Introduction to NLP
Natural Language Processing (NLP) is the bridge between human communication and machine understanding. In this first part of our comprehensive 16-part series, we'll explore the fundamental concepts that underpin all NLP systems.
Key Insight
NLP is fundamentally about enabling computers to understand, interpret, and generate human language in a way that is both meaningful and useful.
NLP Mastery
NLP Fundamentals & Linguistic Basics
Phonology, morphology, syntax, semantics, pragmaticsTokenization & Text Cleaning
Subword tokenization, BPE, stopwords, normalizationText Representation & Feature Engineering
Bag-of-words, TF-IDF, feature extraction, vectorizationWord Embeddings
Word2Vec, GloVe, FastText, embedding spaces, analogiesStatistical Language Models & N-grams
Probability chains, smoothing, perplexity, Markov modelsNeural Networks for NLP
Feedforward nets, backpropagation, activation functionsRNNs, LSTMs & GRUs
Sequence modeling, vanishing gradients, gated architecturesTransformers & Attention Mechanism
Self-attention, multi-head attention, positional encodingPretrained Language Models & Transfer Learning
BERT, RoBERTa, fine-tuning, feature extractionGPT Models & Text Generation
Autoregressive generation, prompting, GPT architectureCore NLP Tasks
NER, POS tagging, sentiment analysis, text classificationAdvanced NLP Tasks
Question answering, summarization, machine translationMultilingual & Cross-lingual NLP
mBERT, XLM-R, zero-shot transfer, language diversityEvaluation, Ethics & Responsible NLP
BLEU, ROUGE, bias detection, fairness, responsible AINLP Systems, Optimization & Production
Model serving, quantization, distillation, deploymentCutting-Edge & Research Topics
LLMs, multimodal NLP, reasoning, emerging researchWhat is NLP?
Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on the interaction between computers and human language. It combines computational linguistics—the rule-based modeling of language—with statistical, machine learning, and deep learning techniques to enable machines to process, understand, and generate human language in meaningful ways.
At its core, NLP addresses the fundamental challenge of bridging the gap between human communication and machine computation. While humans effortlessly understand language with all its nuances, ambiguities, and contextual dependencies, computers operate on discrete symbols and mathematical operations. NLP provides the algorithms and models that translate between these two worlds.
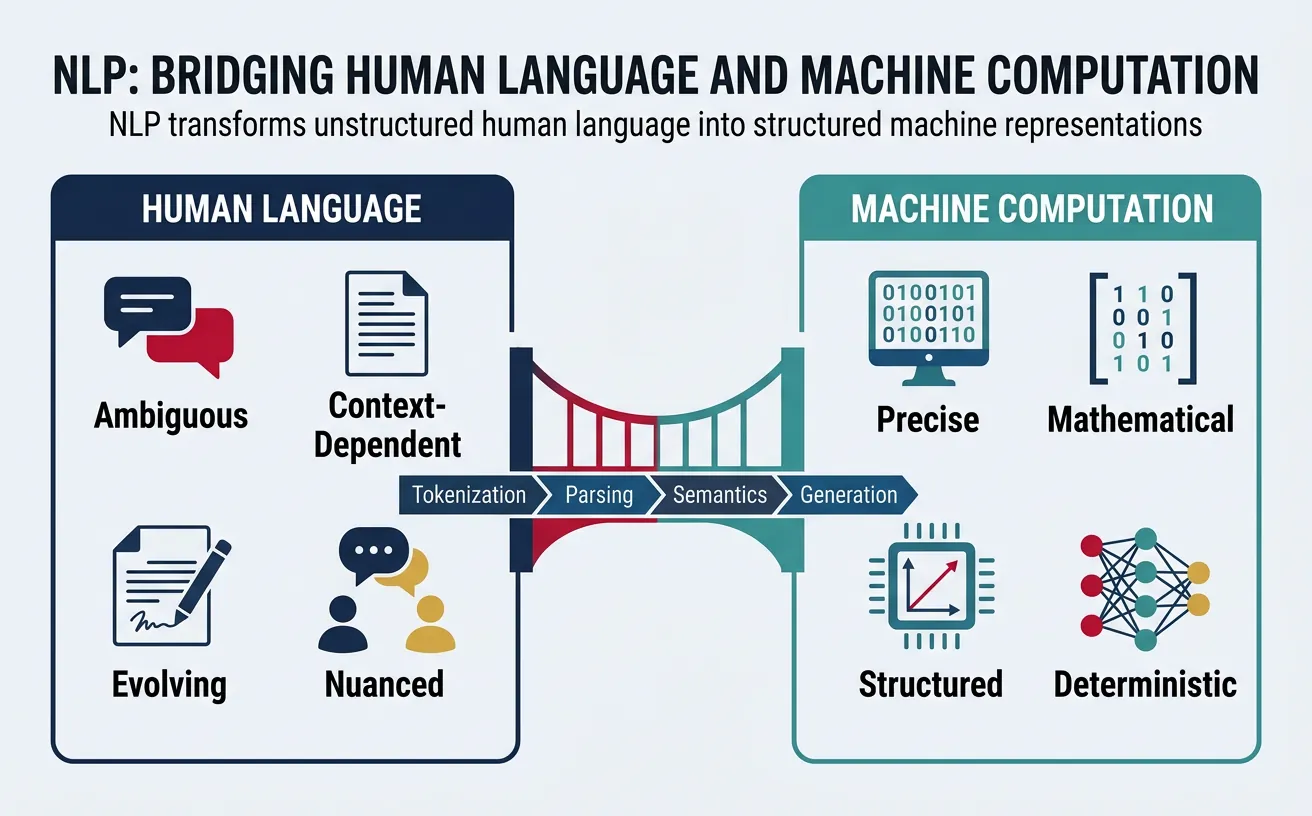
The field encompasses two primary directions:
- Natural Language Understanding (NLU): Enabling machines to comprehend and interpret human language input—extracting meaning, intent, and relationships from text or speech.
- Natural Language Generation (NLG): Enabling machines to produce human-like language output—creating coherent text, responses, summaries, or translations.
The NLP Challenge
Human language is inherently ambiguous, contextual, and evolving. The sentence "I saw her duck" could mean observing someone's pet bird OR watching someone lower their head. NLP systems must navigate these complexities that humans resolve unconsciously through context and world knowledge.
# Introduction to NLP with Python
# Demonstrating basic text analysis concepts
import re
from collections import Counter
# Sample text for analysis
text = """Natural Language Processing enables computers to understand human language.
NLP combines linguistics and computer science to analyze text and speech.
Modern NLP uses deep learning for remarkable language understanding."""
# Basic text statistics
words = text.lower().split()
sentences = text.split('.')
print("=== Basic NLP Statistics ===")
print(f"Total characters: {len(text)}")
print(f"Total words: {len(words)}")
print(f"Total sentences: {len([s for s in sentences if s.strip()])}")
print(f"Unique words: {len(set(words))}")
print(f"Average word length: {sum(len(w) for w in words) / len(words):.2f}")
# Word frequency analysis
word_freq = Counter(words)
print(f"\nTop 5 most common words:")
for word, count in word_freq.most_common(5):
print(f" '{word}': {count} occurrences")
Use Cases & Applications
NLP powers countless applications that we interact with daily, often without realizing the sophisticated language processing happening behind the scenes. These applications span virtually every industry and have transformed how we interact with technology.
Search & Information Retrieval
Search engines like Google use NLP to understand query intent, match relevant documents, and provide direct answers. Modern search goes far beyond keyword matching—it understands synonyms, context, and user intent to deliver relevant results.
