Introduction to Language Models
Statistical language models assign probabilities to sequences of words, enabling prediction of the next word given context. This foundational concept underlies everything from autocomplete to modern transformers.
Key Insight
Language models learn to predict P(w|context)—the probability of a word given its context. N-gram models approximate this using fixed-length history.
NLP Mastery
NLP Fundamentals & Linguistic Basics
Phonology, morphology, syntax, semantics, pragmaticsTokenization & Text Cleaning
Subword tokenization, BPE, stopwords, normalizationText Representation & Feature Engineering
Bag-of-words, TF-IDF, feature extraction, vectorizationWord Embeddings
Word2Vec, GloVe, FastText, embedding spaces, analogiesStatistical Language Models & N-grams
Probability chains, smoothing, perplexity, Markov modelsNeural Networks for NLP
Feedforward nets, backpropagation, activation functionsRNNs, LSTMs & GRUs
Sequence modeling, vanishing gradients, gated architecturesTransformers & Attention Mechanism
Self-attention, multi-head attention, positional encodingPretrained Language Models & Transfer Learning
BERT, RoBERTa, fine-tuning, feature extractionGPT Models & Text Generation
Autoregressive generation, prompting, GPT architectureCore NLP Tasks
NER, POS tagging, sentiment analysis, text classificationAdvanced NLP Tasks
Question answering, summarization, machine translationMultilingual & Cross-lingual NLP
mBERT, XLM-R, zero-shot transfer, language diversityEvaluation, Ethics & Responsible NLP
BLEU, ROUGE, bias detection, fairness, responsible AINLP Systems, Optimization & Production
Model serving, quantization, distillation, deploymentCutting-Edge & Research Topics
LLMs, multimodal NLP, reasoning, emerging researchProbability & Language
At the heart of statistical language models lies the fundamental question: "How likely is this sequence of words?" Language models assign probabilities to sequences of words, enabling us to determine that "The cat sat on the mat" is more probable than "Mat the on sat cat the." This probabilistic framework forms the foundation for countless NLP applications, from speech recognition to machine translation.
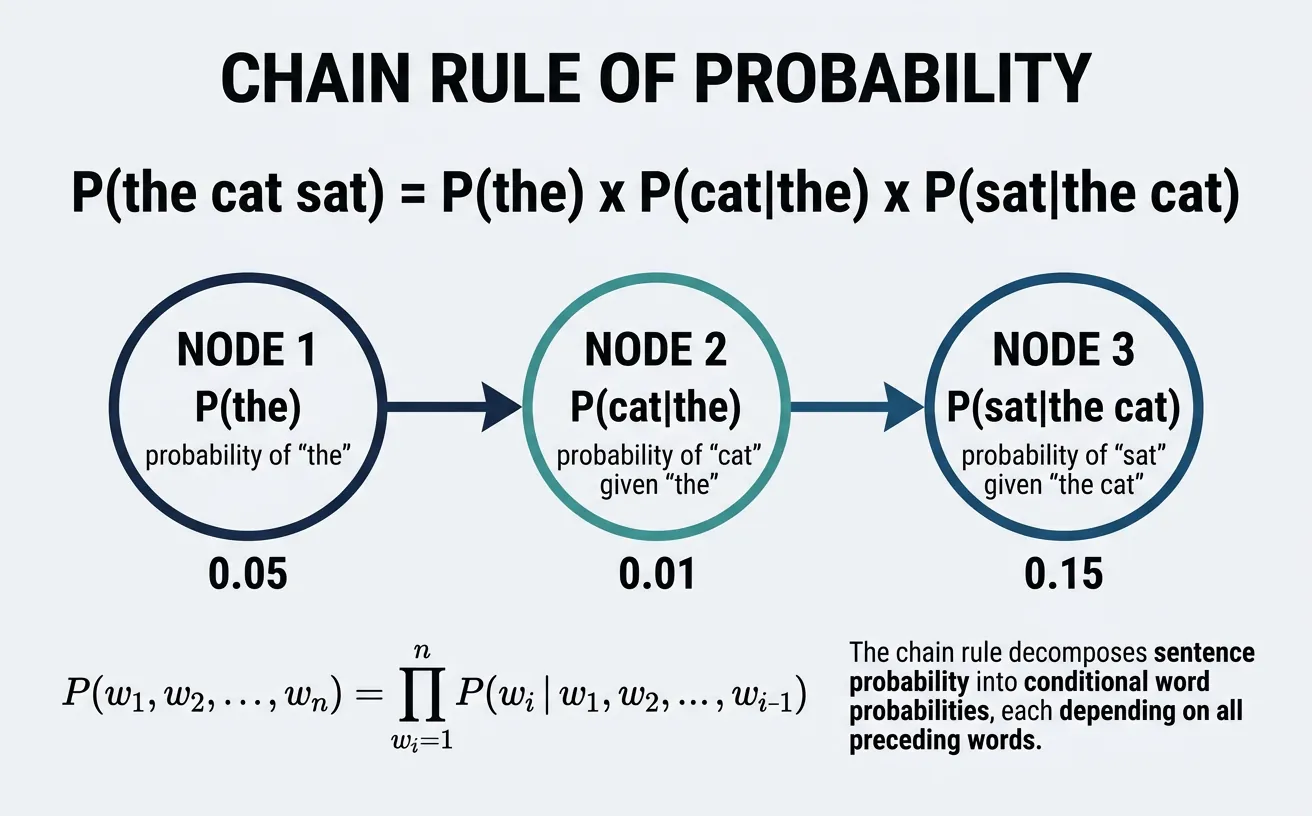
The probability of a sentence can be decomposed using the Chain Rule of Probability. For a sentence W = w1, w2, …, wn, we calculate:
$$P(W) = P(w_1) \times P(w_2|w_1) \times P(w_3|w_1,w_2) \times \cdots \times P(w_n|w_1,\ldots,w_{n-1})$$
This decomposition means the probability of each word depends on all preceding words. While mathematically precise, estimating these conditional probabilities becomes impractical as the history grows—the number of possible histories grows exponentially with sentence length.
