Introduction to Transfer Learning
Transfer learning revolutionized NLP by enabling models pretrained on massive text corpora to be adapted for specific tasks with minimal labeled data. This "pretrain-then-finetune" paradigm dramatically improved performance across nearly all NLP benchmarks.
Key Insight
Pretrained language models learn general linguistic knowledge (syntax, semantics, world knowledge) that transfers effectively to downstream tasks, reducing the need for task-specific labeled data.
NLP Mastery
NLP Fundamentals & Linguistic Basics
Phonology, morphology, syntax, semantics, pragmaticsTokenization & Text Cleaning
Subword tokenization, BPE, stopwords, normalizationText Representation & Feature Engineering
Bag-of-words, TF-IDF, feature extraction, vectorizationWord Embeddings
Word2Vec, GloVe, FastText, embedding spaces, analogiesStatistical Language Models & N-grams
Probability chains, smoothing, perplexity, Markov modelsNeural Networks for NLP
Feedforward nets, backpropagation, activation functionsRNNs, LSTMs & GRUs
Sequence modeling, vanishing gradients, gated architecturesTransformers & Attention Mechanism
Self-attention, multi-head attention, positional encodingPretrained Language Models & Transfer Learning
BERT, RoBERTa, fine-tuning, feature extractionGPT Models & Text Generation
Autoregressive generation, prompting, GPT architectureCore NLP Tasks
NER, POS tagging, sentiment analysis, text classificationAdvanced NLP Tasks
Question answering, summarization, machine translationMultilingual & Cross-lingual NLP
mBERT, XLM-R, zero-shot transfer, language diversityEvaluation, Ethics & Responsible NLP
BLEU, ROUGE, bias detection, fairness, responsible AINLP Systems, Optimization & Production
Model serving, quantization, distillation, deploymentCutting-Edge & Research Topics
LLMs, multimodal NLP, reasoning, emerging researchPretraining Objectives
Pretraining objectives define how models learn from unlabeled text. These self-supervised tasks allow models to capture linguistic patterns, semantic relationships, and world knowledge from massive corpora without requiring expensive manual annotations. The choice of pretraining objective significantly impacts what the model learns and how well it transfers to downstream tasks.
Different objectives encourage different representations: some focus on understanding context bidirectionally, others on predicting future tokens, and some combine multiple objectives to capture diverse linguistic phenomena. Understanding these objectives helps practitioners choose the right pretrained model for their specific use case.

Masked Language Modeling (MLM)
Masked Language Modeling is BERT's core pretraining objective. During training, 15% of tokens are randomly selected for prediction: 80% are replaced with [MASK], 10% with random tokens, and 10% remain unchanged. The model learns to predict the original tokens using bidirectional context, enabling deep understanding of word relationships and sentence structure.
This approach differs fundamentally from traditional left-to-right language models by allowing the model to attend to both preceding and following context simultaneously. The masking strategy prevents the model from simply copying the input and forces it to develop robust representations of linguistic patterns.
from transformers import BertTokenizer, BertForMaskedLM
import torch
# Load BERT for masked language modeling
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# Create input with [MASK] token
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors='pt')
# Get predictions
with torch.no_grad():
outputs = model(**inputs)
predictions = outputs.logits
# Find the masked position
mask_idx = torch.where(inputs['input_ids'] == tokenizer.mask_token_id)[1]
# Get top 5 predictions
top_tokens = predictions[0, mask_idx, :].topk(5)
print("Top 5 predictions for [MASK]:")
for score, token_id in zip(top_tokens.values[0], top_tokens.indices[0]):
print(f" {tokenizer.decode([token_id])}: {score.item():.3f}")MLM Training Details
The 15% masking rate balances two factors: too little masking means inefficient learning from each example, while too much masking removes too much context for accurate prediction. The 80-10-10 split (MASK/random/unchanged) helps the model handle real text at inference time where there are no [MASK] tokens.
Next Sentence Prediction (NSP)
Next Sentence Prediction is BERT's secondary pretraining objective, designed to help the model understand relationships between sentences. During training, the model receives pairs of sentences and must predict whether the second sentence actually follows the first in the original document or is a randomly sampled sentence from elsewhere in the corpus.
While NSP was intended to improve performance on tasks requiring sentence-pair understanding (like question answering and natural language inference), later research showed it may not be essential. RoBERTa demonstrated that removing NSP and focusing solely on MLM with longer sequences can achieve better results on many benchmarks.
from transformers import BertTokenizer, BertForNextSentencePrediction
import torch
# Load BERT for NSP
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased')
# Example: Related sentences (should predict "is next")
sentence_a = "The weather is beautiful today."
sentence_b = "I think I'll go for a walk in the park."
# Tokenize the sentence pair
encoding = tokenizer(
sentence_a,
sentence_b,
return_tensors='pt',
padding=True,
truncation=True
)
# Get prediction
with torch.no_grad():
outputs = model(**encoding)
logits = outputs.logits
# Interpret results (0 = is_next, 1 = not_next)
probs = torch.softmax(logits, dim=1)
is_next_prob = probs[0, 0].item()
not_next_prob = probs[0, 1].item()
print(f"Sentence A: {sentence_a}")
print(f"Sentence B: {sentence_b}")
print(f"Is Next probability: {is_next_prob:.3f}")
print(f"Not Next probability: {not_next_prob:.3f}")Other Pretraining Objectives
- Sentence Order Prediction (SOP): ALBERT uses this instead of NSP—predicts if two consecutive sentences are in correct order
- Replaced Token Detection: ELECTRA's approach—detect which tokens were replaced by a generator model
- Causal Language Modeling: GPT's approach—predict next token given all previous tokens
- Span Masking: SpanBERT masks contiguous spans rather than random tokens
- Translation Language Modeling: XLM uses parallel corpora to learn cross-lingual representations
BERT Architecture
BERT (Bidirectional Encoder Representations from Transformers) is a transformer encoder stack that processes input text bidirectionally. Unlike previous models that read text left-to-right or combined left-to-right and right-to-left representations, BERT uses self-attention to consider all positions simultaneously, enabling each token to attend to every other token regardless of position.
BERT comes in two main sizes: BERT-Base (12 layers, 768 hidden dimensions, 12 attention heads, 110M parameters) and BERT-Large (24 layers, 1024 hidden dimensions, 16 attention heads, 340M parameters). The model uses WordPiece tokenization with a vocabulary of 30,000 tokens and includes special tokens like [CLS] for classification and [SEP] to separate sentence pairs.