- Query understanding and expansion
- Document ranking and relevance scoring
- Featured snippets and direct answers
- Voice search and conversational queries
Virtual Assistants & Chatbots
Siri, Alexa, Google Assistant, and enterprise chatbots rely on NLP to interpret user requests, maintain conversation context, and generate appropriate responses.
- Intent classification: Understanding what the user wants
- Entity extraction: Identifying key information (dates, names, locations)
- Dialogue management: Maintaining conversation flow
- Response generation: Producing natural, helpful replies
Machine Translation
Services like Google Translate and DeepL use neural machine translation to convert text between languages while preserving meaning, tone, and context. Modern systems handle over 100 languages with near-human quality for common language pairs.
Other major applications include:
- Sentiment Analysis: Understanding opinions in reviews, social media, and customer feedback
- Email Filtering: Spam detection and email categorization
- Content Recommendation: Suggesting articles, products, and media based on text analysis
- Healthcare: Clinical note analysis, medical literature mining, and patient communication
- Legal: Contract analysis, legal document review, and case law research
- Finance: News sentiment analysis, fraud detection, and automated reporting
Limitations & Challenges
Despite remarkable progress, NLP systems face significant challenges that highlight the complexity of human language. Understanding these limitations is crucial for building realistic expectations and designing effective solutions.
Ambiguity
Language is inherently ambiguous at multiple levels. Consider the sentence "The chicken is ready to eat"—does this mean the chicken is prepared as food, or that a live chicken is hungry? Humans resolve such ambiguities effortlessly using context and world knowledge, but machines struggle with these distinctions.
# Demonstrating linguistic ambiguity challenges
# Lexical ambiguity - same word, different meanings
lexical_examples = [
("bank", ["financial institution", "river edge", "to rely on"]),
("bat", ["flying mammal", "sports equipment", "to hit"]),
("light", ["illumination", "not heavy", "to ignite"]),
]
print("=== Lexical Ambiguity Examples ===")
for word, meanings in lexical_examples:
print(f"\n'{word}' can mean:")
for i, meaning in enumerate(meanings, 1):
print(f" {i}. {meaning}")
# Syntactic ambiguity - same sentence, different parses
syntactic_examples = [
("I saw the man with the telescope",
["I used a telescope to see the man",
"I saw a man who had a telescope"]),
("Flying planes can be dangerous",
["Planes that fly are dangerous",
"The act of piloting planes is dangerous"]),
]
print("\n=== Syntactic Ambiguity Examples ===")
for sentence, interpretations in syntactic_examples:
print(f"\nSentence: '{sentence}'")
print("Possible interpretations:")
for i, interp in enumerate(interpretations, 1):
print(f" {i}. {interp}")
Context Dependence
The meaning of words and sentences often depends heavily on surrounding context, prior conversation, shared knowledge, and real-world situations. Pronouns like "it" and "they" require understanding what was previously mentioned. Sarcasm, irony, and humor depend on detecting mismatches between literal and intended meaning.
Data Bias and Fairness
NLP models learn from training data, which often contains societal biases related to gender, race, religion, and other sensitive attributes. Models can perpetuate and even amplify these biases, leading to unfair or harmful outputs. Addressing bias requires careful dataset curation, model auditing, and ongoing monitoring.
Resource Requirements
State-of-the-art NLP models require massive computational resources for training—GPT-3 reportedly cost millions of dollars to train. This creates barriers for smaller organizations and researchers, and raises environmental concerns about energy consumption.
Key Challenges Summary
- Ambiguity: Words and sentences have multiple interpretations
- Context: Meaning depends on surrounding information and world knowledge
- Common Sense: Machines lack intuitive understanding of how the world works
- Low-resource Languages: Most NLP research focuses on English; many languages lack data
- Domain Adaptation: Models trained on general text may fail in specialized domains
- Evaluation: Measuring true language understanding remains difficult
Levels of Language
Linguistics—the scientific study of language—analyzes human communication at multiple hierarchical levels. Each level addresses different aspects of language structure, from individual sounds to extended discourse. Understanding these levels is fundamental for NLP practitioners, as different tasks operate at different linguistic levels.
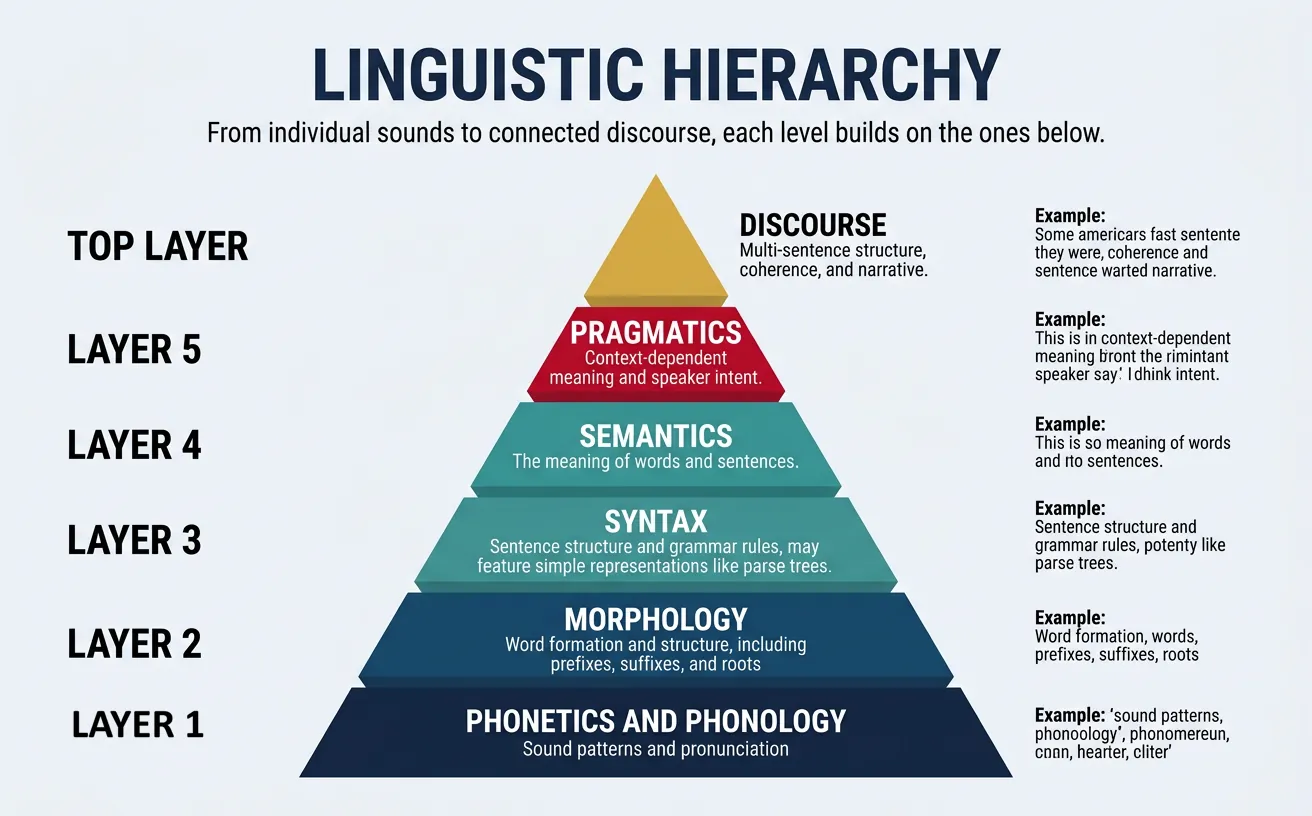
The Linguistic Hierarchy
Language can be analyzed at progressively higher levels of abstraction:
- Phonetics/Phonology: Sounds and sound patterns
- Morphology: Word formation and structure
- Syntax: Sentence structure and grammar
- Semantics: Meaning of words and sentences
- Pragmatics: Language use in context
- Discourse: Extended text and conversation structure
Phonetics & Phonology
Phonetics studies the physical properties of speech sounds—how they are produced by the vocal tract, transmitted through the air, and perceived by the ear. Phonology studies the abstract sound patterns and rules that govern how sounds function in particular languages.