import numpy as np
from collections import defaultdict
import random
# Simple probability demonstration with toy corpus
corpus = [
"the cat sat on the mat",
"the dog sat on the floor",
"the cat ate the fish",
"the dog ate the bone",
"the bird sat on the tree"
]
# Count word occurrences
word_counts = defaultdict(int)
total_words = 0
for sentence in corpus:
words = sentence.split()
for word in words:
word_counts[word] += 1
total_words += 1
# Calculate P(word) - unigram probabilities
print("Unigram Probabilities (Maximum Likelihood Estimation):")
print("="*50)
for word, count in sorted(word_counts.items(), key=lambda x: -x[1]):
probability = count / total_words
print(f"P({word:8}) = {count}/{total_words} = {probability:.4f}")
print(f"\nTotal unique words: {len(word_counts)}")
print(f"Total word tokens: {total_words}")The Markov Assumption
N-gram models make a simplifying assumption called the Markov assumption: the probability of a word depends only on the previous n-1 words, not the entire history. This makes estimation tractable while still capturing local context:
$$P(w_n|w_1,\ldots,w_{n-1}) \approx P(w_n|w_{n-k},\ldots,w_{n-1}) \quad \text{for k-gram model}$$
import numpy as np
from collections import defaultdict
# Demonstrate Chain Rule decomposition
sentence = "the cat sat on the mat"
words = sentence.split()
print("Chain Rule Decomposition:")
print("="*60)
print(f"\nSentence: '{sentence}'")
print(f"\nP(sentence) = ", end="")
for i, word in enumerate(words):
if i == 0:
print(f"P({word})", end="")
else:
history = " ".join(words[:i])
print(f" × P({word}|{history})", end="")
print("\n\n" + "="*60)
print("\nWith Bigram (Markov) Assumption:")
print(f"\nP(sentence) ~ ", end="")
for i, word in enumerate(words):
if i == 0:
print(f"P({word})", end="")
else:
print(f" × P({word}|{words[i-1]})", end="")
print("\n")
print("\nNotice: Each probability now depends only on the previous word!")N-gram Models
N-gram models predict the probability of a word based on the previous (n-1) words. The "n" in n-gram refers to the total number of words in the sequence being considered. These models trade off context length against data sparsity—longer contexts capture more information but require exponentially more training data.

N-gram Terminology
- Unigram (n=1): Single words, no context - P(word)
- Bigram (n=2): Word pairs - P(word|previous_word)
- Trigram (n=3): Three-word sequences - P(word|prev_2_words)
- 4-gram, 5-gram: Longer contexts, rarer in practice due to sparsity
Unigrams
A unigram model treats each word independently, ignoring all context. While simple, it captures word frequency distributions and serves as a baseline. The probability of a sentence is simply the product of individual word probabilities:
$$P(w_1, w_2, \ldots, w_n) = P(w_1) \times P(w_2) \times \cdots \times P(w_n)$$
import numpy as np
from collections import Counter
# Training corpus
corpus = [
"I love natural language processing",
"Natural language processing is fascinating",
"I love machine learning too",
"Language models are powerful tools",
"I am learning about language models"
]
class UnigramModel:
def __init__(self):
self.word_counts = Counter()
self.total_words = 0
def train(self, corpus):
"""Train unigram model on corpus"""
for sentence in corpus:
words = sentence.lower().split()
self.word_counts.update(words)
self.total_words += len(words)
def probability(self, word):
"""P(word) - unigram probability"""
word = word.lower()
return self.word_counts[word] / self.total_words
def sentence_probability(self, sentence):
"""P(sentence) using unigram assumption"""
words = sentence.lower().split()
prob = 1.0
for word in words:
prob *= self.probability(word)
return prob
# Train and test
unigram = UnigramModel()
unigram.train(corpus)
print("Unigram Model - Word Probabilities:")
print("="*50)
for word, count in unigram.word_counts.most_common(10):
prob = unigram.probability(word)
print(f"P({word:15}) = {count:2}/{unigram.total_words} = {prob:.4f}")
# Test sentences
test_sentences = [
"I love language",
"machine language processing",
"xyz unknown words"
]
print("\nSentence Probabilities:")
print("="*50)
for sent in test_sentences:
prob = unigram.sentence_probability(sent)
print(f"P('{sent}') = {prob:.10f}")Bigrams
A bigram model conditions each word on the immediately preceding word, capturing local word patterns. This simple extension dramatically improves over unigrams by modeling word co-occurrences like "New York" or "machine learning."
