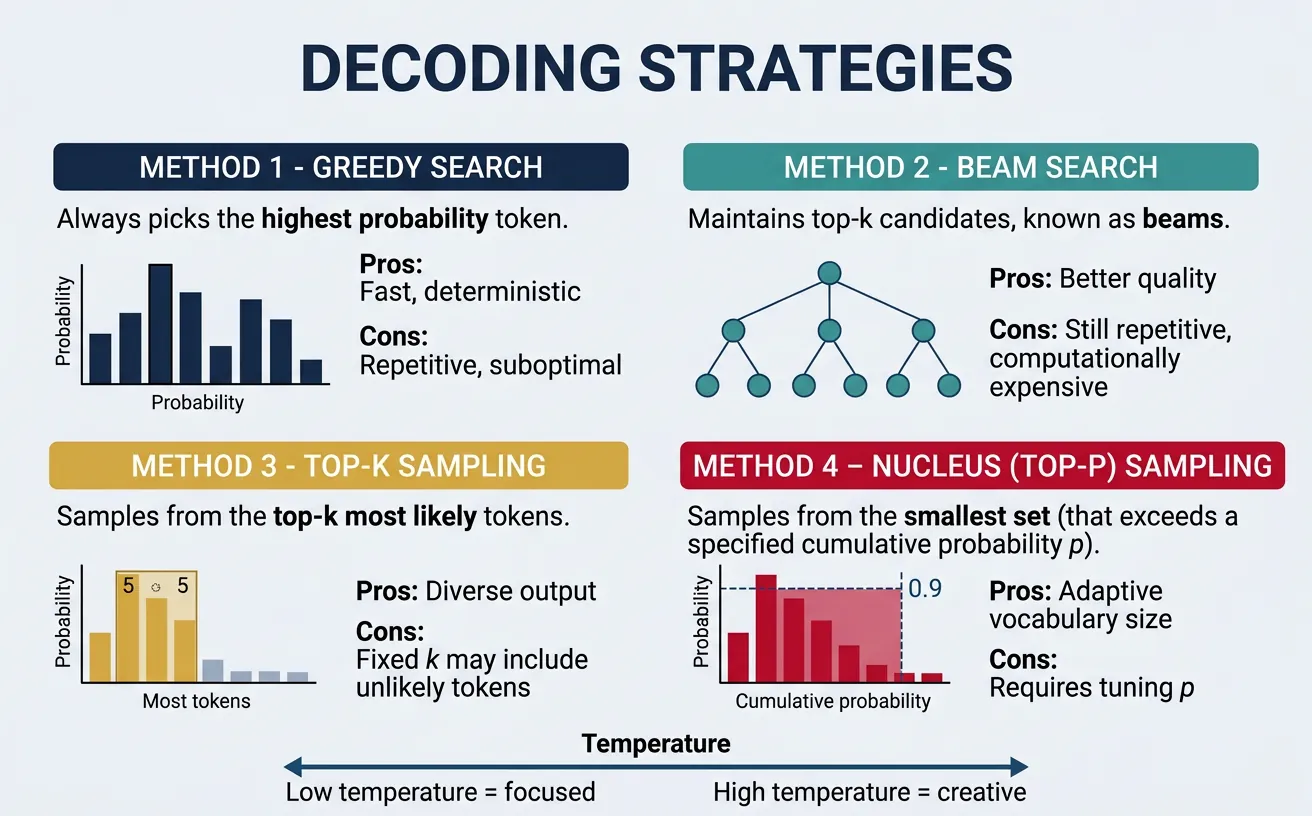
Greedy & Beam Search
Greedy decoding is the simplest strategy: at each step, select the token with the highest probability. While fast and deterministic, greedy decoding often produces repetitive, generic text because it always chooses the "safe" option. It can also lead to suboptimal global solutions—a locally optimal choice at each step doesn't guarantee the best overall sequence.
Beam search addresses greedy decoding's limitations by maintaining multiple candidate sequences (beams) at each step. Instead of committing to one token, beam search tracks the top-k most probable sequences and selects the best complete sequence at the end. While beam search produces more coherent text than greedy decoding, it can still suffer from repetition and lack of diversity, particularly for open-ended generation tasks.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
# Load model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
model.eval()
prompt = "The secret to happiness is"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
print("Decoding Strategy Comparison")
print("=" * 60)
print(f"Prompt: '{prompt}'")
print()
# 1. Greedy Decoding
print("1. GREEDY DECODING")
print("-" * 40)
greedy_output = model.generate(
input_ids,
max_new_tokens=40,
do_sample=False, # Greedy: no sampling
pad_token_id=tokenizer.eos_token_id
)
print(f"Output: {tokenizer.decode(greedy_output[0], skip_special_tokens=True)}")
print()
# 2. Beam Search
print("2. BEAM SEARCH (num_beams=5)")
print("-" * 40)
beam_output = model.generate(
input_ids,
max_new_tokens=40,
num_beams=5, # Consider top 5 sequences at each step
early_stopping=True,
no_repeat_ngram_size=2, # Prevent repetition
pad_token_id=tokenizer.eos_token_id
)
print(f"Output: {tokenizer.decode(beam_output[0], skip_special_tokens=True)}")
print()
# 3. Beam Search with multiple outputs
print("3. BEAM SEARCH (multiple sequences)")
print("-" * 40)
beam_outputs = model.generate(
input_ids,
max_new_tokens=30,
num_beams=5,
num_return_sequences=3, # Return top 3 beams
early_stopping=True,
no_repeat_ngram_size=2,
pad_token_id=tokenizer.eos_token_id
)
for i, output in enumerate(beam_outputs):
print(f"Beam {i+1}: {tokenizer.decode(output, skip_special_tokens=True)}")The Repetition Problem
Both greedy decoding and beam search often produce repetitive text. Common solutions include:
- no_repeat_ngram_size: Prevent repeating n-grams
- repetition_penalty: Penalize tokens that have already appeared
- Sampling methods: Add randomness to token selection
Temperature & Top-k/Top-p Sampling
Sampling-based decoding introduces controlled randomness to generate more diverse and creative text. Instead of always picking the most likely token, we sample from the probability distribution. The key parameters that control this randomness are temperature, top-k, and top-p (nucleus sampling).