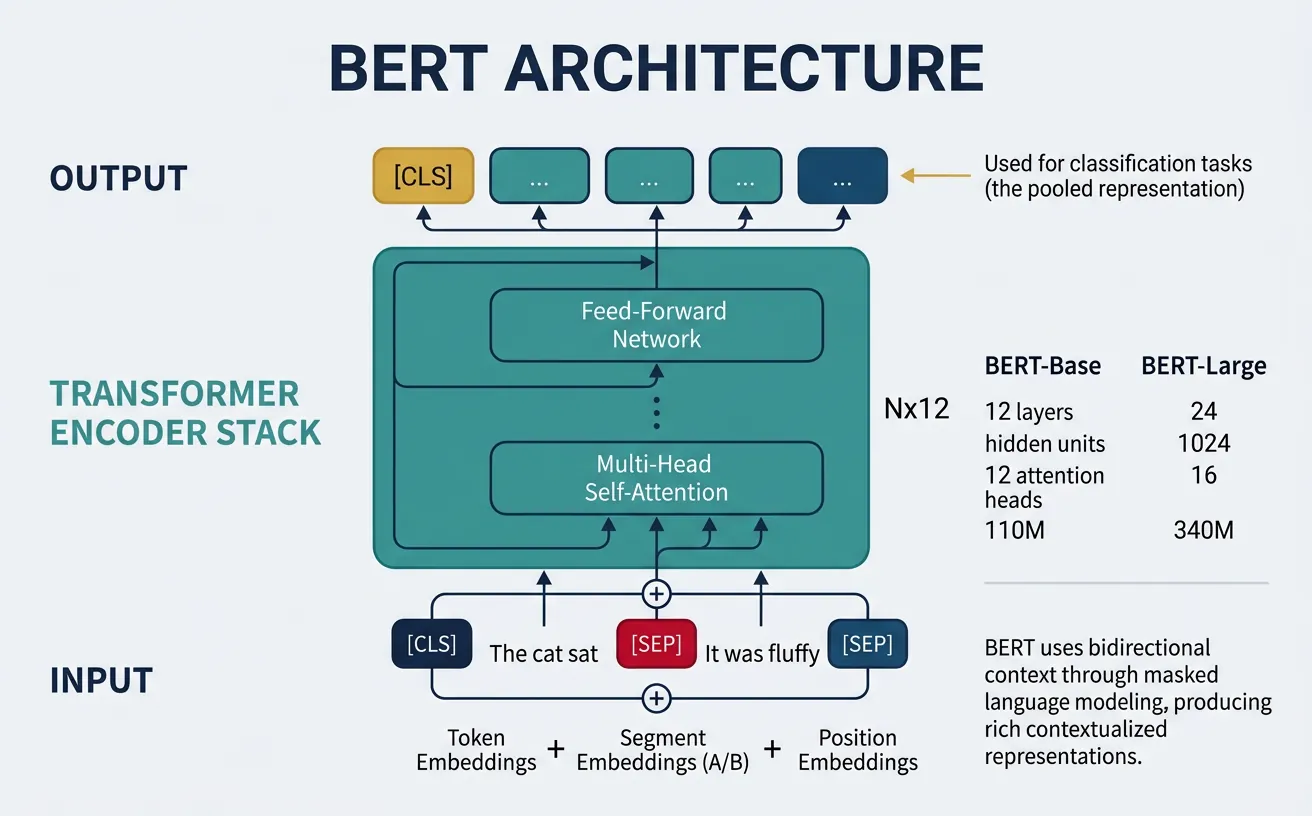
The [CLS] token's final hidden state serves as the aggregate sequence representation for classification tasks. Each input sequence begins with [CLS], and for sentence-pair tasks, [SEP] tokens separate the two sentences. Learned position embeddings and segment embeddings are added to token embeddings before processing through the transformer layers.
from transformers import BertModel, BertTokenizer
import torch
# Load BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Print model architecture summary
print("BERT-Base Architecture:")
print(f" Vocabulary size: {model.config.vocab_size}")
print(f" Hidden size: {model.config.hidden_size}")
print(f" Num layers: {model.config.num_hidden_layers}")
print(f" Num attention heads: {model.config.num_attention_heads}")
print(f" Max position embeddings: {model.config.max_position_embeddings}")
print(f" Total parameters: {sum(p.numel() for p in model.parameters()):,}")
# Example encoding
text = "BERT learns bidirectional representations."
inputs = tokenizer(text, return_tensors='pt')
# Get outputs
with torch.no_grad():
outputs = model(**inputs)
# Examine output shapes
print(f"\nOutput shapes:")
print(f" last_hidden_state: {outputs.last_hidden_state.shape}") # [batch, seq_len, hidden]
print(f" pooler_output (CLS): {outputs.pooler_output.shape}") # [batch, hidden]BERT Input Representation
BERT's input embedding is the sum of three components:
- Token Embeddings: WordPiece token representations from the vocabulary
- Position Embeddings: Learned embeddings for positions 0 to 511
- Segment Embeddings: Distinguish first sentence (A) from second sentence (B)
from transformers import BertTokenizer, BertModel
import torch
# Load model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Sentence pair example
sentence_a = "How old are you?"
sentence_b = "I am 25 years old."
# Tokenize with special tokens
encoding = tokenizer(
sentence_a,
sentence_b,
return_tensors='pt',
padding=True,
truncation=True,
max_length=128
)
# Examine tokenization
tokens = tokenizer.convert_ids_to_tokens(encoding['input_ids'][0])
print("Tokens:", tokens)
print("\nSpecial tokens:")
print(f" [CLS] id: {tokenizer.cls_token_id}")
print(f" [SEP] id: {tokenizer.sep_token_id}")
print(f" [MASK] id: {tokenizer.mask_token_id}")
print(f" [PAD] id: {tokenizer.pad_token_id}")
# Token type IDs show sentence segments
print(f"\nToken type IDs: {encoding['token_type_ids'][0].tolist()}")
print(" (0 = sentence A, 1 = sentence B)")BERT Variants
Following BERT's success, researchers developed numerous variants that improved upon the original architecture through better pretraining strategies, more efficient architectures, or different training objectives. These variants offer trade-offs between performance, efficiency, and computational requirements.