While phonetics and phonology are primarily relevant to speech processing, they also matter for text NLP in several ways:
- Spelling correction: Many misspellings are phonetically motivated ("definately" for "definitely")
- Named entity normalization: Different spellings of names may represent the same phonetic form
- Text-to-speech: Converting text to phonetic representations for speech synthesis
- Rhyme detection: Poetry analysis and song lyric generation
Key phonetic concepts include:
- Phonemes: The smallest units of sound that distinguish meaning (e.g., /p/ vs /b/ in "pat" vs "bat")
- Allophones: Variant pronunciations of the same phoneme in different contexts
- International Phonetic Alphabet (IPA): A standardized notation system for representing speech sounds
# Working with phonetic representations
# Using the pronouncing library for CMU Pronouncing Dictionary
# Note: Run 'pip install pronouncing' first
import pronouncing
# Get phonetic pronunciations
words = ["natural", "language", "processing", "computer"]
print("=== Phonetic Pronunciations (ARPAbet) ===")
for word in words:
pronunciations = pronouncing.phones_for_word(word)
if pronunciations:
print(f"{word}: {pronunciations[0]}")
else:
print(f"{word}: (not found)")
# Find rhyming words
print("\n=== Words that Rhyme with 'processing' ===")
rhymes = pronouncing.rhymes("processing")
print(f"Found {len(rhymes)} rhymes: {rhymes[:10]}...")
# Count syllables
print("\n=== Syllable Counts ===")
for word in words:
phones = pronouncing.phones_for_word(word)
if phones:
syllables = pronouncing.syllable_count(phones[0])
print(f"{word}: {syllables} syllables")
Morphology
Morphology is the study of the internal structure of words. It analyzes how words are formed from smaller meaningful units called morphemes. Understanding morphology is essential for NLP tasks like stemming, lemmatization, and handling out-of-vocabulary words.
Words can be broken down into different types of morphemes:
- Roots/Stems: The core meaning unit that carries the main semantic content (e.g., "play" in "playing")
- Prefixes: Morphemes added before the root (e.g., "un-" in "unhappy", "re-" in "rebuild")
- Suffixes: Morphemes added after the root (e.g., "-ing" in "playing", "-ness" in "happiness")
- Infixes: Morphemes inserted within a root (rare in English, common in other languages)
Morpheme Types
Free morphemes can stand alone as words ("book", "happy"). Bound morphemes must attach to other morphemes ("-ing", "un-", "-ly"). Analyzing these patterns helps NLP systems understand word relationships and handle novel word forms.
Morphological processes in English include:
- Inflection: Grammatical variations that don't change word class (walk ? walks, walked, walking)
- Derivation: Creating new words, often changing word class (happy ? unhappy, happiness, happily)
- Compounding: Combining free morphemes (bookshelf, blackboard, sunflower)
# Morphological analysis with NLTK
import nltk
from nltk.stem import PorterStemmer, LancasterStemmer, WordNetLemmatizer
# Download required resources
nltk.download('wordnet', quiet=True)
nltk.download('omw-1.4', quiet=True)
# Initialize stemmers and lemmatizer
porter = PorterStemmer()
lancaster = LancasterStemmer()
lemmatizer = WordNetLemmatizer()
# Test words with various morphological forms
words = ["running", "ran", "runs", "runner", "happily", "happiness",
"unhappy", "studies", "studying", "better", "best"]
print("=== Stemming Comparison ===")
print(f"{'Word':<12} {'Porter':<12} {'Lancaster':<12}")
print("-" * 36)
for word in words:
print(f"{word:<12} {porter.stem(word):<12} {lancaster.stem(word):<12}")
print("\n=== Lemmatization (with POS) ===")
# Lemmatization requires part-of-speech for best results
# 'v' = verb, 'n' = noun, 'a' = adjective, 'r' = adverb
test_cases = [
("running", "v"),
("runs", "v"),
("better", "a"),
("studies", "n"),
("studies", "v"),
]
for word, pos in test_cases:
lemma = lemmatizer.lemmatize(word, pos=pos)
print(f"{word} (as {pos}): {lemma}")
Syntax
Syntax studies the rules and principles governing sentence structure—how words combine to form phrases, clauses, and sentences. It defines the grammatical relationships between words and determines whether a sequence of words is well-formed in a language.
Key syntactic concepts include:
- Parts of Speech (POS): Grammatical categories like nouns, verbs, adjectives, adverbs, prepositions
- Phrases: Groups of words functioning as a unit (noun phrases, verb phrases, prepositional phrases)
- Constituents: Structural units that can be replaced, moved, or coordinated as a whole
- Parse Trees: Hierarchical representations of sentence structure
- Dependencies: Directed relationships between words (subject-verb, modifier-noun)
# Syntactic analysis with spaCy
import spacy
# Load English language model
nlp = spacy.load("en_core_web_sm")
# Analyze a sentence
sentence = "The quick brown fox jumps over the lazy dog."
doc = nlp(sentence)
# Part-of-Speech tagging
print("=== Part-of-Speech Tags ===")
print(f"{'Token':<10} {'POS':<8} {'Tag':<8} {'Explanation'}")
print("-" * 50)
for token in doc:
print(f"{token.text:<10} {token.pos_:<8} {token.tag_:<8} {spacy.explain(token.tag_)}")
# Dependency parsing
print("\n=== Dependency Relations ===")
print(f"{'Token':<10} {'Dep':<12} {'Head':<10} {'Children'}")
print("-" * 50)
for token in doc:
children = [child.text for child in token.children]
print(f"{token.text:<10} {token.dep_:<12} {token.head.text:<10} {children}")
# Noun chunks (noun phrases)
print("\n=== Noun Phrases ===")
for chunk in doc.noun_chunks:
print(f" '{chunk.text}' (root: {chunk.root.text})")
Constituency vs Dependency Parsing
Constituency parsing breaks sentences into nested constituents (phrases within phrases), producing tree structures that show hierarchical groupings. It answers "what are the parts?"
Dependency parsing identifies direct grammatical relationships between words, showing which word modifies or is governed by which other word. It answers "how are words related?"
Modern NLP often prefers dependency parsing because it's simpler, produces more consistent cross-lingual annotations, and captures semantic relationships more directly.
Semantics
Semantics is the study of meaning in language. While syntax tells us whether a sentence is grammatically well-formed, semantics tells us what it means. This is perhaps the most challenging level for NLP, as meaning is abstract, context-dependent, and deeply connected to human knowledge and experience.
Semantics operates at multiple levels:
- Lexical Semantics: The meaning of individual words (word senses, synonymy, antonymy, hyponymy)
- Compositional Semantics: How word meanings combine to form phrase and sentence meanings
- Distributional Semantics: Meaning derived from patterns of word co-occurrence ("you shall know a word by the company it keeps")
Word Sense Disambiguation
A central challenge in lexical semantics is polysemy—words having multiple related meanings. The word "bank" can mean a financial institution, a river edge, or to tilt an aircraft. NLP systems must disambiguate the intended sense based on context.