Temperature controls the "sharpness" of the probability distribution. Lower temperatures (e.g., 0.3) make the distribution peakier, favoring high-probability tokens and producing more focused, deterministic output. Higher temperatures (e.g., 1.5) flatten the distribution, giving lower-probability tokens more chance and producing more creative, sometimes chaotic output. Temperature of 1.0 leaves probabilities unchanged.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
import torch.nn.functional as F
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
model.eval()
def visualize_temperature_effect(logits, temperatures=[0.3, 0.7, 1.0, 1.5, 2.0]):
"""Show how temperature affects probability distribution."""
print("Temperature Effect on Probability Distribution")
print("=" * 60)
for temp in temperatures:
# Apply temperature scaling
scaled_logits = logits / temp
probs = F.softmax(scaled_logits, dim=-1)
# Get top 5 tokens
top_probs, top_indices = torch.topk(probs, 5)
print(f"\nTemperature = {temp}:")
print(f" Top token prob: {top_probs[0][0].item():.4f}")
print(f" Distribution entropy: {(-probs * torch.log(probs + 1e-10)).sum().item():.4f}")
tokens_probs = [(tokenizer.decode(idx), p.item())
for idx, p in zip(top_indices[0], top_probs[0])]
print(f" Top 5: {tokens_probs}")
# Get logits for a prompt
prompt = "The meaning of life is"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model(input_ids)
logits = outputs.logits[:, -1, :] # Last position logits
visualize_temperature_effect(logits)Top-k sampling restricts sampling to the k most likely tokens, setting all other probabilities to zero before renormalizing. This prevents sampling very unlikely tokens while maintaining diversity. Top-p (nucleus) sampling is more adaptive: it selects the smallest set of tokens whose cumulative probability exceeds p (e.g., 0.9). This means the number of considered tokens varies—fewer for confident predictions, more when the model is uncertain.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
model.eval()
prompt = "In a world where robots dream,"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
print("Sampling Strategy Comparison")
print("=" * 60)
print(f"Prompt: '{prompt}'")
print()
# Pure sampling with different temperatures
print("1. TEMPERATURE SAMPLING")
print("-" * 40)
for temp in [0.3, 0.7, 1.0, 1.5]:
output = model.generate(
input_ids,
max_new_tokens=30,
do_sample=True,
temperature=temp,
pad_token_id=tokenizer.eos_token_id
)
print(f"T={temp}: {tokenizer.decode(output[0], skip_special_tokens=True)}")
print()
# Top-k sampling
print("2. TOP-K SAMPLING")
print("-" * 40)
for k in [10, 50, 100]:
output = model.generate(
input_ids,
max_new_tokens=30,
do_sample=True,
top_k=k,
temperature=1.0,
pad_token_id=tokenizer.eos_token_id
)
print(f"k={k}: {tokenizer.decode(output[0], skip_special_tokens=True)}")
print()
# Top-p (nucleus) sampling
print("3. TOP-P (NUCLEUS) SAMPLING")
print("-" * 40)
for p in [0.5, 0.9, 0.95]:
output = model.generate(
input_ids,
max_new_tokens=30,
do_sample=True,
top_p=p,
temperature=1.0,
pad_token_id=tokenizer.eos_token_id
)
print(f"p={p}: {tokenizer.decode(output[0], skip_special_tokens=True)}")Recommended Sampling Configurations
| Use Case | Temperature | Top-p | Top-k |
|---|---|---|---|
| Factual/Deterministic (Q&A, code) | 0.1-0.3 | 0.9 | - |
| Balanced (summaries, analysis) | 0.5-0.7 | 0.9 | - |
| Creative (stories, poetry) | 0.8-1.0 | 0.95 | 50 |
| Brainstorming (diverse ideas) | 1.0-1.2 | 0.95 | 100 |
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch
tokenizer = GPT2Tokenizer.from_pretrained("gpt2-medium")
model = GPT2LMHeadModel.from_pretrained("gpt2-medium")
model.eval()
def generate_with_config(prompt, config_name, **kwargs):
"""Generate text with specific configuration."""