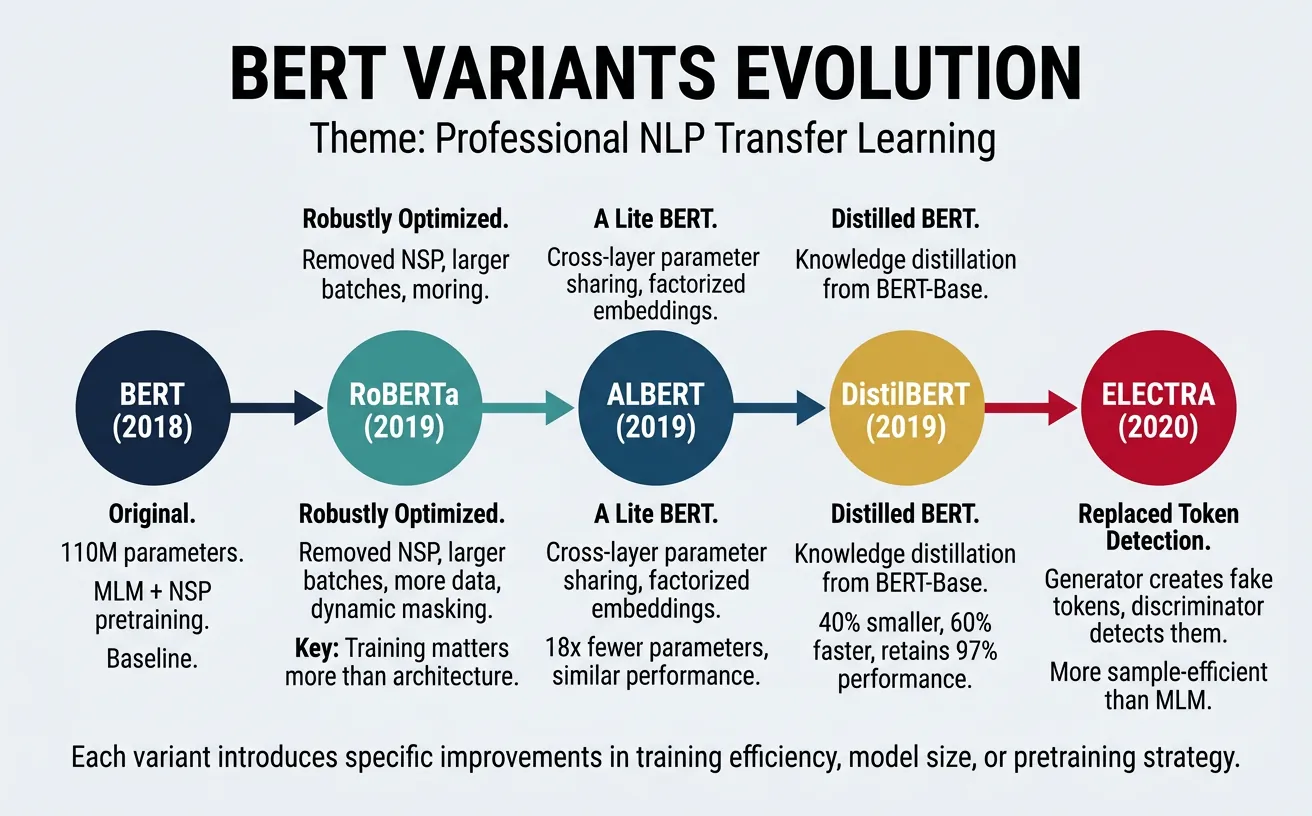
RoBERTa
RoBERTa (Robustly Optimized BERT Approach) by Facebook AI demonstrated that BERT was significantly undertrained. By training longer on more data, using dynamic masking, removing NSP, and training with larger batches, RoBERTa achieved state-of-the-art results on most NLP benchmarks while using the same architecture as BERT.
Key improvements include: training on 10x more data (160GB vs 16GB), removing the problematic NSP objective, using dynamic masking (different masks each epoch rather than static), larger mini-batches (8K sequences), and training for longer (500K steps vs 1M steps but with larger batches). These seemingly simple changes led to substantial performance gains.
from transformers import RobertaTokenizer, RobertaModel
import torch
# Load RoBERTa
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaModel.from_pretrained('roberta-base')
# RoBERTa uses byte-level BPE, slightly different from BERT
text = "RoBERTa uses byte-level BPE tokenization."
inputs = tokenizer(text, return_tensors='pt')
print("RoBERTa-Base Configuration:")
print(f" Hidden size: {model.config.hidden_size}")
print(f" Vocabulary size: {model.config.vocab_size}")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
# Get embeddings
with torch.no_grad():
outputs = model(**inputs)
# RoBERTa uses <s> and </s> instead of [CLS] and [SEP]
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
print(f"\nTokens: {tokens}")
print(f"CLS embedding shape: {outputs.last_hidden_state[:, 0, :].shape}")BERT vs RoBERTa Key Differences
| Aspect | BERT | RoBERTa |
|---|---|---|
| Training Data | 16GB (BooksCorpus + Wikipedia) | 160GB (+ CC-News, OpenWebText, Stories) |
| NSP Objective | Yes | No (removed) |
| Masking Strategy | Static (same masks) | Dynamic (different each epoch) |
| Batch Size | 256 | 8,192 |
| Training Steps | 1M | 500K (but with larger batches) |
ALBERT
ALBERT (A Lite BERT) by Google Research addresses BERT's memory limitations and training time through two parameter reduction techniques: factorized embedding parameterization and cross-layer parameter sharing. These changes dramatically reduce the number of parameters while maintaining or improving performance.
Factorized embedding decomposes the embedding matrix into two smaller matrices, separating the vocabulary embedding dimension (E) from the hidden layer dimension (H). Cross-layer parameter sharing means all transformer layers share the same weights, reducing parameters proportionally to the number of layers. ALBERT-xxlarge achieves state-of-the-art with only 235M parameters compared to BERT-large's 340M.
from transformers import AlbertTokenizer, AlbertModel
import torch
# Load ALBERT
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertModel.from_pretrained('albert-base-v2')
print("ALBERT-Base-v2 Configuration:")
print(f" Hidden size: {model.config.hidden_size}")
print(f" Embedding size: {model.config.embedding_size}") # Factorized!
print(f" Num hidden groups: {model.config.num_hidden_groups}") # Shared layers
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
# Compare with BERT parameter count
# BERT-base: ~110M, ALBERT-base: ~12M (9x smaller!)
text = "ALBERT uses parameter sharing to reduce model size."
inputs = tokenizer(text, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
print(f"\nOutput shape: {outputs.last_hidden_state.shape}")
print(f"Tokens: {tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])}")ELECTRA
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) uses a novel "replaced token detection" pretraining task. Instead of predicting masked tokens, ELECTRA learns to distinguish real input tokens from plausible fakes generated by a small generator network. This approach is more sample-efficient because the model learns from all tokens, not just the 15% that are masked.