$$P(w_n|w_1,\ldots,w_{n-1}) \approx P(w_n|w_{n-1})$$
import numpy as np
from collections import defaultdict, Counter
class BigramModel:
def __init__(self):
self.bigram_counts = defaultdict(Counter)
self.unigram_counts = Counter()
self.vocab = set()
def train(self, corpus):
"""Train bigram model with start/end tokens"""
for sentence in corpus:
# Add start and end tokens
words = ['<s>'] + sentence.lower().split() + ['</s>']
self.vocab.update(words)
# Count unigrams and bigrams
for i in range(len(words) - 1):
self.unigram_counts[words[i]] += 1
self.bigram_counts[words[i]][words[i+1]] += 1
self.unigram_counts[words[-1]] += 1
def probability(self, word, previous):
"""P(word|previous) using MLE"""
word = word.lower()
previous = previous.lower()
if self.unigram_counts[previous] == 0:
return 0.0
return self.bigram_counts[previous][word] / self.unigram_counts[previous]
def sentence_probability(self, sentence):
"""Calculate sentence probability using bigram model"""
words = ['<s>'] + sentence.lower().split() + ['</s>']
prob = 1.0
for i in range(1, len(words)):
p = self.probability(words[i], words[i-1])
prob *= p
return prob
# Training corpus
corpus = [
"I love natural language processing",
"I love machine learning",
"Natural language processing is fun",
"Machine learning is powerful",
"I enjoy learning new things"
]
# Train model
bigram = BigramModel()
bigram.train(corpus)
print("Bigram Probabilities after 'I':")
print("="*50)
for next_word, count in bigram.bigram_counts['i'].most_common():
prob = bigram.probability(next_word, 'i')
print(f"P({next_word:15}|I) = {count}/{bigram.unigram_counts['i']} = {prob:.4f}")
print("\nBigram Probabilities after 'natural':")
print("="*50)
for next_word, count in bigram.bigram_counts['natural'].most_common():
prob = bigram.probability(next_word, 'natural')
print(f"P({next_word:15}|natural) = {count}/{bigram.unigram_counts['natural']} = {prob:.4f}")
# Test sentences
print("\nSentence Probabilities:")
print("="*50)
test_sentences = ["I love learning", "I love processing", "natural language"]
for sent in test_sentences:
prob = bigram.sentence_probability(sent)
print(f"P('{sent}') = {prob:.6f}")Maximum Likelihood Estimation (MLE)
The standard method for estimating n-gram probabilities is Maximum Likelihood Estimation:
PMLE(wn|wn−1) = Count(wn−1, wn) / Count(wn−1)
MLE simply counts co-occurrences and normalizes. While intuitive, it assigns zero probability to unseen n-grams—a critical flaw we'll address with smoothing.
Trigrams & Higher-Order
Trigram models condition on the previous two words, capturing longer-range dependencies. They model patterns like "New York City" or "to be or." Higher-order models (4-gram, 5-gram) capture even more context but suffer from severe data sparsity—most possible sequences never appear in training data.
$$P(w_n|w_1,\ldots,w_{n-1}) \approx P(w_n|w_{n-2}, w_{n-1})$$
import numpy as np
from collections import defaultdict, Counter
class TrigramModel:
def __init__(self):
self.trigram_counts = defaultdict(Counter)
self.bigram_counts = defaultdict(int)
self.vocab = set()
def train(self, corpus):
"""Train trigram model"""
for sentence in corpus:
words = ['<s>', '<s>'] + sentence.lower().split() + ['</s>']
self.vocab.update(words)
for i in range(2, len(words)):
context = (words[i-2], words[i-1])
self.bigram_counts[context] += 1
self.trigram_counts[context][words[i]] += 1
def probability(self, word, context):
"""P(word|prev2, prev1) using MLE"""
word = word.lower()
context = tuple(w.lower() for w in context)
if self.bigram_counts[context] == 0:
return 0.0
return self.trigram_counts[context][word] / self.bigram_counts[context]
def sentence_probability(self, sentence):
"""Calculate sentence probability using trigram model"""
words = ['<s>', '<s>'] + sentence.lower().split() + ['</s>']
prob = 1.0
for i in range(2, len(words)):
context = (words[i-2], words[i-1])
p = self.probability(words[i], context)
prob *= p
return prob
def predict_next(self, prev2, prev1, top_k=5):
"""Predict next word given context"""
context = (prev2.lower(), prev1.lower())
if context not in self.trigram_counts:
return []
predictions = self.trigram_counts[context].most_common(top_k)
total = self.bigram_counts[context]
return [(word, count/total) for word, count in predictions]
# Larger training corpus
corpus = [
"I want to learn natural language processing",
"I want to learn machine learning",
"I want to eat pizza today",
"She wants to learn programming",
"We want to build language models",
"They want to understand NLP",
"I need to learn more",
"We need to process text"
]
# Train model
trigram = TrigramModel()
trigram.train(corpus)
print("Trigram Predictions after 'I want':")
print("="*50)
predictions = trigram.predict_next('I', 'want', top_k=5)
for word, prob in predictions:
print(f"P({word:15}|I, want) = {prob:.4f}")
print("\nTrigram Predictions after 'want to':")
print("="*50)
predictions = trigram.predict_next('want', 'to', top_k=5)
for word, prob in predictions:
print(f"P({word:15}|want, to) = {prob:.4f}")
print("\nThe Sparsity Problem:")
print("="*50)
test_context = ('want', 'more')
print(f"P(food|want, more) = {trigram.probability('food', test_context):.4f}")
print("Zero probability! This context never appeared in training.")N-gram Trade-offs
| N-gram Order | Context | Pros | Cons |
|---|---|---|---|
| Unigram | None | Dense estimates | No context |
| Bigram | 1 word | Captures local patterns | Limited context |
| Trigram | 2 words | Common in practice | Sparse estimates |
| 4-gram+ | 3+ words | Long dependencies | Very sparse, huge storage |
Smoothing Techniques
The fundamental problem with MLE is that unseen n-grams receive zero probability. Since any sentence containing an unseen n-gram gets zero probability, our model fails on new, grammatically correct sentences. Smoothing techniques redistribute probability mass from seen to unseen events, ensuring no valid sequence gets zero probability.

The Zero Probability Problem
Consider training on "The cat sat" and "The dog ran." With MLE:
- P(cat|The) = 0.5 ?
- P(bird|The) = 0.0 ? (Never seen, but perfectly valid!)