input_ids = tokenizer.encode(prompt, return_tensors="pt")
output = model.generate(
input_ids,
max_new_tokens=50,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
**kwargs
)
return tokenizer.decode(output[0], skip_special_tokens=True)
# Production-ready configurations
configs = {
"Factual/Precise": {
"do_sample": True,
"temperature": 0.2,
"top_p": 0.9,
},
"Balanced": {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.9,
},
"Creative": {
"do_sample": True,
"temperature": 0.9,
"top_p": 0.95,
"top_k": 50,
},
"Highly Creative": {
"do_sample": True,
"temperature": 1.2,
"top_p": 0.95,
"top_k": 100,
}
}
prompt = "The future of artificial intelligence will"
print("Configuration Comparison")
print("=" * 60)
print(f"Prompt: '{prompt}'")
print()
for config_name, params in configs.items():
print(f"{config_name}:")
print(f" Settings: T={params.get('temperature')}, p={params.get('top_p')}, k={params.get('top_k', '-')}")
result = generate_with_config(prompt, config_name, **params)
print(f" Output: {result}")
print()Prompt Engineering
Prompt engineering is the art and science of crafting inputs that elicit desired outputs from language models. As models have grown larger and more capable, prompt engineering has become a crucial skill—often the difference between mediocre and exceptional results lies entirely in how you frame the request. Effective prompts leverage the model's in-context learning abilities to guide it toward accurate, relevant, and well-formatted responses.
The fundamental insight behind prompt engineering is that GPT models are completion engines: they predict what text should follow a given input. By carefully structuring that input—providing context, examples, constraints, and role definitions—we can steer the model toward specific behaviors without any retraining. This makes prompt engineering both powerful and accessible to non-ML practitioners.
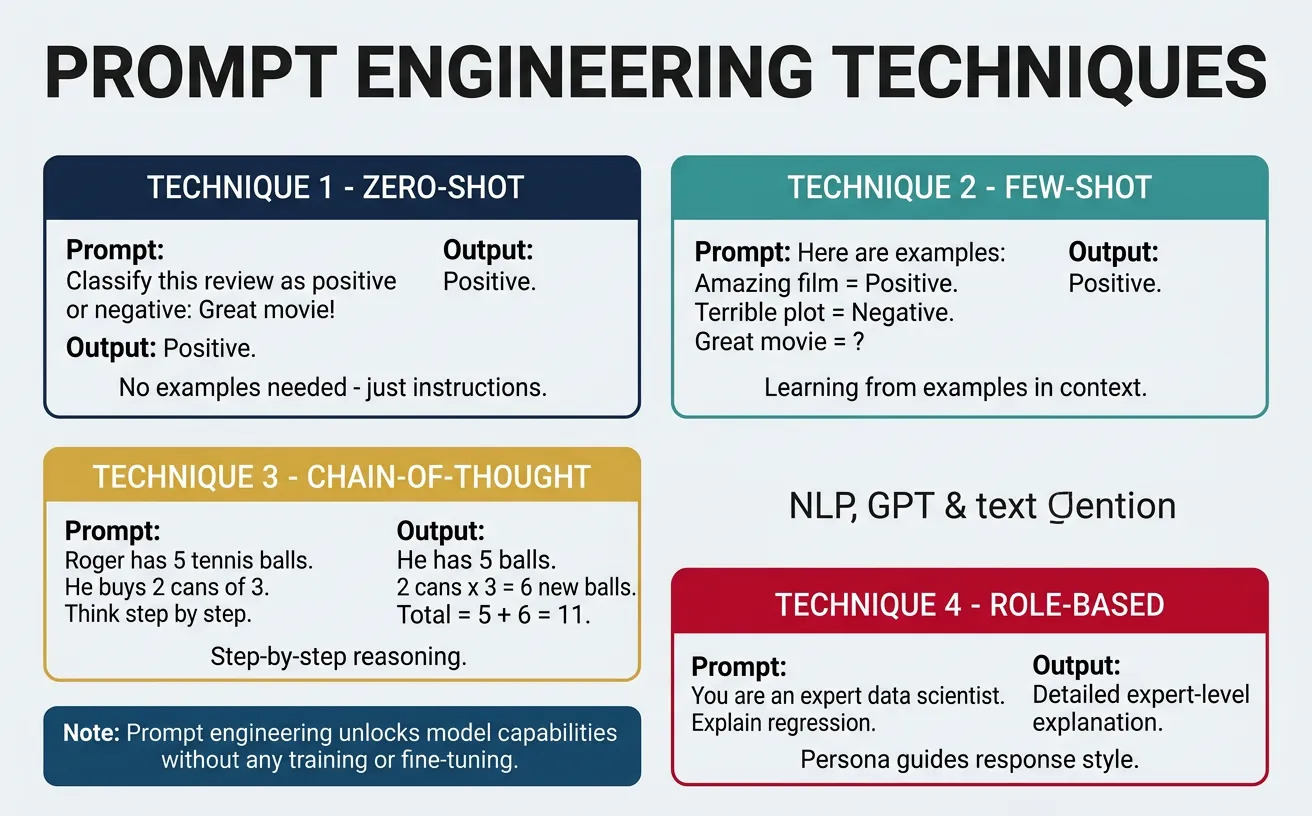
Core Prompt Engineering Principles
- Be specific: Vague prompts yield vague responses
- Provide context: Give the model relevant background information
- Use examples: Few-shot prompting dramatically improves accuracy
- Define the role: "You are an expert X" primes appropriate behavior
- Specify format: Explicitly request JSON, bullet points, etc.