The architecture consists of a generator (small MLM model) that proposes replacements for masked tokens, and a discriminator (the main model) that learns to detect which tokens were replaced. After pretraining, only the discriminator is used for downstream tasks. ELECTRA-small matches BERT-base performance while training with 1/4 the compute, making it ideal for resource-constrained settings.
from transformers import ElectraTokenizer, ElectraForPreTraining
import torch
# Load ELECTRA
tokenizer = ElectraTokenizer.from_pretrained('google/electra-small-discriminator')
model = ElectraForPreTraining.from_pretrained('google/electra-small-discriminator')
print("ELECTRA-Small Configuration:")
print(f" Hidden size: {model.config.hidden_size}")
print(f" Num layers: {model.config.num_hidden_layers}")
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}")
# ELECTRA discriminator predicts if each token is original or replaced
sentence = "The chef cooked a delicious dinner"
fake_sentence = "The chef cooked a delicious laptop" # "laptop" is fake
inputs = tokenizer(fake_sentence, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# Each position gets a score (higher = more likely replaced)
is_replaced_scores = outputs.logits.squeeze()
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
print("\nReplacement detection scores:")
for token, score in zip(tokens, is_replaced_scores.tolist()):
status = "FAKE" if score > 0 else "real"
print(f" {token:12s}: {score:+.3f} ({status})")DistilBERT: Knowledge Distillation
DistilBERT uses knowledge distillation to create a smaller, faster model that retains 97% of BERT's performance while being 60% smaller and 60% faster. The student model learns to match the teacher's output distributions, attention patterns, and hidden representations. This makes DistilBERT ideal for production deployment where inference speed matters.
from transformers import DistilBertTokenizer, DistilBertModel
import torch
# Load DistilBERT - 40% smaller, 60% faster than BERT
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained('distilbert-base-uncased')
print("DistilBERT Configuration:")
print(f" Hidden size: {model.config.hidden_size}")
print(f" Num layers: {model.config.num_hidden_layers}") # 6 vs BERT's 12
print(f" Parameters: {sum(p.numel() for p in model.parameters()):,}") # ~66M vs 110M
# DistilBERT has no token_type_ids (no segment embeddings)
text = "DistilBERT is fast and efficient."
inputs = tokenizer(text, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
print(f"\nOutput shape: {outputs.last_hidden_state.shape}")Fine-Tuning Strategies
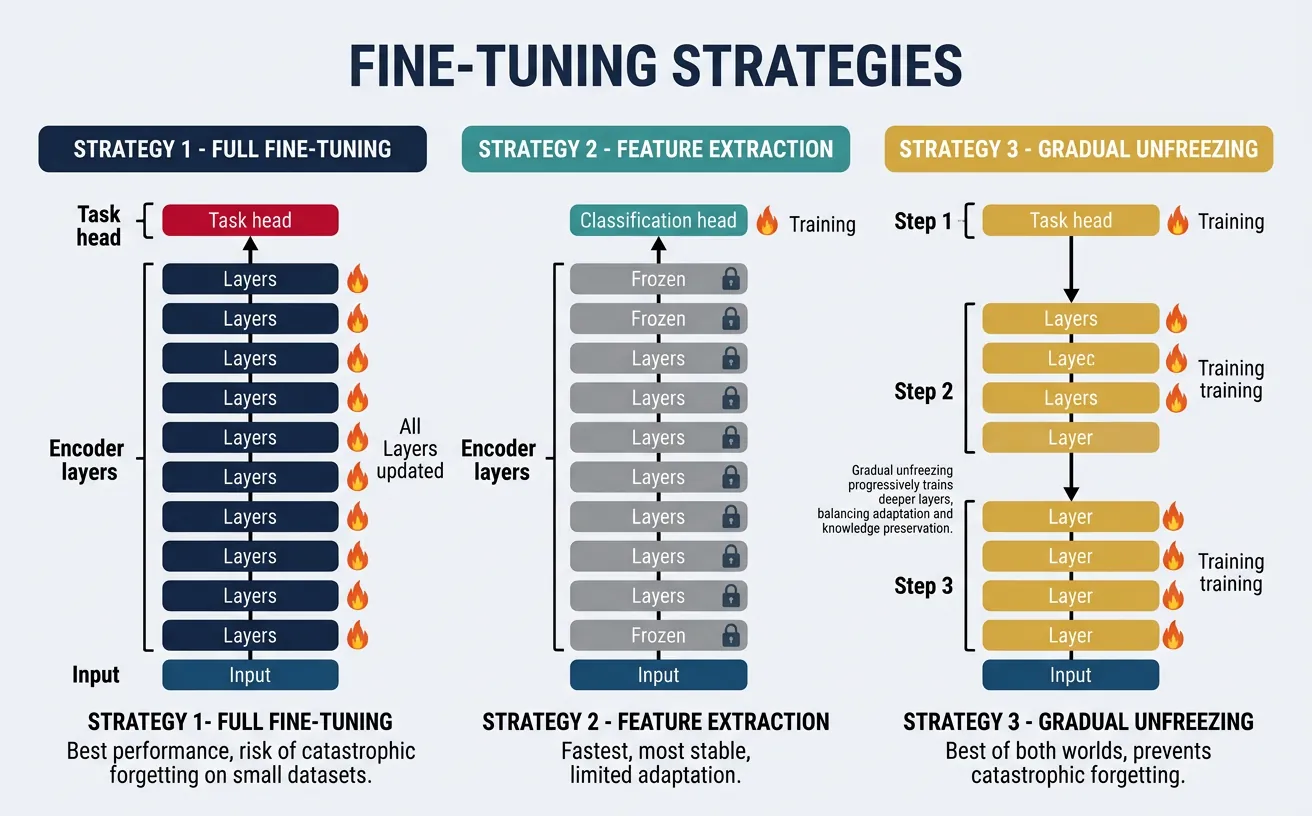
Fine-tuning adapts a pretrained model to a specific downstream task by continuing training on task-specific labeled data. The key decisions involve: which layers to fine-tune, what learning rate to use, how long to train, and how to prevent catastrophic forgetting of the pretrained knowledge. Different strategies suit different scenarios based on data availability and task similarity to pretraining.