Even a single zero in the chain rule makes the entire sentence probability zero. Smoothing fixes this.
Laplace (Add-One) Smoothing
Laplace smoothing (also called add-one smoothing) is the simplest approach: add 1 to every count, then normalize. This ensures every possible n-gram has at least some probability. While simple, it often transfers too much probability to unseen events.
PLaplace(wn|wn−1) = (Count(wn−1, wn) + 1) / (Count(wn−1) + V)
where V = vocabulary size
import numpy as np
from collections import defaultdict, Counter
class SmoothedBigramModel:
def __init__(self, smoothing='none', k=1.0):
self.bigram_counts = defaultdict(Counter)
self.unigram_counts = Counter()
self.vocab = set()
self.smoothing = smoothing
self.k = k # smoothing parameter
def train(self, corpus):
"""Train model on corpus"""
for sentence in corpus:
words = ['<s>'] + sentence.lower().split() + ['</s>']
self.vocab.update(words)
for i in range(len(words) - 1):
self.unigram_counts[words[i]] += 1
self.bigram_counts[words[i]][words[i+1]] += 1
self.unigram_counts[words[-1]] += 1
def probability(self, word, previous):
"""Calculate probability with chosen smoothing"""
word = word.lower()
previous = previous.lower()
V = len(self.vocab)
count_bigram = self.bigram_counts[previous][word]
count_unigram = self.unigram_counts[previous]
if self.smoothing == 'none':
# MLE - no smoothing
if count_unigram == 0:
return 0.0
return count_bigram / count_unigram
elif self.smoothing == 'laplace':
# Add-one smoothing
return (count_bigram + 1) / (count_unigram + V)
elif self.smoothing == 'add-k':
# Add-k smoothing (k < 1 usually works better)
return (count_bigram + self.k) / (count_unigram + self.k * V)
# Training corpus
corpus = [
"the cat sat on the mat",
"the dog sat on the floor",
"the cat ate the fish",
"the dog ate the bone"
]
# Compare smoothing methods
print("Comparing Smoothing Methods:")
print("="*60)
for smoothing in ['none', 'laplace', 'add-k']:
if smoothing == 'add-k':
model = SmoothedBigramModel(smoothing=smoothing, k=0.1)
else:
model = SmoothedBigramModel(smoothing=smoothing)
model.train(corpus)
print(f"\n{smoothing.upper()} Smoothing:")
print("-" * 40)
# Seen bigram
p_seen = model.probability('cat', 'the')
print(f"P(cat|the) = {p_seen:.4f} [SEEN bigram]")
# Unseen bigram
p_unseen = model.probability('elephant', 'the')
print(f"P(elephant|the) = {p_unseen:.4f} [UNSEEN bigram]")
# Another unseen
p_rare = model.probability('fish', 'sat')
print(f"P(fish|sat) = {p_rare:.4f} [UNSEEN bigram]")Add-k smoothing generalizes Laplace by adding k (where k < 1) instead of 1. This transfers less probability mass to unseen events, often yielding better results:
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict, Counter
# Demonstrate how k affects probability distribution
def compute_probs_for_k(k, count_prev=100, count_bigram=20, vocab_size=1000):
"""Calculate smoothed probability for different k values"""
p_seen = (count_bigram + k) / (count_prev + k * vocab_size)
p_unseen = k / (count_prev + k * vocab_size)
return p_seen, p_unseen
k_values = [0.001, 0.01, 0.1, 0.5, 1.0, 2.0]
print("Effect of k on Probability Distribution:")
print("="*60)
print(f"Context: count(prev) = 100, count(bigram) = 20, V = 1000")
print(f"{'k':>8} | {'P(seen)':>12} | {'P(unseen)':>12} | {'Ratio':>10}")
print("-" * 60)
for k in k_values:
p_seen, p_unseen = compute_probs_for_k(k)
ratio = p_seen / p_unseen if p_unseen > 0 else float('inf')
print(f"{k:>8.3f} | {p_seen:>12.6f} | {p_unseen:>12.6f} | {ratio:>10.1f}")
print("\nNote: Smaller k preserves more distinction between seen/unseen events")Kneser-Ney Smoothing
Kneser-Ney smoothing is considered the gold standard for n-gram smoothing. It uses absolute discounting (subtracting a fixed amount from each count) combined with a clever continuation probability that considers how many different contexts a word appears in, not just raw frequency.