- Think step-by-step: Chain-of-thought prompting improves reasoning
# Prompt Engineering Techniques
# These examples demonstrate patterns applicable to any GPT-family model
# 1. BASIC PROMPTING PATTERNS
basic_prompts = {
# Bad: vague, no context
"vague": "Write about AI.",
# Good: specific, contextual, structured
"specific": """Write a 200-word blog post introduction about how AI
is transforming healthcare diagnostics. Target audience: healthcare
professionals with limited technical background. Include one specific
example of an AI diagnostic tool.""",
}
# 2. ROLE-BASED PROMPTING
role_prompts = {
"teacher": """You are an experienced computer science professor
known for clear, intuitive explanations.
Explain recursion to a student who understands loops but hasn't
seen recursion before. Use a real-world analogy.""",
"code_reviewer": """You are a senior software engineer performing
a code review. Be constructive but thorough.
Review this code for bugs, style issues, and potential improvements:
```python
def fib(n):
if n <= 1: return n
return fib(n-1) + fib(n-2)
```""",
}
# 3. FEW-SHOT PROMPTING (with examples)
few_shot_prompt = """Convert natural language to SQL queries.
Example 1:
Natural: Show all users older than 25
SQL: SELECT * FROM users WHERE age > 25;
Example 2:
Natural: Count products in electronics category
SQL: SELECT COUNT(*) FROM products WHERE category = 'electronics';
Example 3:
Natural: Get the top 5 highest-paid employees
SQL: SELECT * FROM employees ORDER BY salary DESC LIMIT 5;
Convert:
Natural: Find users who registered in 2024
SQL:"""
# 4. CHAIN-OF-THOUGHT (CoT) PROMPTING
cot_prompt = """Solve this step by step:
Question: A store sells apples for $2 each and oranges for $3 each.
If John buys 5 apples and 3 oranges, and pays with a $20 bill,
how much change does he receive?
Let me solve this step by step:
1. First, calculate the cost of apples: 5 apples × $2 = $10
2. Then, calculate the cost of oranges: 3 oranges × $3 = $9
3. Add up the total cost: $10 + $9 = $19
4. Calculate the change: $20 - $19 = $1
Answer: John receives $1 in change.
Now solve this problem step by step:
Question: A bookstore has a "buy 2 get 1 free" deal on novels.
Each novel costs $15. If Sarah wants 7 novels, how much will she pay?
Let me solve this step by step:"""
print("Prompt Engineering Examples")
print("=" * 60)
print("\n1. Specific vs Vague Prompts:")
print(f" Vague: {basic_prompts['vague']}")
print(f" Specific: {basic_prompts['specific'][:80]}...")
print("\n2. Few-Shot Pattern (SQL generation):")
print(f" {few_shot_prompt[:200]}...")
print("\n3. Chain-of-Thought Pattern:")
print(f" Structured reasoning encourages the model to show work")Advanced Prompting Techniques
# ADVANCED PROMPTING TECHNIQUES
# 1. SELF-CONSISTENCY: Generate multiple responses, pick majority
self_consistency_prompt = """Answer the following question. Show your reasoning.
Question: If a train travels at 60 mph for 2.5 hours, then at 80 mph
for 1.5 hours, what is the total distance traveled?
[Generate this prompt multiple times with temperature > 0,
then select the most common answer]"""
# 2. TREE OF THOUGHTS: Explore multiple reasoning paths
tot_prompt = """For the following problem, consider 3 different
approaches before selecting the best one.
Problem: How can we reduce plastic waste in oceans?
Approach 1: [Think about technological solutions]
Approach 2: [Think about policy/regulation solutions]
Approach 3: [Think about behavioral/educational solutions]
Now evaluate each approach and synthesize the best elements."""
# 3. STRUCTURED OUTPUT PROMPTS
structured_prompt = """Analyze the following product review and return
a JSON object with the following structure:
{
"sentiment": "positive" | "negative" | "neutral",
"confidence": 0.0-1.0,
"key_points": ["point1", "point2"],
"product_aspects": {
"quality": "mentioned positively/negatively/not mentioned",
"price": "mentioned positively/negatively/not mentioned",
"service": "mentioned positively/negatively/not mentioned"
}
}
Review: "Great laptop! Fast performance and beautiful screen.
A bit pricey but worth every penny. Shipping was delayed though."
JSON:"""
# 4. CONTRASTIVE PROMPTING
contrastive_prompt = """I will show you examples of formal and informal
email responses. Learn the pattern, then write a formal response.
INFORMAL: "Hey! Sure thing, I'll get that report to you by Friday.
No worries! Catch you later!"
FORMAL: "Dear Mr. Johnson, Thank you for your inquiry. I will ensure
the report is delivered by Friday, January 24th. Please do not
hesitate to reach out if you require any further assistance.
Best regards, [Name]"
Now write a FORMAL response to this message:
"yo, can u send me the meeting notes from yesterday? thx"
FORMAL:"""
# 5. PERSONA + CONSTRAINT COMBINATION
complex_prompt = """You are a children's book author who specializes
in making complex topics accessible to 8-year-olds.
CONSTRAINTS:
- Use simple vocabulary (grade 3 reading level)
- Include one fun analogy
- Keep the explanation under 100 words
- End with an engaging question for the child
TOPIC: Explain how the internet works.