Full fine-tuning updates all model parameters, typically with a small learning rate (2e-5 to 5e-5) to avoid overwriting pretrained knowledge. This works best when you have moderate amounts of labeled data (10K+ examples). Training typically converges in 3-4 epochs, and it's important to monitor validation performance to avoid overfitting.
graph TD
PT["Pre-trained Model
(BERT / GPT / T5)"]
PT --> FE["Feature Extraction
Freeze all layers
Train only classifier head"]
PT --> FT["Full Fine-Tuning
Unfreeze all layers
Lower learning rate"]
PT --> LL["Last-Layer Fine-Tuning
Freeze most layers
Train last N layers"]
PT --> AD["Adapter Tuning
Insert small adapter modules
Train only adapters (~2-5% params)"]
PT --> LR["LoRA / QLoRA
Low-rank weight updates
Parameter-efficient"]
FE --> USE1["Small dataset
Quick baseline"]
FT --> USE2["Large dataset
Domain-specific task"]
LL --> USE3["Medium dataset
Balance speed & quality"]
AD --> USE4["Multi-task scenarios
Modular & composable"]
LR --> USE5["Large LLMs
Memory-efficient"]
style PT fill:#132440,stroke:#132440,color:#fff
style LR fill:#e8f4f4,stroke:#3B9797
Feature extraction freezes pretrained weights and only trains the task-specific head. This is faster and prevents overfitting when labeled data is scarce, but may underperform full fine-tuning. A middle ground is gradual unfreezing, which starts with frozen layers and progressively unfreezes from top to bottom during training.
from transformers import BertForSequenceClassification, BertTokenizer
import torch
# Load pretrained BERT with classification head
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels=2 # Binary classification
)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Strategy 1: Full fine-tuning (all parameters trainable)
for param in model.parameters():
param.requires_grad = True
trainable_full = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Full fine-tuning: {trainable_full:,} trainable parameters")
# Strategy 2: Feature extraction (freeze encoder, train classifier only)
for param in model.bert.parameters():
param.requires_grad = False
# Only classifier is trainable
trainable_head = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Feature extraction: {trainable_head:,} trainable parameters")
# Strategy 3: Freeze embeddings and early layers only
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# Freeze embeddings
for param in model.bert.embeddings.parameters():
param.requires_grad = False
# Freeze first 6 layers
for layer in model.bert.encoder.layer[:6]:
for param in layer.parameters():
param.requires_grad = False
trainable_partial = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Partial fine-tuning (last 6 layers + head): {trainable_partial:,} parameters")Learning Rate Strategies
- Discriminative Learning Rates: Lower LR for bottom layers (2e-5), higher for top layers (5e-5)
- Linear Warmup: Start at 0, increase linearly for first 10% of steps, then decay
- Layer-wise Decay: Multiply LR by 0.95 for each layer from top to bottom
- Typical Range: 1e-5 to 5e-5 for fine-tuning (much smaller than pretraining)
from transformers import BertForSequenceClassification, get_linear_schedule_with_warmup
from torch.optim import AdamW
import torch
# Load model
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# Discriminative learning rates: lower for encoder, higher for classifier
optimizer_grouped_parameters = [
{
'params': model.bert.embeddings.parameters(),
'lr': 1e-5 # Lowest LR for embeddings
},
{
'params': model.bert.encoder.parameters(),
'lr': 2e-5 # Medium LR for encoder layers
},
{
'params': model.classifier.parameters(),
'lr': 5e-5 # Higher LR for task head
}
]
optimizer = AdamW(optimizer_grouped_parameters, weight_decay=0.01)
# Linear warmup + decay schedule
num_training_steps = 1000
num_warmup_steps = 100 # 10% warmup
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=num_warmup_steps,
num_training_steps=num_training_steps
)
print("Learning rate schedule:")
for i, step in enumerate([0, 50, 100, 500, 1000]):
# Simulate steps
for _ in range(step - (i > 0 and [0, 50, 100, 500, 1000][i-1] or 0)):
scheduler.step()
print(f" Step {step}: LR = {scheduler.get_last_lr()[0]:.2e}")Adding a Classification Head to a Pretrained LLM
The most common fine-tuning pattern is to add a classification head on top of a pretrained model. For encoder models like BERT, we extract the [CLS] token's final hidden state and pass it through a linear layer. For decoder models like GPT, we use the last token's hidden state (since it has attended to all previous tokens via causal attention). This simple approach converts a general language model into a powerful classifier.
import torch
import torch.nn as nn
from transformers import GPT2Model, GPT2Tokenizer
class GPTClassifier(nn.Module):
"""Fine-tune GPT-2 for text classification.
Key insight: In a causal (left-to-right) model, the LAST token's
hidden state has attended to ALL previous tokens, making it the
natural choice for classification (analogous to BERT's [CLS]).
"""
def __init__(self, model_name='gpt2', num_classes=2):
super().__init__()
self.gpt = GPT2Model.from_pretrained(model_name)
d_model = self.gpt.config.n_embd # 768 for gpt2-base
# Classification head: project last token's hidden state to num_classes
self.classifier = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(d_model, num_classes),
)
# Freeze GPT-2 backbone initially (optional)
for param in self.gpt.parameters():
param.requires_grad = False
def forward(self, input_ids, attention_mask=None):
# Get all hidden states from GPT-2
outputs = self.gpt(input_ids, attention_mask=attention_mask)
hidden_states = outputs.last_hidden_state # (batch, seq_len, 768)
# Use the LAST token's representation for classification
# (it has seen all previous tokens via causal attention)
if attention_mask is not None:
# Find the last non-padding position for each sample
last_positions = attention_mask.sum(dim=1) - 1 # (batch,)
last_hidden = hidden_states[
torch.arange(hidden_states.size(0)), last_positions
]
else:
last_hidden = hidden_states[:, -1, :] # Simply take last position
logits = self.classifier(last_hidden) # (batch, num_classes)
return logits
# Example usage
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
tokenizer.pad_token = tokenizer.eos_token # GPT-2 has no pad token by default
model = GPTClassifier(num_classes=3)
# Count parameters
total = sum(p.numel() for p in model.parameters())
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total parameters: {total:,}")
print(f"Trainable parameters: {trainable:,} ({trainable/total*100:.1f}%)")
print(f"Frozen (GPT-2): {total - trainable:,}")
# Forward pass
texts = ["This movie was great!", "Terrible waste of time."]