The key insight: a word like "Francisco" has high frequency but always follows "San"—it shouldn't get high probability in other contexts. Kneser-Ney's continuation probability captures this:
P_continuation(w) ? |{v : Count(v, w) > 0}|
Number of unique contexts word w appears in
import numpy as np
from collections import defaultdict, Counter
class KneserNeyBigram:
def __init__(self, discount=0.75):
self.bigram_counts = defaultdict(Counter)
self.unigram_counts = Counter()
self.continuation_counts = Counter() # How many contexts each word follows
self.vocab = set()
self.d = discount
def train(self, corpus):
"""Train with Kneser-Ney smoothing"""
contexts_for_word = defaultdict(set)
for sentence in corpus:
words = ['<s>'] + sentence.lower().split() + ['</s>']
self.vocab.update(words)
for i in range(len(words) - 1):
prev, word = words[i], words[i+1]
self.unigram_counts[prev] += 1
self.bigram_counts[prev][word] += 1
contexts_for_word[word].add(prev)
# Continuation count = number of unique preceding contexts
for word, contexts in contexts_for_word.items():
self.continuation_counts[word] = len(contexts)
self.total_continuations = sum(self.continuation_counts.values())
def probability(self, word, previous):
"""P(word|previous) using Kneser-Ney"""
word = word.lower()
previous = previous.lower()
count_bigram = self.bigram_counts[previous][word]
count_prev = self.unigram_counts[previous]
if count_prev == 0:
# Fallback to continuation probability
return self.continuation_counts[word] / max(1, self.total_continuations)
# Number of unique words following 'previous'
num_following = len(self.bigram_counts[previous])
# Discounted probability + interpolation weight × continuation prob
first_term = max(count_bigram - self.d, 0) / count_prev
lambda_weight = (self.d * num_following) / count_prev
continuation = self.continuation_counts[word] / max(1, self.total_continuations)
return first_term + lambda_weight * continuation
# Corpus with "San Francisco" pattern
corpus = [
"I live in San Francisco",
"San Francisco is beautiful",
"Visit San Francisco today",
"She moved to San Francisco",
"The weather in San Francisco is nice",
"I ate delicious food yesterday",
"The food was delicious",
"Delicious food is everywhere"
]
# Compare regular vs Kneser-Ney
print("Kneser-Ney vs Regular Bigram:")
print("="*60)
# Train both models
from collections import defaultdict, Counter
class SimpleBigram:
def __init__(self):
self.bigram_counts = defaultdict(Counter)
self.unigram_counts = Counter()
def train(self, corpus):
for sentence in corpus:
words = ['<s>'] + sentence.lower().split() + ['</s>']
for i in range(len(words) - 1):
self.unigram_counts[words[i]] += 1
self.bigram_counts[words[i]][words[i+1]] += 1
def probability(self, word, previous):
count = self.unigram_counts[previous.lower()]
if count == 0:
return 0
return self.bigram_counts[previous.lower()][word.lower()] / count
simple = SimpleBigram()
simple.train(corpus)
kn = KneserNeyBigram(discount=0.75)
kn.train(corpus)
print("\nWord 'francisco' appears often but ONLY after 'san':")
print(f" Simple Bigram P(francisco|the) = {simple.probability('francisco', 'the'):.4f}")
print(f" Kneser-Ney P(francisco|the) = {kn.probability('francisco', 'the'):.4f}")
print("\nWord 'delicious' appears in multiple contexts:")
print(f" Simple Bigram P(delicious|the) = {simple.probability('delicious', 'the'):.4f}")
print(f" Kneser-Ney P(delicious|the) = {kn.probability('delicious', 'the'):.4f}")
print("\nContinuation counts:")
print(f" 'francisco' follows {kn.continuation_counts['francisco']} unique context(s)")
print(f" 'delicious' follows {kn.continuation_counts['delicious']} unique context(s)")
print(f" 'food' follows {kn.continuation_counts['food']} unique context(s)")Interpolation & Backoff
Interpolation combines multiple n-gram orders by weighting their probabilities together. This leverages the reliability of lower-order models (which have denser estimates) while capturing the specificity of higher-order models.
$$P_{\text{interp}}(w \mid w_1 w_2) = \lambda_3 P(w|w_1 w_2) + \lambda_2 P(w|w_2) + \lambda_1 P(w), \quad \lambda_1 + \lambda_2 + \lambda_3 = 1$$
import numpy as np
from collections import defaultdict, Counter
class InterpolatedTrigramModel:
def __init__(self, lambda1=0.1, lambda2=0.3, lambda3=0.6):
# Lambdas: unigram, bigram, trigram weights
self.l1, self.l2, self.l3 = lambda1, lambda2, lambda3
self.unigram_counts = Counter()
self.bigram_counts = defaultdict(Counter)
self.trigram_counts = defaultdict(Counter)
self.total_words = 0
self.vocab = set()
def train(self, corpus):
for sentence in corpus:
words = ['<s>', '<s>'] + sentence.lower().split() + ['</s>']