RESPONSE:"""
print("Advanced Prompting Techniques")
print("=" * 60)
print("\n1. Self-Consistency: Multiple samples ? majority vote")
print("2. Tree of Thoughts: Explore multiple reasoning paths")
print("3. Structured Output: Enforce JSON/specific format")
print("4. Contrastive Prompting: Show what TO do and NOT to do")
print("5. Persona + Constraints: Role + specific requirements")from transformers import pipeline
import torch
# Practical prompt engineering with Hugging Face
generator = pipeline('text-generation', model='gpt2-large')
def generate_with_prompt(prompt, max_length=200):
"""Generate completion with formatting."""
result = generator(
prompt,
max_new_tokens=100,
temperature=0.7,
top_p=0.9,
do_sample=True,
num_return_sequences=1,
pad_token_id=50256
)
return result[0]['generated_text']
# PROMPT TEMPLATE LIBRARY
class PromptTemplate:
"""Reusable prompt templates for common tasks."""
@staticmethod
def summarization(text, style="concise"):
styles = {
"concise": "Summarize in 1-2 sentences:",
"detailed": "Provide a detailed summary covering all key points:",
"bullet": "Summarize as bullet points:"
}
return f"{styles[style]}\n\nText: {text}\n\nSummary:"
@staticmethod
def classification(text, categories):
category_list = ", ".join(categories)
return f"""Classify the following text into one of these categories: {category_list}
Text: {text}
Category:"""
@staticmethod
def extraction(text, fields):
field_list = ", ".join(fields)
return f"""Extract the following information from the text: {field_list}
Text: {text}
Extracted information:"""
@staticmethod
def code_generation(description, language="Python"):
return f"""Write {language} code for the following task:
Task: {description}
Requirements:
- Include comments explaining the code
- Handle edge cases
- Follow best practices
{language} code:
```{language.lower()}
"""
# Example usage
text = "Apple announced a new iPhone today with improved camera and battery."
print("Prompt Template Examples")
print("=" * 60)
# Summarization
print("\n1. SUMMARIZATION:")
prompt = PromptTemplate.summarization(text)
print(f"Prompt: {prompt}")
# Classification
print("\n2. CLASSIFICATION:")
prompt = PromptTemplate.classification(text, ["Technology", "Sports", "Politics"])
print(f"Prompt: {prompt}")
# Extraction
print("\n3. EXTRACTION:")
prompt = PromptTemplate.extraction(text, ["Company", "Product", "Features"])
print(f"Prompt: {prompt}")
# Code generation
print("\n4. CODE GENERATION:")
prompt = PromptTemplate.code_generation("Calculate the factorial of a number")
print(f"Prompt: {prompt}")RLHF & Alignment
Reinforcement Learning from Human Feedback (RLHF) is the key technique that transforms raw language models into helpful, harmless, and honest assistants. While pre-training teaches models to predict text, RLHF aligns model behavior with human preferences and values. This process was crucial in developing ChatGPT, GPT-4, and Claude—making them safe and useful for real-world applications.
The RLHF pipeline consists of three main stages: (1) Supervised Fine-Tuning (SFT) on human demonstrations of desired behavior, (2) Reward Model Training to learn human preferences from comparisons, and (3) Reinforcement Learning (typically PPO) to optimize the language model against the reward model while maintaining similarity to the original model.
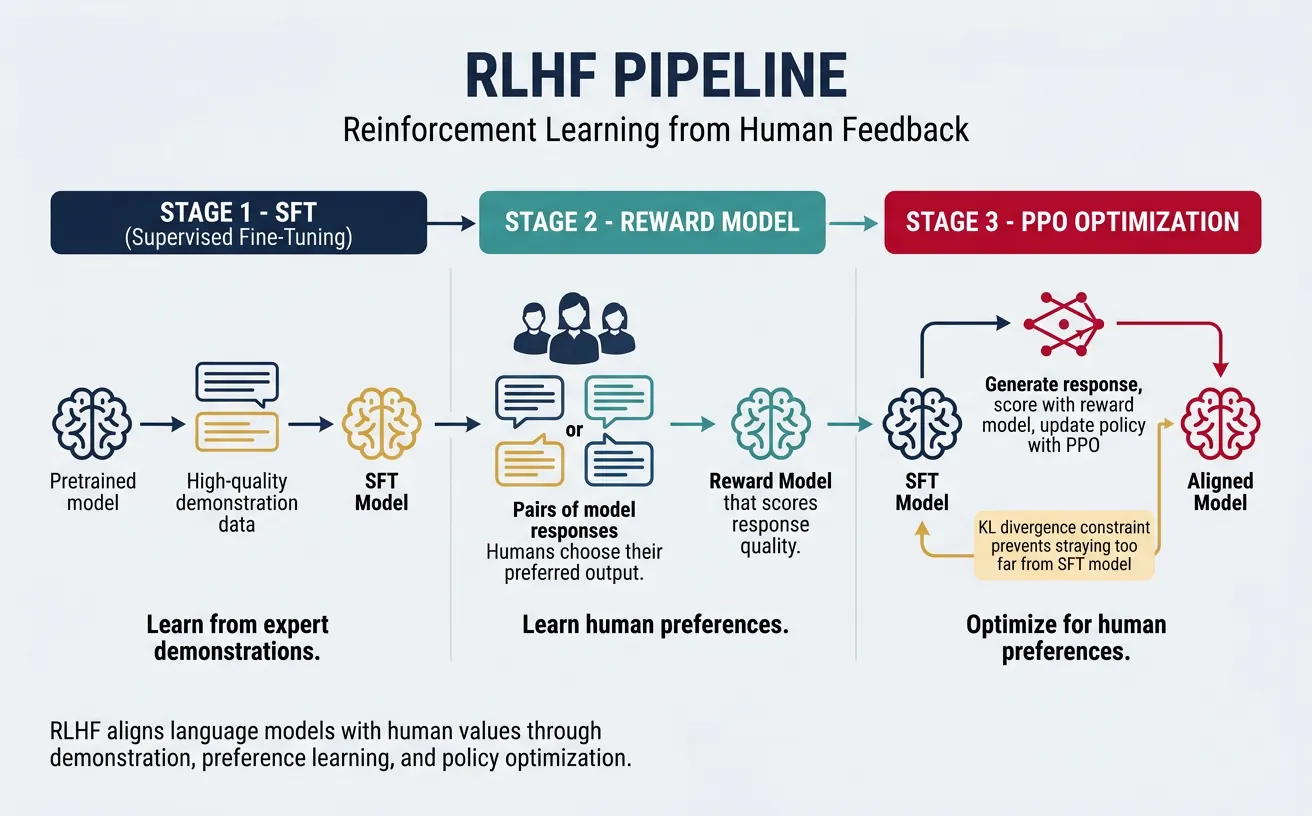
Why RLHF Matters
Pre-trained language models optimize for predicting likely text, not for being helpful or truthful. RLHF teaches models to:
- Follow instructions accurately