encoded = tokenizer(texts, padding=True, return_tensors='pt')
logits = model(encoded['input_ids'], encoded['attention_mask'])
predictions = logits.argmax(dim=-1)
print(f"\nInput: {texts}")
print(f"Logits shape: {logits.shape}")
print(f"Predictions: {predictions.tolist()}")
BERT [CLS] vs GPT Last Token
BERT uses the [CLS] token (first position) because bidirectional attention means every position can see every other position — but [CLS] is specifically trained as a summary representation. GPT uses the last token because causal (left-to-right) attention means only the last position has attended to the entire sequence. Both achieve the same goal: extracting a single vector that represents the whole input for classification.
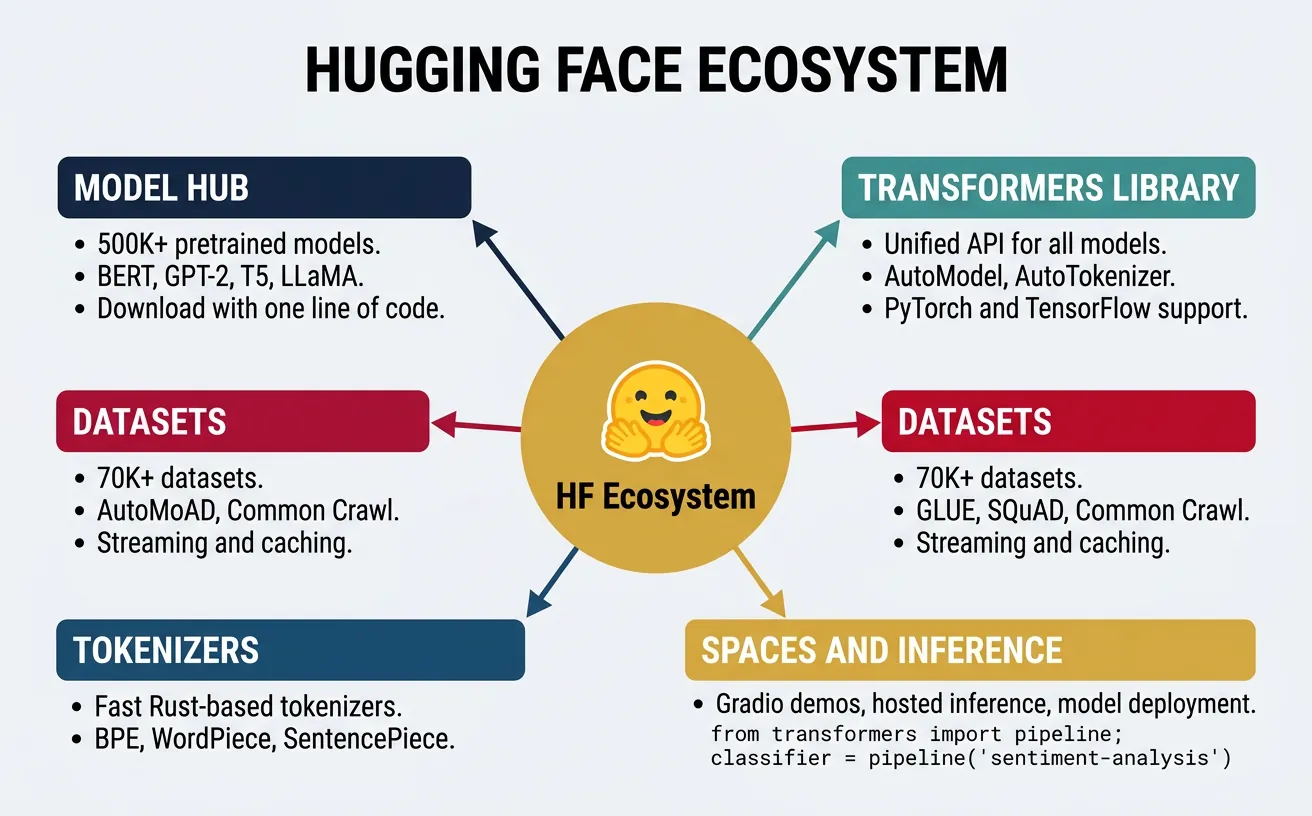
Hugging Face Transformers
The Hugging Face Transformers library has become the de facto standard for working with pretrained language models. It provides a unified API for loading, using, and fine-tuning hundreds of models across different architectures. The library abstracts away implementation details while providing flexibility for advanced users.
Key components include: AutoClasses that automatically infer the correct model/tokenizer class, Trainer API for simplified training loops, Pipelines for inference on common tasks, and integration with the Hugging Face Hub for sharing models. The ecosystem also includes Datasets for efficient data loading and Evaluate for metrics computation.
from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification
from transformers import pipeline
import torch
# AutoClasses automatically detect the right class
model_name = 'bert-base-uncased'
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
print(f"Loaded {model.__class__.__name__}")
print(f"Tokenizer: {tokenizer.__class__.__name__}")
# Pipelines provide one-line inference
sentiment_pipeline = pipeline(
'sentiment-analysis',
model='distilbert-base-uncased-finetuned-sst-2-english'
)
texts = [
"This movie was absolutely fantastic!",
"I really didn't enjoy this book at all.",
"The weather is okay today."