self.vocab.update(words)
self.total_words += len(words)
for i in range(len(words)):
self.unigram_counts[words[i]] += 1
if i >= 1:
self.bigram_counts[words[i-1]][words[i]] += 1
if i >= 2:
context = (words[i-2], words[i-1])
self.trigram_counts[context][words[i]] += 1
def probability(self, word, prev1=None, prev2=None):
"""Interpolated probability combining uni/bi/trigram"""
word = word.lower()
# Unigram: P(w)
p_uni = self.unigram_counts[word] / max(1, self.total_words)
# Bigram: P(w|prev1)
p_bi = 0.0
if prev1:
prev1 = prev1.lower()
count_prev = sum(self.bigram_counts[prev1].values())
if count_prev > 0:
p_bi = self.bigram_counts[prev1][word] / count_prev
# Trigram: P(w|prev2, prev1)
p_tri = 0.0
if prev1 and prev2:
prev2 = prev2.lower()
context = (prev2, prev1)
count_context = sum(self.trigram_counts[context].values())
if count_context > 0:
p_tri = self.trigram_counts[context][word] / count_context
# Interpolate
return self.l1 * p_uni + self.l2 * p_bi + self.l3 * p_tri
# Training corpus
corpus = [
"I want to eat Chinese food",
"I want to eat Italian food",
"I want to learn language models",
"She wants to eat pizza",
"They want to visit Paris",
"We want to eat dinner",
"I like Chinese food",
"Italian food is delicious"
]
# Train interpolated model
model = InterpolatedTrigramModel(lambda1=0.1, lambda2=0.3, lambda3=0.6)
model.train(corpus)
print("Interpolated Trigram Model:")
print("="*60)
print(f"Weights: ?_unigram={model.l1}, ?_bigram={model.l2}, ?_trigram={model.l3}")
print("\nPredicting word after 'want to':")
print("-" * 40)
candidates = ['eat', 'learn', 'visit', 'sleep', 'run']
for word in candidates:
p = model.probability(word, prev1='to', prev2='want')
print(f"P({word:8}|want to) = {p:.4f}")
print("\nPredicting word after 'to eat':")
print("-" * 40)
candidates = ['chinese', 'italian', 'pizza', 'breakfast', 'xyz']
for word in candidates:
p = model.probability(word, prev1='eat', prev2='to')
print(f"P({word:10}|to eat) = {p:.4f}")Backoff is an alternative approach that uses higher-order n-grams when available, "backing off" to lower-order models only when the higher-order count is zero. Unlike interpolation which always combines all orders, backoff is more selective:
import numpy as np
from collections import defaultdict, Counter
class StupidBackoffModel:
"""Simple backoff model (Stupid Backoff from Google)"""
def __init__(self, backoff_weight=0.4):
self.alpha = backoff_weight
self.unigram_counts = Counter()
self.bigram_counts = defaultdict(Counter)
self.trigram_counts = defaultdict(Counter)
self.total_words = 0
def train(self, corpus):
for sentence in corpus:
words = ['<s>', '<s>'] + sentence.lower().split() + ['</s>']
self.total_words += len(words)
for i in range(len(words)):
self.unigram_counts[words[i]] += 1
if i >= 1:
self.bigram_counts[words[i-1]][words[i]] += 1
if i >= 2:
context = (words[i-2], words[i-1])
self.trigram_counts[context][words[i]] += 1
def score(self, word, prev1=None, prev2=None):
"""Stupid backoff scoring (not true probability)"""
word = word.lower()
# Try trigram first
if prev1 and prev2:
context = (prev2.lower(), prev1.lower())
if self.trigram_counts[context][word] > 0:
count_context = sum(self.trigram_counts[context].values())
return self.trigram_counts[context][word] / count_context, 'trigram'
# Backoff to bigram
if prev1:
prev1 = prev1.lower()
if self.bigram_counts[prev1][word] > 0:
count_prev = sum(self.bigram_counts[prev1].values())
return self.alpha * self.bigram_counts[prev1][word] / count_prev, 'bigram'
# Backoff to unigram
return self.alpha * self.alpha * self.unigram_counts[word] / self.total_words, 'unigram'
# Training corpus
corpus = [
"I want to eat Chinese food",
"I want to eat Italian food",
"She wants to visit Paris",
"They want to learn programming",
"The food is delicious"
]
model = StupidBackoffModel(backoff_weight=0.4)
model.train(corpus)
print("Stupid Backoff Model:")
print("="*60)
print(f"Backoff weight a = {model.alpha}")
test_cases = [
('chinese', 'eat', 'to'), # Seen trigram
('pizza', 'eat', 'to'), # Backoff to bigram
('programming', 'want', 'i'), # Seen trigram
('xyz', 'foo', 'bar'), # Backoff to unigram
]
print("\nScoring different contexts:")
print("-" * 60)
for word, prev1, prev2 in test_cases:
score, level = model.score(word, prev1, prev2)
print(f"S({word:12}|{prev2} {prev1}) = {score:.6f} [used {level}]")Interpolation vs Backoff
Interpolation always combines all n-gram orders—useful when all provide signal. Backoff uses the best available estimate—more efficient and sometimes more accurate. Modern systems often use Modified Kneser-Ney with interpolation, combining the best of both approaches.
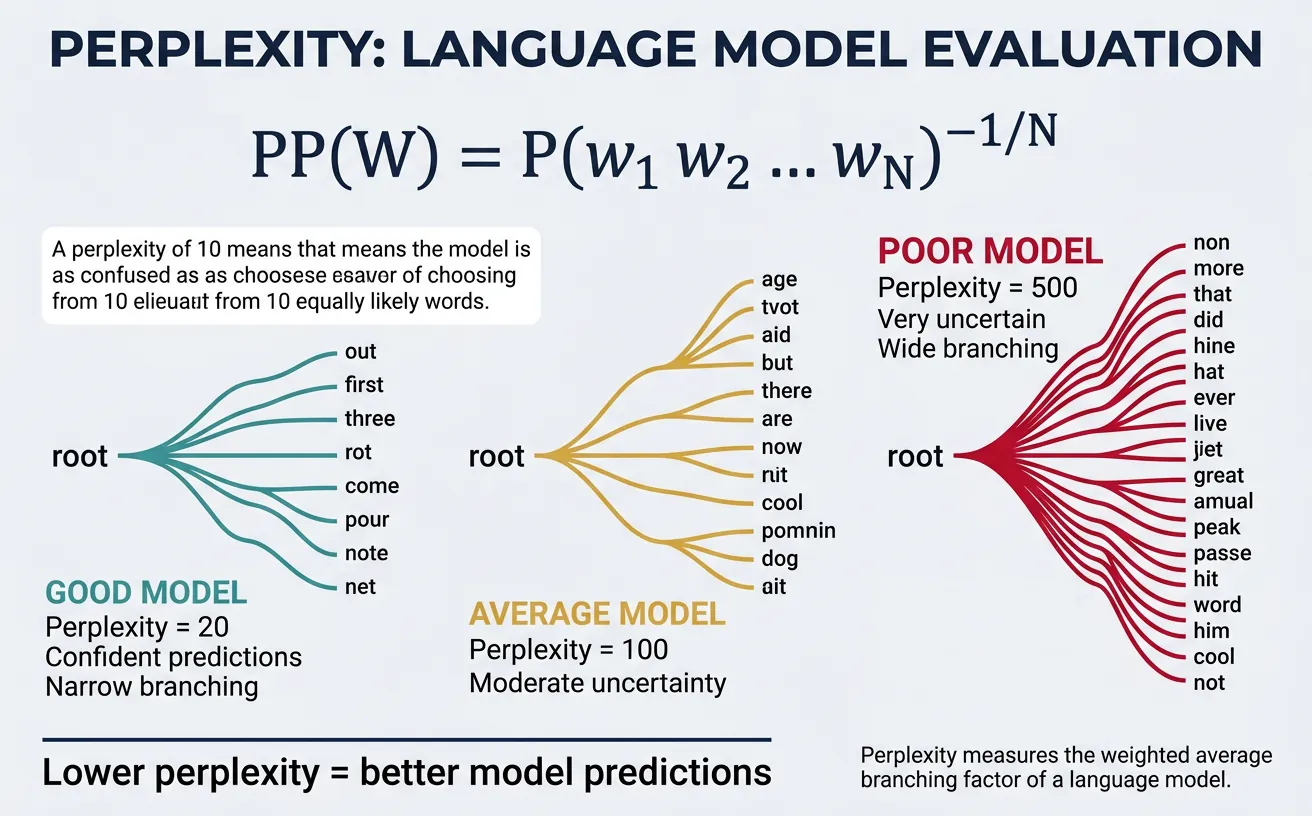