# Exploring lexical semantics with WordNet
import nltk
from nltk.corpus import wordnet as wn
# Download WordNet if needed
nltk.download('wordnet', quiet=True)
nltk.download('omw-1.4', quiet=True)
# Explore word senses (polysemy)
word = "bank"
synsets = wn.synsets(word)
print(f"=== Word Senses for '{word}' ===")
print(f"Found {len(synsets)} different senses:\n")
for i, syn in enumerate(synsets[:5], 1): # Show first 5
print(f"{i}. {syn.name()}")
print(f" Definition: {syn.definition()}")
print(f" Examples: {syn.examples()[:2]}")
print()
# Semantic relationships
print("=== Semantic Relations for 'dog' ===")
dog = wn.synset('dog.n.01')
# Hypernyms (is-a, more general)
print(f"\nHypernyms (dog IS A...):")
for hyp in dog.hypernyms():
print(f" - {hyp.name()}: {hyp.definition()}")
# Hyponyms (is-a, more specific)
print(f"\nHyponyms (... IS A dog):")
for hypo in dog.hyponyms()[:5]:
print(f" - {hypo.name()}")
# Synonyms (words in the same synset)
print(f"\nSynonyms/Lemmas:")
print(f" {[lemma.name() for lemma in dog.lemmas()]}")
Key semantic relationships include:
- Synonymy: Words with similar meanings (big/large, happy/joyful)
- Antonymy: Words with opposite meanings (hot/cold, buy/sell)
- Hyponymy/Hypernymy: Is-a relationships (dog is a mammal, mammal is an animal)
- Meronymy/Holonymy: Part-of relationships (wheel is part of car)
- Entailment: If X then Y ("snoring" entails "sleeping")
Pragmatics & Discourse
Pragmatics studies how context contributes to meaning beyond the literal semantic content. It addresses how speakers use language to accomplish goals, how listeners infer intended meaning, and how utterances function in real communicative situations.
Key pragmatic phenomena include:
- Speech Acts: The actions performed through language (requesting, promising, warning, apologizing)
- Implicature: Meaning implied but not explicitly stated ("It's cold in here" may imply "Please close the window")
- Presupposition: Background assumptions taken for granted ("Have you stopped smoking?" presupposes you once smoked)
- Deixis: Context-dependent references ("I", "here", "now", "this")
- Reference Resolution: Determining what pronouns and other referring expressions refer to
Grice's Maxims of Conversation
Philosopher Paul Grice proposed that conversations follow implicit cooperative principles:
- Quantity: Be as informative as required, but not more
- Quality: Only say what you believe to be true
- Relation: Be relevant to the conversation
- Manner: Be clear, brief, and orderly
Violations of these maxims often signal implicature—the speaker intends the listener to infer additional meaning.
Discourse Analysis studies language beyond the sentence level—how sentences connect to form coherent texts and conversations. It examines:
- Coherence: How texts hang together logically and thematically
- Cohesion: Linguistic devices that connect sentences (pronouns, conjunctions, ellipsis)
- Discourse Relations: How clauses and sentences relate (cause-effect, contrast, elaboration)
- Topic Structure: How topics are introduced, maintained, and shifted
# Coreference resolution - tracking entity mentions across text
import spacy
# Load spaCy with coreference support
# Note: Requires 'pip install spacy-experimental' and the coref model
nlp = spacy.load("en_core_web_sm")
# Example text with pronouns and references
text = """John went to the store. He bought some apples.
The store was closing soon, so he hurried.
John gave the apples to Mary. She was grateful."""
doc = nlp(text)
# Basic entity tracking (simplified approach)
print("=== Entity Mentions Across Text ===")
print(f"\nText: {text}\n")
# Extract named entities
print("Named Entities:")
for ent in doc.ents:
print(f" - {ent.text} ({ent.label_})")
# Find pronouns and their potential antecedents
print("\nPronouns found:")
for token in doc:
if token.pos_ == "PRON" and token.text.lower() in ["he", "she", "it", "they"]:
print(f" - '{token.text}' at position {token.i}")
print("\n(Full coreference resolution requires specialized models")
print("like neuralcoref or spacy-experimental coreference)")
NLP Approaches
The history of NLP can be characterized by three major paradigms, each representing different philosophies about how to process language computationally. Understanding these approaches helps contextualize modern techniques and recognize when different methods are appropriate.
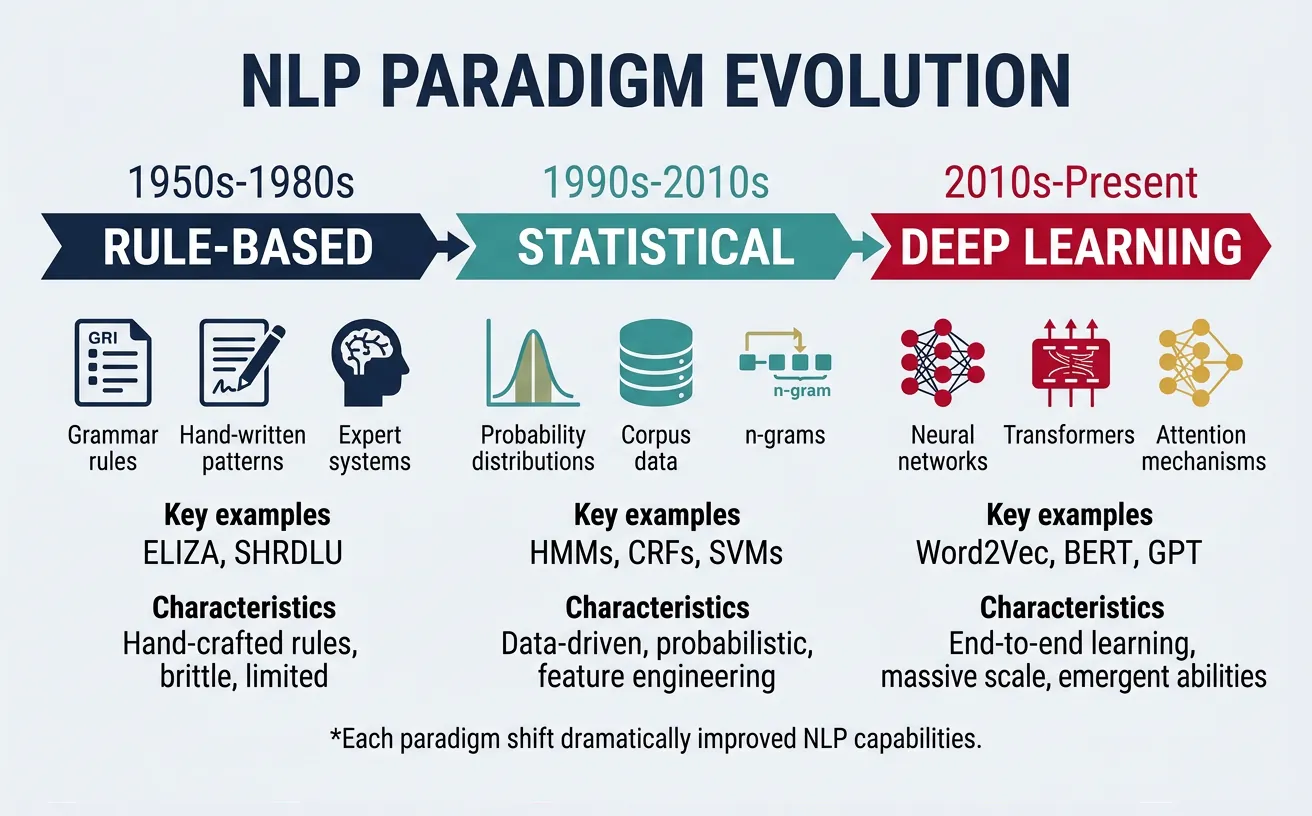
Evolution of NLP
NLP has evolved from hand-crafted rules (1950s-1980s) to statistical learning (1990s-2010s) to deep learning (2010s-present). Each paradigm built on insights from previous approaches, and elements of all three remain relevant today.