- Refuse harmful requests appropriately
- Acknowledge uncertainty instead of fabricating answers
- Provide balanced, thoughtful responses
# RLHF Conceptual Implementation
# This demonstrates the RLHF training loop structure
import torch
import torch.nn as nn
import torch.nn.functional as F
class RewardModel(nn.Module):
"""
Reward model that scores responses based on human preferences.
In practice, this is trained on human comparison data.
"""
def __init__(self, base_model_hidden_size=768):
super().__init__()
self.score_head = nn.Linear(base_model_hidden_size, 1)
def forward(self, hidden_states):
"""
Args:
hidden_states: Final hidden states from language model
Returns:
Scalar reward score
"""
# Use the last token's hidden state for scoring
last_hidden = hidden_states[:, -1, :]
reward = self.score_head(last_hidden)
return reward
def compute_reward_model_loss(reward_model, preferred_hidden, rejected_hidden):
"""
Train reward model using human preference pairs.
The model learns to assign higher scores to preferred responses.
Loss: -log(sigmoid(r_preferred - r_rejected))
"""
preferred_reward = reward_model(preferred_hidden)
rejected_reward = reward_model(rejected_hidden)
# Bradley-Terry pairwise ranking loss
loss = -F.logsigmoid(preferred_reward - rejected_reward).mean()
return loss
# PPO Training Loop Structure (Conceptual)
def rlhf_training_step(policy_model, reward_model, reference_model,
prompt_batch, kl_coeff=0.1):
"""
Single RLHF training step using PPO.
Key components:
1. Generate responses using current policy
2. Score responses with reward model
3. Compute KL penalty to prevent divergence from reference
4. Update policy using PPO objective
"""
# Generate responses from current policy
# responses = policy_model.generate(prompt_batch)
# Get rewards from reward model
# rewards = reward_model(responses)
# Compute KL divergence from reference model (regularization)
# policy_logprobs = policy_model.log_probs(responses)
# reference_logprobs = reference_model.log_probs(responses)
# kl_penalty = policy_logprobs - reference_logprobs
# Final reward = reward - kl_coeff * kl_penalty
# This prevents the policy from diverging too far from the original model
# PPO update using advantage estimation
# ...
print("RLHF Training Step Components:")
print("1. Generate responses from policy")
print("2. Score with reward model")
print("3. Compute KL penalty for regularization")
print("4. Update policy with PPO")
return None # Placeholder
print("RLHF Pipeline Overview")
print("=" * 60)
print("\nStage 1: Supervised Fine-Tuning (SFT)")
print(" - Train on human demonstrations")
print(" - Learn basic instruction-following")
print("\nStage 2: Reward Model Training")
print(" - Collect human comparisons (A vs B)")
print(" - Train model to predict human preference")
print("\nStage 3: PPO Optimization")
print(" - Generate responses")
print(" - Score with reward model")
print(" - Update policy with KL constraint")
rlhf_training_step(None, None, None, None)Direct Preference Optimization (DPO)
DPO is a newer technique that achieves similar alignment results without training a separate reward model or using RL. It directly optimizes the language model on preference data.
import torch
import torch.nn.functional as F
def dpo_loss(policy_model, reference_model,
preferred_responses, rejected_responses, beta=0.1):
"""
Direct Preference Optimization loss.
DPO bypasses reward modeling by implicitly defining the reward
as the log probability ratio between policy and reference models.