Perplexity & Evaluation
Perplexity is the standard metric for evaluating language models. Intuitively, it measures how "surprised" the model is by the test data—lower perplexity means the model predicts the test data better. Mathematically, perplexity is the inverse probability of the test set, normalized by the number of words:
$$PP(W) = P(w_1, w_2, \ldots, w_n)^{-1/n} = \prod_{i=1}^{n} P(w_i|w_1,\ldots,w_{i-1})^{-1/n}$$
Equivalently, perplexity equals 2 raised to the cross-entropy:
$$PP(W) = 2^{H(W)} = 2^{-\frac{1}{n} \sum_{i=1}^{n} \log_2 P(w_i|\text{context})}$$
Interpreting Perplexity
Perplexity can be interpreted as the weighted average branching factor—the effective number of equally likely words that could follow at each position. A perplexity of 100 means the model is as uncertain as if choosing uniformly among 100 words at each step.
- Lower is better: PP = 50 beats PP = 200
- Baseline: Random uniform over V words gives PP = V
- State-of-art: Neural LMs achieve PP < 20 on benchmarks
import numpy as np
from collections import defaultdict, Counter
import math
class PerplexityEvaluator:
def __init__(self):
self.bigram_counts = defaultdict(Counter)
self.unigram_counts = Counter()
self.vocab = set()
self.vocab_size = 0
def train(self, corpus):
"""Train bigram model with add-k smoothing"""
for sentence in corpus:
words = ['<s>'] + sentence.lower().split() + ['</s>']
self.vocab.update(words)
for i in range(len(words) - 1):
self.unigram_counts[words[i]] += 1
self.bigram_counts[words[i]][words[i+1]] += 1
self.vocab_size = len(self.vocab)
def probability(self, word, previous, k=0.01):
"""Add-k smoothed bigram probability"""
count_bigram = self.bigram_counts[previous][word]
count_unigram = self.unigram_counts[previous]
return (count_bigram + k) / (count_unigram + k * self.vocab_size)
def sentence_log_prob(self, sentence, k=0.01):
"""Calculate log probability of sentence"""
words = ['<s>'] + sentence.lower().split() + ['</s>']
log_prob = 0.0
for i in range(1, len(words)):
p = self.probability(words[i], words[i-1], k)
log_prob += math.log2(p)
return log_prob, len(words) - 1 # -1 for <s>
def perplexity(self, test_corpus, k=0.01):
"""Calculate perplexity on test corpus"""
total_log_prob = 0.0
total_words = 0
for sentence in test_corpus:
log_prob, num_words = self.sentence_log_prob(sentence, k)
total_log_prob += log_prob
total_words += num_words
# Perplexity = 2^(-average log prob)
avg_log_prob = total_log_prob / total_words
perplexity = 2 ** (-avg_log_prob)
return perplexity, total_words
# Training corpus
train_corpus = [
"the cat sat on the mat",
"the dog sat on the floor",
"the cat ate the fish",
"the dog ate the bone",
"the bird sat on the tree",
"the cat chased the mouse",
"the dog chased the cat"
]
# Test corpus
test_corpus = [
"the cat sat on the floor",
"the dog ate the fish",
"the bird ate the worm"
]
# Train and evaluate
evaluator = PerplexityEvaluator()
evaluator.train(train_corpus)
print("Perplexity Evaluation:")
print("="*60)
print(f"Vocabulary size: {evaluator.vocab_size}")
print(f"Training sentences: {len(train_corpus)}")
print(f"Test sentences: {len(test_corpus)}")
# Calculate perplexity for different smoothing values
print("\nPerplexity with different smoothing:")
print("-" * 40)
for k in [0.001, 0.01, 0.1, 0.5, 1.0]:
pp, num_words = evaluator.perplexity(test_corpus, k=k)
print(f"k = {k:5.3f}: Perplexity = {pp:8.2f} ({num_words} words)")
# Show per-sentence perplexity
print("\nPer-sentence analysis (k=0.01):")
print("-" * 60)
for sentence in test_corpus:
log_prob, n = evaluator.sentence_log_prob(sentence, k=0.01)
pp = 2 ** (-log_prob / n)
print(f"'{sentence}'")
print(f" Log prob: {log_prob:.2f}, Words: {n}, Perplexity: {pp:.2f}\n")Comparing N-gram Orders by Perplexity
Higher-order n-grams typically achieve lower perplexity on sufficient data:
| Model | Perplexity (Penn Treebank) | Parameters |
|---|---|---|
| Unigram | ~1000 | ~50K |
| Bigram | ~150 | ~2M |
| Trigram | ~80 | ~20M |
| KN-smoothed Trigram | ~60 | ~20M |
| Neural LM (LSTM) | ~40 | ~20M |
| GPT-2 (1.5B) | ~18 | 1.5B |
import numpy as np
import math
from collections import defaultdict, Counter
def cross_entropy_to_perplexity(cross_entropy):
"""Convert cross-entropy (in bits) to perplexity"""
return 2 ** cross_entropy
def perplexity_to_cross_entropy(perplexity):
"""Convert perplexity to cross-entropy"""
return math.log2(perplexity)
# Demonstration
print("Cross-Entropy and Perplexity Relationship:")
print("="*50)
print(f"{'Cross-Entropy (bits)':>20} | {'Perplexity':>15}")
print("-" * 50)
for ce in [2, 4, 6, 8, 10]:
pp = cross_entropy_to_perplexity(ce)
print(f"{ce:>20} | {pp:>15.0f}")