Rule-Based NLP
The earliest NLP systems relied on hand-crafted rules written by linguists and knowledge engineers. These systems encode explicit linguistic knowledge in the form of grammars, patterns, and if-then rules. While largely superseded by statistical methods for many tasks, rule-based approaches remain valuable for specific applications.
Characteristics of rule-based NLP:
- Explicit knowledge: Rules are written by humans based on linguistic expertise
- Interpretable: Easy to understand why the system made a particular decision
- Precise: Can achieve very high precision for well-defined patterns
- Labor-intensive: Requires significant effort to create and maintain rules
- Brittle: Struggles with language variation, exceptions, and novel inputs
# Rule-based NLP example: Simple pattern matching
import re
from typing import List, Tuple
def extract_dates_rule_based(text: str) -> List[str]:
"""Extract dates using regular expression rules."""
patterns = [
# MM/DD/YYYY or MM-DD-YYYY
r'\b(\d{1,2}[/-]\d{1,2}[/-]\d{2,4})\b',
# Month DD, YYYY
r'\b((?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)[a-z]*\s+\d{1,2},?\s+\d{4})\b',
# DD Month YYYY
r'\b(\d{1,2}\s+(?:January|February|March|April|May|June|July|August|September|October|November|December)\s+\d{4})\b',
]
dates = []
for pattern in patterns:
matches = re.findall(pattern, text, re.IGNORECASE)
dates.extend(matches)
return dates
def extract_emails_rule_based(text: str) -> List[str]:
"""Extract email addresses using regular expression rules."""
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
return re.findall(pattern, text)
# Test the rule-based extractors
test_text = """
Meeting scheduled for January 15, 2026 at 3pm.
Contact us at support@example.com or sales@company.org.
The deadline is 01/20/2026. Sincerely, John (john.doe@email.com)
"""
print("=== Rule-Based Information Extraction ===")
print(f"\nInput text:\n{test_text}")
print("\nExtracted dates:")
for date in extract_dates_rule_based(test_text):
print(f" - {date}")
print("\nExtracted emails:")
for email in extract_emails_rule_based(test_text):
print(f" - {email}")
When to Use Rule-Based Approaches
Rule-based methods excel in specific scenarios:
- High-precision requirements: When false positives are costly (medical, legal)
- Structured patterns: Extracting phone numbers, IDs, formatted codes
- Limited training data: When insufficient examples for statistical learning
- Interpretability needs: When you must explain every decision
- Hybrid systems: Combining rules with ML for preprocessing or post-processing
Statistical NLP
Starting in the 1990s, statistical approaches revolutionized NLP by learning patterns from data rather than relying on hand-crafted rules. These methods use probability theory and machine learning to build models that capture linguistic regularities automatically.
Key statistical NLP techniques include:
- N-gram Language Models: Predicting words based on preceding context
- Hidden Markov Models (HMMs): Sequence labeling for POS tagging, named entity recognition
- Naive Bayes: Text classification based on word frequencies
- Maximum Entropy/Logistic Regression: Discriminative classification with features
- Conditional Random Fields (CRFs): Structured prediction for sequences
- Topic Models (LDA): Discovering latent topics in document collections
# Statistical NLP: Text classification with scikit-learn
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import numpy as np
# Sample dataset: sentiment classification
texts = [
"I love this product, it's amazing!",
"Great quality and fast shipping",
"Best purchase I've ever made",
"Absolutely wonderful experience",
"This is terrible, waste of money",
"Broke after one day, very disappointed",
"Poor quality, would not recommend",
"Worst product ever, avoid at all costs",
]
labels = [1, 1, 1, 1, 0, 0, 0, 0] # 1=positive, 0=negative
# Feature extraction: Bag of Words
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
# Train classifier
clf = MultinomialNB()
clf.fit(X, labels)
# Test on new examples
test_texts = [
"This product exceeded my expectations!",
"I regret buying this, it's awful",
]
X_test = vectorizer.transform(test_texts)
predictions = clf.predict(X_test)
probabilities = clf.predict_proba(X_test)
print("=== Statistical Text Classification ===")
print(f"\nVocabulary size: {len(vectorizer.vocabulary_)}")
print(f"Features (sample): {list(vectorizer.vocabulary_.keys())[:10]}")
print("\nPredictions:")
for text, pred, prob in zip(test_texts, predictions, probabilities):
sentiment = "Positive" if pred == 1 else "Negative"
confidence = max(prob) * 100
print(f" '{text[:40]}...'")
print(f" ? {sentiment} (confidence: {confidence:.1f}%)")
Neural NLP
The deep learning revolution transformed NLP starting around 2013 with word embeddings and accelerating with attention mechanisms and transformers. Neural approaches learn hierarchical representations automatically from data, achieving state-of-the-art results on virtually every NLP benchmark.
Key neural NLP innovations:
- Word Embeddings (2013): Word2Vec, GloVe—dense vector representations capturing semantic relationships
- Recurrent Neural Networks: LSTMs and GRUs for sequence modeling
- Attention Mechanism (2014): Allowing models to focus on relevant parts of input
- Transformer Architecture (2017): Self-attention enabling parallel processing and capturing long-range dependencies
- Pretrained Language Models (2018+): BERT, GPT, and their successors—transfer learning for NLP
The Transformer Revolution
The 2017 paper "Attention Is All You Need" introduced the Transformer architecture, which has become the foundation for virtually all modern NLP. Transformers process sequences in parallel, capture long-range dependencies, and scale efficiently—enabling models with billions of parameters that achieve remarkable language understanding.
# Neural NLP with Hugging Face Transformers
from transformers import pipeline
# Sentiment analysis with pretrained model
print("=== Neural NLP with Transformers ===")
# Initialize sentiment analysis pipeline
sentiment_analyzer = pipeline("sentiment-analysis")
# Analyze sentiments
texts = [
"I absolutely love this new feature!",
"This is the worst experience I've ever had.",
"The product is okay, nothing special.",
"Outstanding quality and excellent service!",
]
print("\nSentiment Analysis:")
for text in texts:
result = sentiment_analyzer(text)[0]
print(f" '{text[:45]}...'")
print(f" ? {result['label']} ({result['score']:.3f})")
# Named Entity Recognition
print("\n" + "="*50)
ner_pipeline = pipeline("ner", aggregation_strategy="simple")
text = "Apple Inc. CEO Tim Cook announced new products in Cupertino, California."
entities = ner_pipeline(text)
print("\nNamed Entity Recognition:")
print(f"Text: {text}\n")
for ent in entities:
print(f" {ent['word']}: {ent['entity_group']} (score: {ent['score']:.3f})")
Comparing NLP Approaches
| Aspect | Rule-Based | Statistical | Neural |
|---|---|---|---|
| Data needs | None (expert knowledge) | Moderate (labeled data) | Large (pretrained + fine-tune) |
| Interpretability | High | Medium | Low (black box) |
| Generalization | Poor | Good | Excellent |
| Development time | High (manual) | Medium | Low (pretrained models) |
| Compute needs | Low | Low-Medium | High |
Text vs Speech NLP
While "NLP" often focuses on text, natural language exists in both written and spoken forms, each with unique characteristics and processing challenges. Understanding the differences between text and speech processing is crucial for building comprehensive language systems.