Args:
policy_model: Model being trained
reference_model: Frozen reference model
preferred_responses: Human-preferred responses
rejected_responses: Human-rejected responses
beta: Temperature parameter controlling strength of preference
"""
# Get log probabilities from policy model
policy_preferred_logps = get_log_probs(policy_model, preferred_responses)
policy_rejected_logps = get_log_probs(policy_model, rejected_responses)
# Get log probabilities from reference model (frozen)
with torch.no_grad():
ref_preferred_logps = get_log_probs(reference_model, preferred_responses)
ref_rejected_logps = get_log_probs(reference_model, rejected_responses)
# Compute log ratios
preferred_ratio = policy_preferred_logps - ref_preferred_logps
rejected_ratio = policy_rejected_logps - ref_rejected_logps
# DPO loss: -log(sigmoid(beta * (preferred_ratio - rejected_ratio)))
loss = -F.logsigmoid(beta * (preferred_ratio - rejected_ratio)).mean()
return loss
def get_log_probs(model, sequences):
"""Placeholder: compute log probabilities of sequences."""
# In practice: forward pass + gather log probs at token positions
return torch.zeros(len(sequences))
print("DPO Advantages over RLHF:")
print("=" * 50)
print("? No separate reward model training")
print("? No RL (PPO) instability issues")
print("? Simpler implementation")
print("? Similar performance to RLHF")
print("? More computationally efficient")Practical Implementation
This section provides complete, production-ready code for text generation using various models and configurations. All examples are designed to be copy-paste executable and demonstrate best practices for working with GPT models in real applications.
# Complete Text Generation Pipeline
# pip install transformers torch accelerate
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
pipeline,
set_seed
)
import torch
class TextGenerator:
"""
Production-ready text generation class with multiple
decoding strategies and configurations.
"""
def __init__(self, model_name="gpt2-medium", device=None):
"""
Initialize the text generator.
Args:
model_name: HuggingFace model identifier
device: 'cuda', 'cpu', or None for auto-detect
"""
self.device = device or ("cuda" if torch.cuda.is_available() else "cpu")
print(f"Loading model {model_name} on {self.device}...")
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16 if self.device == "cuda" else torch.float32
).to(self.device)
# Set pad token if not present (common for GPT models)
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
self.model.eval()
print("Model loaded successfully!")
def generate(self, prompt, max_new_tokens=100,
strategy="balanced", **kwargs):
"""
Generate text with predefined strategies.
Args:
prompt: Input text to continue
max_new_tokens: Maximum tokens to generate
strategy: 'greedy', 'beam', 'balanced', 'creative', 'precise'
"""
# Predefined generation configurations
strategies = {
"greedy": {
"do_sample": False,
},
"beam": {
"do_sample": False,
"num_beams": 5,
"early_stopping": True,
},
"precise": {
"do_sample": True,
"temperature": 0.3,
"top_p": 0.9,
},
"balanced": {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.9,
},
"creative": {
"do_sample": True,
"temperature": 1.0,
"top_p": 0.95,
"top_k": 50,
}
}
config = strategies.get(strategy, strategies["balanced"])
config.update(kwargs) # Allow overrides
# Encode input
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.device)
# Generate
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=max_new_tokens,
pad_token_id=self.tokenizer.eos_token_id,
no_repeat_ngram_size=3,
**config
)
# Decode and return only the generated part
full_text = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
generated_text = full_text[len(prompt):]
return generated_text.strip()
def generate_multiple(self, prompt, n=3, **kwargs):
"""Generate multiple diverse completions."""
kwargs['num_return_sequences'] = n
kwargs['do_sample'] = True # Required for multiple sequences
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.device)
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=kwargs.pop('max_new_tokens', 50),
pad_token_id=self.tokenizer.eos_token_id,
**kwargs
)
completions = []
for output in outputs:
text = self.tokenizer.decode(output, skip_special_tokens=True)
completions.append(text[len(prompt):].strip())
return completions
# Usage example
print("TextGenerator Example")
print("=" * 60)
# Initialize (using smaller model for demo)
generator = TextGenerator("gpt2")
# Test different strategies
prompt = "The most important lesson I learned in life is"
print(f"\nPrompt: '{prompt}'")
print()
for strategy in ["greedy", "precise", "balanced", "creative"]:
result = generator.generate(prompt, max_new_tokens=40, strategy=strategy)
print(f"{strategy.upper():12}: {result[:80]}...")
print()
# Generate multiple completions
print("Multiple Completions (3):")
completions = generator.generate_multiple(
prompt, n=3, temperature=0.8, max_new_tokens=30
)
for i, comp in enumerate(completions, 1):
print(f" {i}. {comp[:60]}...")Streaming Generation
For interactive applications, streaming generation provides real-time token-by-token output:
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
import torch
# Load model
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Create streamer for real-time output
streamer = TextStreamer(tokenizer, skip_special_tokens=True)
# Generate with streaming
prompt = "Once upon a time in a distant galaxy,"
inputs = tokenizer(prompt, return_tensors="pt")
print("Streaming Generation:")
print(f"Prompt: {prompt}")
print("Output: ", end="")
# Generate with streamer - tokens appear in real-time
output = model.generate(
**inputs,
max_new_tokens=50,
do_sample=True,
temperature=0.8,
streamer=streamer,
pad_token_id=tokenizer.eos_token_id
)
print("\n\n[Generation complete]")# Advanced: Controlled Generation with Logits Processors
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
LogitsProcessor,
LogitsProcessorList
)
import torch
class KeywordBoostProcessor(LogitsProcessor):
"""
Custom logits processor that boosts probability of
specific keywords during generation.