]
results = sentiment_pipeline(texts)
for text, result in zip(texts, results):
print(f"\n'{text[:40]}...'")
print(f" Label: {result['label']}, Score: {result['score']:.3f}")Hugging Face Ecosystem
Key Libraries:
- transformers: Core library for models and tokenizers
- datasets: Efficient data loading with memory mapping and streaming
- evaluate: Metrics for model evaluation
- accelerate: Distributed training and mixed precision
- peft: Parameter-efficient fine-tuning (LoRA, adapters)
from transformers import AutoTokenizer, DataCollatorWithPadding
from datasets import load_dataset
import torch
# Load a dataset from Hugging Face Hub
dataset = load_dataset('imdb', split='train[:1000]') # First 1000 examples
print(f"Dataset features: {dataset.features}")
print(f"Number of examples: {len(dataset)}")
print(f"\nFirst example:")
print(f" Text: {dataset[0]['text'][:100]}...")
print(f" Label: {dataset[0]['label']}")
# Tokenize the dataset
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(examples):
return tokenizer(
examples['text'],
truncation=True,
max_length=512
)
tokenized_dataset = dataset.map(
tokenize_function,
batched=True,
remove_columns=['text']
)
print(f"\nTokenized features: {tokenized_dataset.features}")
print(f"First example tokens: {tokenized_dataset[0]['input_ids'][:10]}...")Practical Implementation
Let's implement end-to-end fine-tuning for three common NLP tasks: text classification, named entity recognition (NER), and question answering. Each example demonstrates the complete workflow from data loading to evaluation.
Text Classification Fine-tuning
Text classification assigns labels to documents. For sentiment analysis, we fine-tune BERT to predict positive/negative sentiment from movie reviews. The model adds a linear classification head on top of the [CLS] token representation.
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer
)
from datasets import load_dataset
import numpy as np
# Load IMDB dataset
dataset = load_dataset('imdb')
# Load tokenizer and model
model_name = 'distilbert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=2,
id2label={0: 'NEGATIVE', 1: 'POSITIVE'},
label2id={'NEGATIVE': 0, 'POSITIVE': 1}
)
# Tokenization function
def tokenize(examples):
return tokenizer(
examples['text'],
truncation=True,
max_length=256,
padding='max_length'
)
# Tokenize dataset
tokenized_train = dataset['train'].shuffle(seed=42).select(range(2000)).map(
tokenize, batched=True, remove_columns=['text']
)
tokenized_test = dataset['test'].shuffle(seed=42).select(range(500)).map(
tokenize, batched=True, remove_columns=['text']
)
print(f"Training examples: {len(tokenized_train)}")
print(f"Test examples: {len(tokenized_test)}")
print(f"Features: {tokenized_train.features}")from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer
)
from datasets import load_dataset
import numpy as np
# Setup (abbreviated - uses tokenized data from above)
model_name = 'distilbert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Define compute_metrics function
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
accuracy = (predictions == labels).mean()
return {'accuracy': accuracy}
# Training arguments
training_args = TrainingArguments(
output_dir='./sentiment_model',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
learning_rate=2e-5,
weight_decay=0.01,
warmup_ratio=0.1,
evaluation_strategy='epoch',
save_strategy='epoch',
load_best_model_at_end=True,
logging_steps=50,
report_to='none' # Disable wandb/tensorboard
)
print("Training Configuration:")
print(f" Epochs: {training_args.num_train_epochs}")
print(f" Batch size: {training_args.per_device_train_batch_size}")
print(f" Learning rate: {training_args.learning_rate}")
print(f" Warmup ratio: {training_args.warmup_ratio}")Named Entity Recognition (NER)
NER identifies and classifies named entities (persons, organizations, locations, etc.) in text. This is a token classification task where each token receives a label. We use the BIO tagging scheme: B-PER (beginning of person), I-PER (inside person), O (outside any entity).
from transformers import (
AutoTokenizer,
AutoModelForTokenClassification,
pipeline
)
import torch
# Load pre-trained NER model
model_name = 'dslim/bert-base-NER'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
# Check label mapping
print("NER Labels:")
for id, label in model.config.id2label.items():
print(f" {id}: {label}")
# Use pipeline for easy inference
ner_pipeline = pipeline('ner', model=model, tokenizer=tokenizer, aggregation_strategy='simple')
# Test on sample text
text = "Apple Inc. was founded by Steve Jobs in Cupertino, California."
entities = ner_pipeline(text)
print(f"\nText: {text}")
print("\nDetected Entities:")
for entity in entities:
print(f" {entity['word']:20s} | {entity['entity_group']:5s} | Score: {entity['score']:.3f}")from transformers import AutoTokenizer, AutoModelForTokenClassification
import torch
# Manual token classification (understanding the internals)
model_name = 'dslim/bert-base-NER'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
text = "Barack Obama was the 44th President of the United States."
inputs = tokenizer(text, return_tensors='pt', return_offsets_mapping=True)
# Get predictions
with torch.no_grad():
outputs = model(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask']
)
# Convert logits to predictions
predictions = torch.argmax(outputs.logits, dim=-1).squeeze().tolist()
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'].squeeze())
print("Token-level NER predictions:")
print("-" * 50)
for token, pred_id in zip(tokens, predictions):
label = model.config.id2label[pred_id]
if label != 'O': # Only show entities
print(f" {token:15s} -> {label}")Question Answering
Extractive question answering finds answer spans within a given context. The model learns to predict start and end positions of the answer in the context. This requires handling long contexts with sliding window approaches when context exceeds the maximum sequence length.
from transformers import AutoTokenizer, AutoModelForQuestionAnswering, pipeline
import torch
# Load QA model
model_name = 'distilbert-base-cased-distilled-squad'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
# Use pipeline for easy inference
qa_pipeline = pipeline('question-answering', model=model, tokenizer=tokenizer)
# Example context and questions
context = """
The Transformer architecture was introduced in the paper "Attention Is All You Need"
by Vaswani et al. in 2017. It revolutionized natural language processing by replacing
recurrent neural networks with self-attention mechanisms. The original Transformer
was designed for machine translation but has since been adapted for virtually all NLP tasks.
BERT, introduced by Google in 2018, is an encoder-only Transformer pretrained using
masked language modeling. GPT, from OpenAI, is a decoder-only Transformer using causal
language modeling.
"""
questions = [
"When was the Transformer introduced?",
"What did the Transformer replace?",
"Who introduced BERT?",
"What type of Transformer is GPT?"
]
print("Question Answering Demo")
print("=" * 60)
for question in questions:
result = qa_pipeline(question=question, context=context)
print(f"\nQ: {question}")
print(f"A: {result['answer']} (confidence: {result['score']:.3f})")from transformers import AutoTokenizer, AutoModelForQuestionAnswering
import torch
# Manual QA (understanding start/end logits)
model_name = 'distilbert-base-cased-distilled-squad'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
question = "What is BERT pretrained with?"
context = "BERT is pretrained using masked language modeling and next sentence prediction."