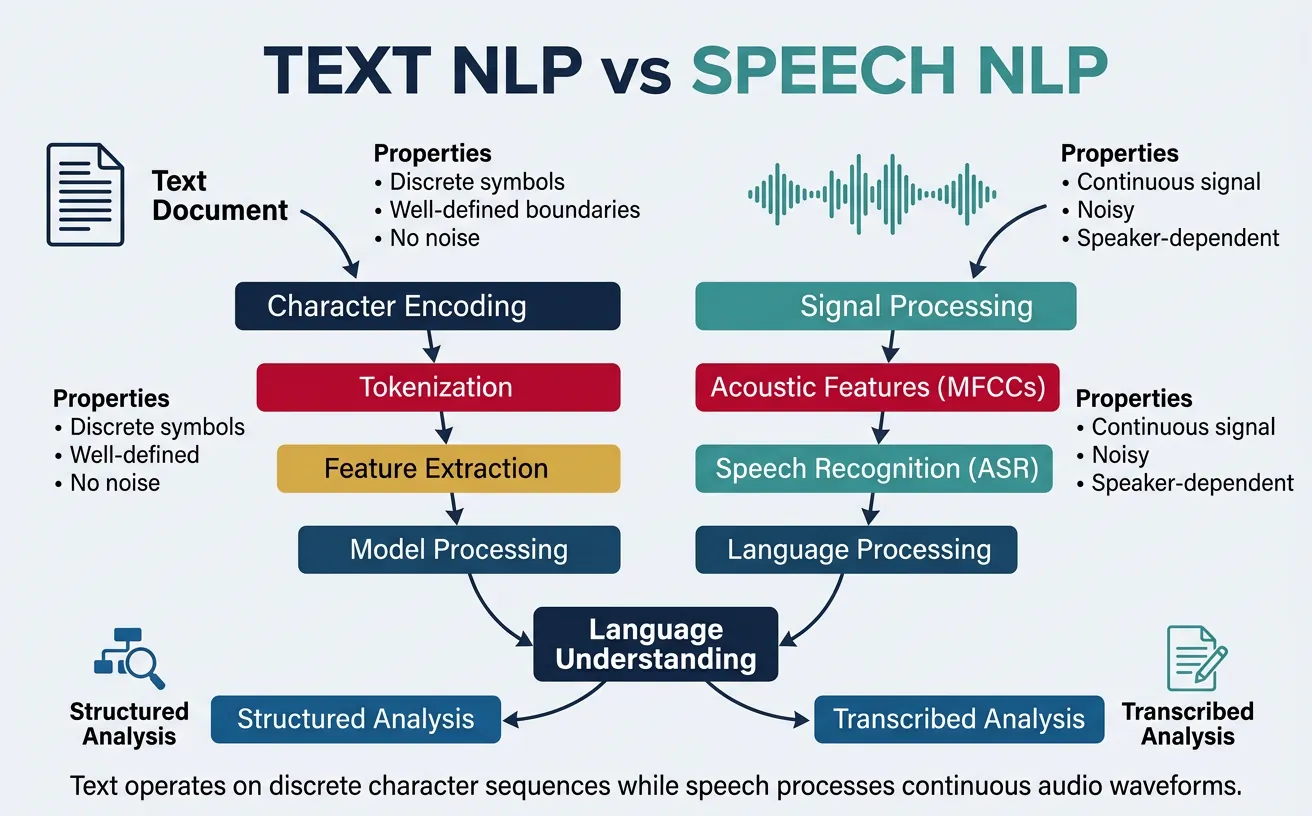
Text Processing
Text-based NLP works with written language, which has several advantages:
- Discrete tokens: Words are clearly separated by spaces and punctuation
- Persistent: Text can be read and re-read, processed offline
- Structured: Sentences, paragraphs, and documents provide organization
- Edited: Written text is often revised and polished
- Abundant data: Massive amounts of text available online
Speech Processing
Speech-based NLP (also called Spoken Language Processing or SLP) works with audio signals and faces additional challenges:
- Continuous signal: No clear word boundaries in the audio waveform
- Speaker variation: Accents, speaking rates, voice characteristics differ
- Acoustic noise: Background sounds, microphone quality, room acoustics
- Disfluencies: "Um", "uh", false starts, self-corrections, filled pauses
- Prosody: Intonation, stress, and rhythm carry meaning not present in text
- Real-time: Often requires immediate processing and response
Speech Processing Pipeline
Speech systems typically involve multiple stages: Automatic Speech Recognition (ASR) converts audio to text, NLP/NLU processes the transcribed text, and Text-to-Speech (TTS) converts text responses back to audio. Modern end-to-end systems increasingly blur these boundaries.
Text vs Speech: Key Differences
| Aspect | Text NLP | Speech NLP |
|---|---|---|
| Input | Character sequences | Audio waveforms |
| Segmentation | Explicit (spaces, punctuation) | Implicit (must be detected) |
| Errors | Typos, OCR errors | Recognition errors, homophones |
| Additional info | Formatting, punctuation | Prosody, speaker emotion |
| Style | Often formal, edited | Often informal, spontaneous |
# Speech-to-Text with OpenAI Whisper
# Demonstrating ASR (Automatic Speech Recognition)
import whisper
import numpy as np
# Load Whisper model (base model for demo)
# Options: tiny, base, small, medium, large
model = whisper.load_model("base")
# Transcribe audio file
# result = model.transcribe("audio_file.mp3")
# For demonstration, let's show the API usage
print("=== Speech Recognition with Whisper ===")
print("""
# To transcribe an audio file:
result = model.transcribe("speech.mp3")
# Result contains:
print(result["text"]) # Full transcription
print(result["language"]) # Detected language
# With timestamps:
for segment in result["segments"]:
print(f"[{segment['start']:.2f}s - {segment['end']:.2f}s]")
print(f" {segment['text']}")
# Whisper features:
# - Multilingual (99 languages)
# - Translation to English
# - Timestamp alignment
# - Robust to accents and noise
""")
print("\nWhisper model sizes and capabilities:")
models_info = [
("tiny", "39M params", "~1GB VRAM", "Fastest, lowest accuracy"),
("base", "74M params", "~1GB VRAM", "Good balance for demos"),
("small", "244M params", "~2GB VRAM", "Improved accuracy"),
("medium", "769M params", "~5GB VRAM", "High accuracy"),
("large", "1550M params", "~10GB VRAM", "Best accuracy"),
]
for name, params, vram, note in models_info:
print(f" {name:8} | {params:12} | {vram:12} | {note}")
NLP Pipelines & Workflows
NLP systems rarely perform a single task in isolation. Instead, they combine multiple processing steps into pipelines—sequences of components that progressively transform raw text into structured information or desired outputs. Understanding pipeline architecture is essential for building effective NLP applications.