"""
def __init__(self, tokenizer, keywords, boost_factor=2.0):
self.keyword_ids = []
for keyword in keywords:
# Get all token IDs that could represent this keyword
tokens = tokenizer.encode(keyword, add_special_tokens=False)
self.keyword_ids.extend(tokens)
self.boost_factor = boost_factor
def __call__(self, input_ids, scores):
"""Boost scores for keyword tokens."""
for token_id in self.keyword_ids:
scores[:, token_id] *= self.boost_factor
return scores
class BannedWordsProcessor(LogitsProcessor):
"""Processor that prevents generation of certain words."""
def __init__(self, tokenizer, banned_words):
self.banned_ids = []
for word in banned_words:
tokens = tokenizer.encode(word, add_special_tokens=False)
self.banned_ids.extend(tokens)
def __call__(self, input_ids, scores):
"""Set banned token scores to negative infinity."""
for token_id in self.banned_ids:
scores[:, token_id] = float('-inf')
return scores
# Example usage
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Create processors
keyword_booster = KeywordBoostProcessor(
tokenizer,
keywords=["innovative", "breakthrough", "revolutionary"],
boost_factor=3.0
)
word_banner = BannedWordsProcessor(
tokenizer,
banned_words=["bad", "terrible", "awful"]
)
processors = LogitsProcessorList([keyword_booster, word_banner])
# Generate with custom processors
prompt = "The new technology is"
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(
**inputs,
max_new_tokens=30,
do_sample=True,
temperature=0.8,
logits_processor=processors,
pad_token_id=tokenizer.eos_token_id
)
print("Controlled Generation with Custom Processors")
print("=" * 60)
print(f"Prompt: '{prompt}'")
print(f"Boosted keywords: innovative, breakthrough, revolutionary")
print(f"Banned words: bad, terrible, awful")
print(f"Output: {tokenizer.decode(output[0], skip_special_tokens=True)}")# Batch Generation for Efficiency
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import time
def batch_generate(prompts, model, tokenizer, max_new_tokens=50):
"""
Generate completions for multiple prompts efficiently.
Batching significantly speeds up generation when you have
multiple prompts to process.
"""
# Tokenize all prompts with padding
inputs = tokenizer(
prompts,
return_tensors="pt",
padding=True,
truncation=True
)
# Generate
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id
)
# Decode all outputs
results = []
for i, output in enumerate(outputs):
text = tokenizer.decode(output, skip_special_tokens=True)
# Remove the original prompt to get just the completion
completion = text[len(prompts[i]):].strip()
results.append(completion)
return results
# Example: batch generation
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(model_name)
prompts = [
"The future of AI is",
"Climate change will",
"Space exploration brings",
"Renewable energy offers",
"Healthcare technology enables"
]
print("Batch Generation Example")
print("=" * 60)
# Time comparison: batch vs sequential
start = time.time()
batch_results = batch_generate(prompts, model, tokenizer, max_new_tokens=30)
batch_time = time.time() - start
print(f"\nBatch generation time: {batch_time:.2f}s")
print(f"Prompts processed: {len(prompts)}")
print(f"Average per prompt: {batch_time/len(prompts):.2f}s")
print("\nResults:")
for prompt, result in zip(prompts, batch_results):
print(f"\n'{prompt}'")
print(f"? {result[:60]}...")Conclusion & Next Steps
GPT models and autoregressive text generation have transformed what's possible with language technology. From GPT-1's demonstration of transfer learning to GPT-4's human-level reasoning, the evolution of these models shows the remarkable capabilities that emerge from scaling transformers on massive text corpora. Understanding the architecture, decoding strategies, and prompt engineering techniques covered in this guide provides the foundation for building powerful text generation applications.
The key takeaways from this guide include: (1) Autoregressive modeling enables natural text generation by predicting tokens sequentially; (2) Scale matters—larger models exhibit emergent capabilities like in-context learning; (3) Decoding strategy choice dramatically affects output quality and should match your use case; (4) Prompt engineering is a crucial skill for getting the best results from any GPT model; and (5) RLHF alignment transforms raw language models into helpful, safe assistants.
Your Learning Path Forward
With GPT fundamentals mastered, you're ready to:
- Part 11 - Core NLP Tasks: Apply these models to classification, NER, and POS tagging
- Part 12 - Advanced Tasks: Master question answering, summarization, and translation
- Part 14 - Ethics & Evaluation: Learn responsible deployment of generative AI
- Part 16 - Production: Deploy and optimize models for real-world applications
Practice Exercises
- Decoding Experiment: Generate the same prompt 10 times with different temperature values (0.1 to 2.0). Plot diversity vs. coherence.
- Prompt Engineering: Create a few-shot prompt that converts natural language dates ("next Tuesday", "in two weeks") to ISO format.
- Custom Generation: Implement a LogitsProcessor that enforces a specific text format (e.g., always starts sentences with capital letters).
- Comparison Study: Compare GPT-2, GPT-2-medium, and GPT-2-large on the same creative writing task. Document quality differences.
- Application: Build a story generator that maintains character consistency using prompt chaining.
The GPT family continues to evolve rapidly, with new models, techniques, and capabilities emerging regularly. The principles covered here—autoregressive generation, scaling laws, prompt engineering, and alignment—provide a durable foundation that will remain relevant as the field advances. In the next part of this series, we'll apply these generative capabilities to core NLP tasks, seeing how GPT models can be used for classification, entity recognition, and other foundational challenges.