# Tokenize
inputs = tokenizer(
question,
context,
return_tensors='pt',
truncation=True,
max_length=512
)
# Get start/end logits
with torch.no_grad():
outputs = model(**inputs)
# Find best start and end positions
start_idx = torch.argmax(outputs.start_logits)
end_idx = torch.argmax(outputs.end_logits)
# Decode answer
input_ids = inputs['input_ids'].squeeze()
answer_tokens = input_ids[start_idx:end_idx + 1]
answer = tokenizer.decode(answer_tokens)
print(f"Question: {question}")
print(f"Context: {context}")
print(f"\nStart position: {start_idx.item()}, End position: {end_idx.item()}")
print(f"Answer: {answer}")
# Show confidence scores
start_prob = torch.softmax(outputs.start_logits, dim=-1)[0, start_idx].item()
end_prob = torch.softmax(outputs.end_logits, dim=-1)[0, end_idx].item()
print(f"Start confidence: {start_prob:.3f}, End confidence: {end_prob:.3f}")Complete Fine-tuning Example with Trainer
Here's a complete, runnable fine-tuning script combining all components:
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer,
EarlyStoppingCallback
)
from datasets import load_dataset
import numpy as np
import torch
# Configuration
MODEL_NAME = 'distilbert-base-uncased'
NUM_LABELS = 2
MAX_LENGTH = 256
TRAIN_SIZE = 5000
TEST_SIZE = 1000
# Load and prepare data
print("Loading dataset...")
dataset = load_dataset('imdb')
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
def preprocess(examples):
return tokenizer(
examples['text'],
truncation=True,
max_length=MAX_LENGTH,
padding='max_length'
)
train_data = dataset['train'].shuffle(seed=42).select(range(TRAIN_SIZE))
test_data = dataset['test'].shuffle(seed=42).select(range(TEST_SIZE))
train_tokenized = train_data.map(preprocess, batched=True, remove_columns=['text'])
test_tokenized = test_data.map(preprocess, batched=True, remove_columns=['text'])
# Load model
print("Loading model...")
model = AutoModelForSequenceClassification.from_pretrained(
MODEL_NAME,
num_labels=NUM_LABELS
)
# Metrics
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
accuracy = (predictions == labels).mean()
return {'accuracy': accuracy}
# Training setup
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
learning_rate=2e-5,
warmup_steps=500,
weight_decay=0.01,
evaluation_strategy='steps',
eval_steps=500,
save_steps=500,
logging_steps=100,
load_best_model_at_end=True,
metric_for_best_model='accuracy',
report_to='none'
)
# Create Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_tokenized,
eval_dataset=test_tokenized,
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)]
)
print("Ready to train! Call trainer.train() to start.")
print(f"Training samples: {len(train_tokenized)}")
print(f"Evaluation samples: {len(test_tokenized)}")Feature Extraction vs Fine-tuning Comparison
Let's compare the two approaches on the same task to understand the trade-offs. Feature extraction is faster but may underperform; fine-tuning is slower but usually achieves better results.
from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification
import torch
import torch.nn as nn
# Approach 1: Feature Extraction (frozen encoder)
class FeatureExtractor(nn.Module):
def __init__(self, model_name, num_labels):
super().__init__()
self.encoder = AutoModel.from_pretrained(model_name)
# Freeze encoder
for param in self.encoder.parameters():
param.requires_grad = False
# Trainable classifier
self.classifier = nn.Linear(self.encoder.config.hidden_size, num_labels)
def forward(self, input_ids, attention_mask):
with torch.no_grad(): # No gradients through encoder
outputs = self.encoder(input_ids=input_ids, attention_mask=attention_mask)
cls_embedding = outputs.last_hidden_state[:, 0, :]
return self.classifier(cls_embedding)
# Approach 2: Full Fine-tuning
class FullFineTuner(nn.Module):
def __init__(self, model_name, num_labels):
super().__init__()
self.model = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=num_labels
)
def forward(self, input_ids, attention_mask):
return self.model(input_ids=input_ids, attention_mask=attention_mask).logits
# Compare parameter counts
model_name = 'distilbert-base-uncased'
num_labels = 2
fe_model = FeatureExtractor(model_name, num_labels)
ff_model = FullFineTuner(model_name, num_labels)
fe_trainable = sum(p.numel() for p in fe_model.parameters() if p.requires_grad)
ff_trainable = sum(p.numel() for p in ff_model.parameters() if p.requires_grad)
print("Parameter Comparison:")
print(f" Feature Extraction: {fe_trainable:,} trainable params")
print(f" Full Fine-tuning: {ff_trainable:,} trainable params")
print(f" Ratio: {ff_trainable / fe_trainable:.0f}x more parameters in fine-tuning")Conclusion & Next Steps
Pretrained language models have fundamentally transformed NLP by enabling transfer learning at scale. BERT introduced bidirectional pretraining through masked language modeling, while variants like RoBERTa, ALBERT, and ELECTRA offered improvements in training efficiency, model compression, and sample efficiency. The Hugging Face ecosystem has made these powerful models accessible to practitioners worldwide.
Key takeaways from this guide include understanding the pretraining-finetuning paradigm, choosing appropriate models based on your constraints (compute, data, latency), and implementing effective fine-tuning strategies. For most practitioners, starting with DistilBERT or BERT-base provides a good balance of performance and efficiency, while RoBERTa offers state-of-the-art quality when resources permit.
In the next part of our series, we'll explore GPT Models & Text Generation, diving into autoregressive language models, the decoder-only architecture, and techniques for controlled text generation including sampling strategies, prompt engineering, and instruction following.
Practice Exercises
- Fine-tune BERT on a custom text classification dataset using the Trainer API
- Compare RoBERTa and DistilBERT on the same task—measure accuracy vs. inference speed
- Implement gradual unfreezing: freeze all layers initially, unfreeze one layer per epoch
- Use ELECTRA for NER and compare performance with BERT-based models
- Build a question-answering system that handles long documents with sliding windows
Further Reading
- BERT Paper: "BERT: Pre-training of Deep Bidirectional Transformers" (Devlin et al., 2019)
- RoBERTa Paper: "RoBERTa: A Robustly Optimized BERT Pretraining Approach" (Liu et al., 2019)
- ALBERT Paper: "ALBERT: A Lite BERT for Self-supervised Learning" (Lan et al., 2020)
- ELECTRA Paper: "ELECTRA: Pre-training Text Encoders as Discriminators" (Clark et al., 2020)
- Hugging Face Course: huggingface.co/course