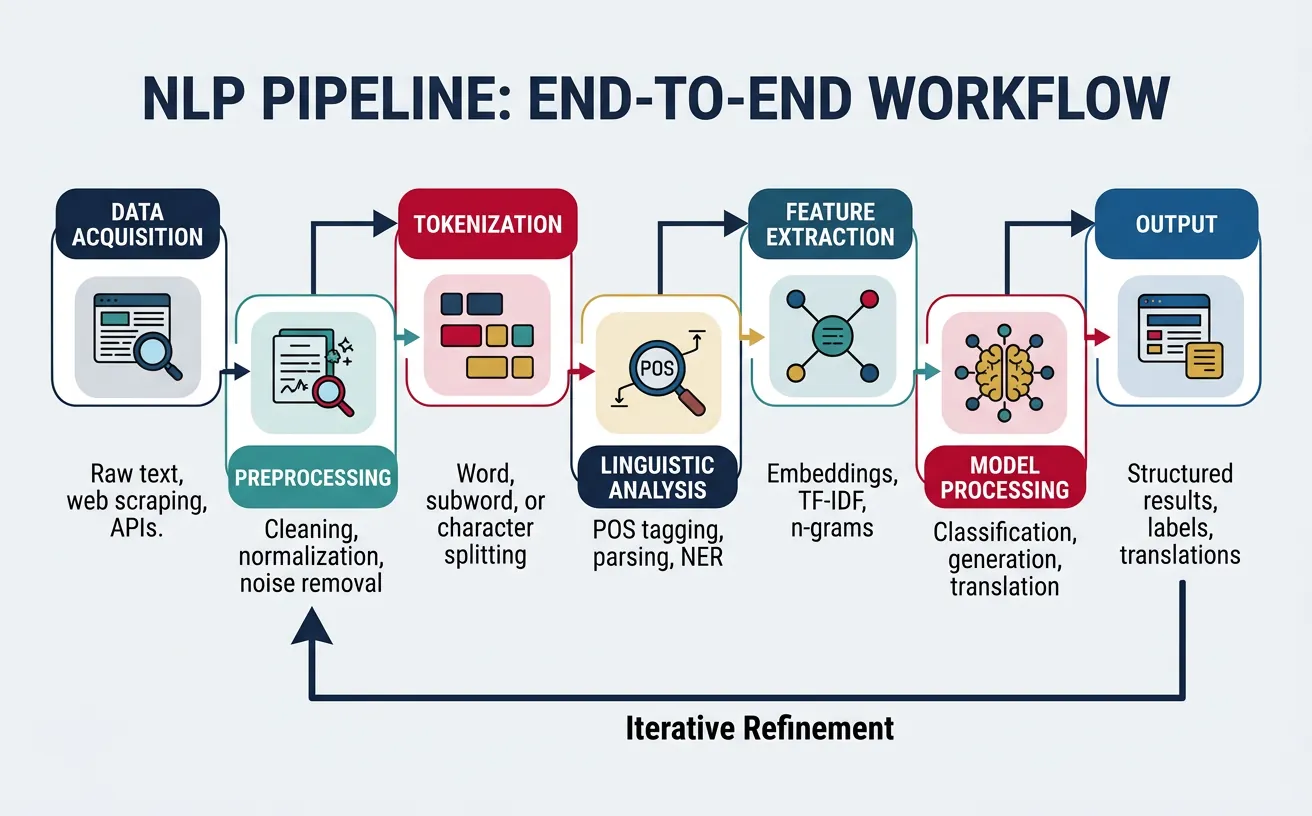
Standard NLP Pipeline Components
A typical NLP pipeline includes these stages:
- Data Acquisition: Collecting text from files, APIs, databases, web scraping
- Text Preprocessing: Cleaning, normalizing, handling encoding issues
- Tokenization: Splitting text into words, subwords, or characters
- Linguistic Analysis: POS tagging, parsing, named entity recognition
- Feature Extraction: Converting text to numerical representations
- Task-Specific Processing: Classification, generation, extraction, etc.
- Post-processing: Formatting output, filtering, aggregation
Pipeline Design Principles
- Modularity: Each component should have a single responsibility
- Error propagation: Errors in early stages affect downstream components
- Configurability: Allow swapping components for different use cases
- Efficiency: Consider batching, caching, and parallel processing
- Monitoring: Track performance at each stage
# Building a complete NLP pipeline with spaCy
import spacy
from collections import Counter
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Sample document
text = """
Apple Inc. announced its quarterly earnings yesterday in Cupertino.
CEO Tim Cook reported revenue of $90 billion, exceeding analyst expectations.
The company's new M3 chips have driven strong MacBook sales worldwide.
"""
print("=== Complete NLP Pipeline with spaCy ===")
print(f"\nInput text:\n{text}")
# Process the text through the pipeline
doc = nlp(text)
# Stage 1: Tokenization
print("\n--- Stage 1: Tokenization ---")
tokens = [token.text for token in doc if not token.is_space]
print(f"Tokens ({len(tokens)}): {tokens[:15]}...")
# Stage 2: Sentence segmentation
print("\n--- Stage 2: Sentence Segmentation ---")
for i, sent in enumerate(doc.sents, 1):
print(f"Sentence {i}: {sent.text.strip()[:60]}...")
# Stage 3: Part-of-Speech tagging
print("\n--- Stage 3: POS Tagging (sample) ---")
pos_dist = Counter(token.pos_ for token in doc)
print(f"POS distribution: {dict(pos_dist)}")
# Stage 4: Named Entity Recognition
print("\n--- Stage 4: Named Entity Recognition ---")
for ent in doc.ents:
print(f" {ent.text}: {ent.label_} ({spacy.explain(ent.label_)})")
# Stage 5: Dependency parsing (show root verbs)
print("\n--- Stage 5: Dependency Parsing ---")
for sent in doc.sents:
root = [token for token in sent if token.dep_ == "ROOT"][0]
subj = [child for child in root.children if "subj" in child.dep_]
print(f"Root verb: '{root.text}', Subject: {[s.text for s in subj]}")
Pipeline Architecture Patterns
Sequential Pipeline
Components execute in fixed order, each passing output to the next. Simple to understand and implement, but no parallelism and early errors propagate.
Input ? Tokenize ? POS Tag ? Parse ? NER ? Output
Parallel/Fan-out Pipeline
After preprocessing, multiple independent analyses run in parallel, with results aggregated at the end. Better throughput but more complex orchestration.
flowchart LR
IN["Input Text"] --> T["Tokenize"]
T --> SA["Sentiment Analysis"]
T --> NE["Named Entity Extraction"]
T --> TC["Topic Classification"]
SA --> Agg["Aggregate Results"]
NE --> Agg
TC --> Agg
# Custom NLP Pipeline with scikit-learn
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import cross_val_score
import numpy as np
# Sample data
texts = [
"The stock market rallied on positive earnings",
"Tech companies reported strong quarterly growth",
"Federal Reserve announces interest rate decision",
"Unemployment rates drop to historic lows",
"New smartphone features impressive camera technology",
"Electric vehicle sales continue upward trend",
"AI breakthrough achieves human-level performance",
"Climate summit reaches landmark agreement",
]
categories = ["finance", "finance", "finance", "finance",
"tech", "tech", "tech", "environment"]
# Build a classification pipeline
pipeline = Pipeline([
('vectorizer', TfidfVectorizer(
lowercase=True,
stop_words='english',
ngram_range=(1, 2),
max_features=1000
)),
('classifier', MultinomialNB())
])
print("=== Sklearn NLP Pipeline ===")
print(f"\nPipeline steps: {[name for name, _ in pipeline.steps]}")
# Fit the pipeline
pipeline.fit(texts, categories)
# Make predictions
test_texts = [
"Stock prices surge after merger announcement",
"Revolutionary AI model transforms healthcare",
]
print("\nPredictions:")
predictions = pipeline.predict(test_texts)
for text, pred in zip(test_texts, predictions):
print(f" '{text[:40]}...' ? {pred}")
# Inspect pipeline internals
vectorizer = pipeline.named_steps['vectorizer']
print(f"\nVocabulary size: {len(vectorizer.vocabulary_)}")
print(f"Sample features: {list(vectorizer.vocabulary_.keys())[:10]}")
Modern Pipeline Considerations
Contemporary NLP pipelines often incorporate:
- Pretrained models: Starting with BERT, GPT, or similar as foundation
- GPU acceleration: Batching for efficient neural model inference
- Streaming processing: Handling continuous data flows
- Caching: Storing intermediate results for repeated documents
- Error handling: Graceful degradation when components fail
- Observability: Logging, metrics, and tracing throughout the pipeline
Datasets, Corpora & Annotation
Data is the foundation of modern NLP. Whether training machine learning models or evaluating system performance, high-quality datasets are essential. Understanding corpus linguistics, annotation methodologies, and available resources is crucial for NLP practitioners.
Corpora and Datasets
A corpus (plural: corpora) is a large, structured collection of texts used for linguistic research and NLP development. Corpora vary widely in size, domain, language, and annotation.
Major NLP Corpora
- Penn Treebank: Gold-standard syntactic annotations for English (POS tags, parse trees)
- CoNLL Datasets: Shared task data for NER, coreference, dependency parsing
- SQuAD: Stanford Question Answering Dataset—reading comprehension
- GLUE/SuperGLUE: Multi-task benchmarks for language understanding
- Common Crawl: Petabytes of web text for pretraining
- Wikipedia: Encyclopedic text in 300+ languages
- IMDb Reviews: Movie reviews for sentiment analysis
- WMT: Parallel corpora for machine translation
# Accessing NLP datasets with NLTK and Hugging Face
import nltk
# Download NLTK data
nltk.download('brown', quiet=True)
nltk.download('gutenberg', quiet=True)
nltk.download('reuters', quiet=True)
from nltk.corpus import brown, gutenberg, reuters
print("=== Exploring NLTK Corpora ===")
# Brown Corpus - tagged American English
print("\n--- Brown Corpus ---")
print(f"Categories: {brown.categories()[:8]}...")
print(f"Total words: {len(brown.words()):,}")
print(f"Sample (news): {' '.join(brown.words(categories='news')[:15])}...")
# Tagged sentences
tagged = brown.tagged_sents(categories='news')[0][:8]
print(f"Tagged sample: {tagged}")
# Gutenberg Corpus - literary texts
print("\n--- Gutenberg Corpus ---")
print(f"Available texts: {gutenberg.fileids()[:5]}...")
austen = gutenberg.words('austen-emma.txt')
print(f"Emma word count: {len(austen):,}")
print(f"Sample: {' '.join(austen[:20])}")
# Reuters Corpus - news articles
print("\n--- Reuters Corpus ---")
print(f"Categories: {reuters.categories()[:10]}...")
print(f"Total documents: {len(reuters.fileids()):,}")
Data Annotation
Annotation is the process of adding labels or markup to text data. High-quality annotations are expensive to produce but essential for supervised learning. Key considerations include:
- Annotation scheme: Defining what labels to use and what they mean
- Annotation guidelines: Detailed instructions ensuring consistency
- Inter-annotator agreement: Measuring how consistently annotators apply labels
- Quality control: Checking for errors, biases, and inconsistencies
- Annotation tools: Software for efficient labeling (Prodigy, Label Studio, doccano)
Crowdsourcing vs Expert Annotation
Crowdsourcing (Amazon Mechanical Turk, Appen) is cost-effective for simple tasks but may have quality issues. Expert annotation is more reliable for complex linguistic judgments but significantly more expensive. Many projects use a hybrid approach—crowdsourcing initial labels with expert review.
# Working with annotated datasets from Hugging Face
from datasets import load_dataset
print("=== Hugging Face Datasets ===")
# Load a NER dataset
print("\n--- CoNLL-2003 Named Entity Recognition ---")
conll = load_dataset("conll2003", split="train[:5]")
print(f"Dataset features: {conll.features}")
print(f"\nSample sentence:")
example = conll[0]
print(f"Tokens: {example['tokens']}")
print(f"NER tags: {example['ner_tags']}")
# Label mapping
ner_labels = conll.features['ner_tags'].feature.names
print(f"\nNER label scheme: {ner_labels}")
# Load a sentiment dataset
print("\n--- IMDb Sentiment Analysis ---")
imdb = load_dataset("imdb", split="train[:3]")
for i, example in enumerate(imdb):
sentiment = "Positive" if example['label'] == 1 else "Negative"
text_preview = example['text'][:80].replace('\n', ' ')
print(f"\nExample {i+1} ({sentiment}):")
print(f" '{text_preview}...'")
# Load a question answering dataset
print("\n--- SQuAD Question Answering ---")
squad = load_dataset("squad", split="train[:2]")
for example in squad:
print(f"\nContext: {example['context'][:100]}...")
print(f"Question: {example['question']}")
print(f"Answer: {example['answers']['text'][0]}")
Creating Your Own Dataset
When existing datasets don't meet your needs, you may need to create your own. Key steps include:
- Define the task: What exactly should annotators label?
- Design the schema: What categories, entities, or structures?
- Write guidelines: Clear instructions with examples and edge cases
- Pilot annotation: Small-scale test to refine guidelines
- Calculate agreement: Measure inter-annotator reliability (Cohen's ?, Fleiss' ?)
- Scale up: Annotate full dataset with quality checks
- Adjudicate disagreements: Resolve conflicts through discussion or majority vote
Inter-Annotator Agreement Metrics
- Cohen's Kappa (?): Agreement between 2 annotators, correcting for chance
- Fleiss' Kappa: Agreement among multiple annotators
- Krippendorff's Alpha: Handles missing data and various data types
Interpretation: ? > 0.8 = excellent, 0.6-0.8 = substantial, 0.4-0.6 = moderate, < 0.4 = poor
Conclusion & Next Steps
In this foundational guide, we've explored the essential concepts that underpin all Natural Language Processing systems. From understanding what NLP is and its real-world applications to diving deep into the linguistic levels of language analysis, we've built a comprehensive foundation for the journey ahead.
Key Takeaways
What You've Learned
- NLP fundamentals: The field bridges human communication and machine understanding through NLU and NLG
- Linguistic levels: Language operates at phonetic, morphological, syntactic, semantic, and pragmatic levels—each presenting unique challenges
- Three paradigms: Rule-based, statistical, and neural approaches each have their place in modern NLP
- Text vs speech: Written and spoken language require different processing strategies
- Pipelines: NLP systems combine multiple processing stages for real-world applications
- Data matters: High-quality annotated corpora are the foundation of supervised NLP
What's Next
With this foundation in place, you're ready to dive into the practical aspects of NLP. In Part 2: Tokenization & Text Cleaning, we'll explore how to convert raw text into the structured input that NLP models require—the critical first step in any NLP pipeline.
Upcoming topics in the series include:
- Part 2: Tokenization strategies (word, subword, character) and text preprocessing techniques
- Part 3: Feature engineering with Bag of Words, TF-IDF, and N-grams
- Part 4: Word embeddings that capture semantic relationships (Word2Vec, GloVe, FastText)
- Parts 5-8: From statistical language models to the Transformer architecture
- Parts 9-10: Pretrained models (BERT, GPT) and transfer learning
- Parts 11-16: Core tasks, advanced applications, multilingual NLP, ethics, and production systems
Practice Exercises
To reinforce your learning, try these exercises:
- Explore NLTK corpora: Load different corpora (brown, gutenberg, reuters) and compute basic statistics
- Build a rule-based extractor: Write regex patterns to extract phone numbers, URLs, and hashtags
- Analyze dependencies: Use spaCy to visualize dependency trees for complex sentences
- Compare stemmers: Apply Porter, Lancaster, and Snowball stemmers to the same text and compare results
- Explore WordNet: Find synonyms, antonyms, and hypernyms for 10 common words
Additional Resources
To deepen your understanding, explore these resources:
- Books: "Speech and Language Processing" by Jurafsky & Martin (free online), "Natural Language Processing with Python" by Bird, Klein & Loper
- Courses: Stanford CS224N (NLP with Deep Learning), Coursera NLP Specialization
- Libraries: spaCy documentation, Hugging Face tutorials, NLTK book
- Papers: "Attention Is All You Need", "BERT: Pre-training of Deep Bidirectional Transformers"