print("\n" + "="*50)
print(f"{'Perplexity':>20} | {'Cross-Entropy (bits)':>20}")
print("-" * 50)
for pp in [10, 50, 100, 500, 1000]:
ce = perplexity_to_cross_entropy(pp)
print(f"{pp:>20} | {ce:>20.2f}")
# What perplexity means in practice
print("\n" + "="*50)
print("What Perplexity Means Intuitively:")
print("-" * 50)
print("PP = 10: Like choosing from 10 equally likely words")
print("PP = 100: Like choosing from 100 equally likely words")
print("PP = V: Random guessing (uniform distribution)")
print("PP = 1: Perfect prediction (impossible in practice)")Applications
Statistical language models power numerous NLP applications. While neural models have largely superseded n-grams for complex tasks, understanding these applications provides foundation for modern techniques. Let's explore key applications: text generation, spelling correction, speech recognition, and machine translation decoding.
Text Generation with N-grams
N-gram models can generate text by sampling words according to their conditional probabilities. Starting from a seed, we repeatedly sample the next word given the context. The quality depends on n-gram order and corpus—higher orders produce more coherent but less diverse text.
import numpy as np
from collections import defaultdict, Counter
import random
class TextGenerator:
def __init__(self, n=3):
self.n = n # n-gram order
self.ngram_counts = defaultdict(Counter)
self.context_totals = defaultdict(int)
def train(self, corpus):
"""Train n-gram model for generation"""
for sentence in corpus:
# Add start tokens
tokens = ['<s>'] * (self.n - 1) + sentence.lower().split() + ['</s>']
for i in range(self.n - 1, len(tokens)):
context = tuple(tokens[i - self.n + 1:i])
word = tokens[i]
self.ngram_counts[context][word] += 1
self.context_totals[context] += 1
def generate(self, max_words=20, temperature=1.0):
"""Generate text using the trained model"""
# Start with beginning tokens
context = tuple(['<s>'] * (self.n - 1))
generated = []
for _ in range(max_words):
if context not in self.ngram_counts:
break
# Get probability distribution
candidates = self.ngram_counts[context]
words = list(candidates.keys())
counts = np.array(list(candidates.values()), dtype=float)
# Apply temperature
if temperature != 1.0:
counts = counts ** (1.0 / temperature)
probs = counts / counts.sum()
# Sample next word
next_word = random.choices(words, weights=probs)[0]
if next_word == '</s>':
break
generated.append(next_word)
# Update context
context = tuple(list(context)[1:] + [next_word])
return ' '.join(generated)
# Training corpus
corpus = [
"I love to learn about natural language processing",
"Natural language processing is a fascinating field",
"I love to study machine learning algorithms",
"Machine learning algorithms are powerful tools",
"I want to build intelligent systems",
"Intelligent systems can understand language",
"Language is the foundation of communication",
"Communication is essential for collaboration",
"I love to read books about artificial intelligence",
"Artificial intelligence will transform the world"
]
# Train and generate with different n-gram orders
print("Text Generation with N-gram Models:")
print("="*60)
for n in [2, 3, 4]:
print(f"\n{n}-gram Model:")
print("-" * 40)
gen = TextGenerator(n=n)
gen.train(corpus)
# Generate multiple samples
for i in range(3):
text = gen.generate(max_words=15, temperature=0.8)
print(f" Sample {i+1}: {text}")Temperature in Text Generation
Temperature controls randomness in generation:
- T = 1.0: Sample from true probability distribution
- T < 1.0: Sharper distribution, more deterministic (favors high-probability words)
- T > 1.0: Flatter distribution, more random/creative
- T ? 0: Greedy decoding (always pick most likely word)
import numpy as np
from collections import defaultdict, Counter
import random
# Demonstrate temperature effects
def apply_temperature(probs, temperature):
"""Apply temperature to probability distribution"""
probs = np.array(probs, dtype=float)
# Raise to power of 1/T, then normalize
adjusted = probs ** (1.0 / temperature)
return adjusted / adjusted.sum()
# Original distribution
original_probs = np.array([0.5, 0.3, 0.15, 0.05])
words = ['the', 'a', 'some', 'xyz']
print("Temperature Effect on Word Selection:")
print("="*60)
print(f"Words: {words}")
print(f"Original probs: {original_probs}")
print()
for temp in [0.5, 1.0, 1.5, 2.0]:
adjusted = apply_temperature(original_probs, temp)
print(f"T = {temp}: {adjusted.round(3)}")
print(f" Most likely: {words[adjusted.argmax()]} ({adjusted.max():.1%})")
print("\n" + "="*60)
print("Observation:")
print("- Lower T: Probabilities become more peaked")
print("- Higher T: Probabilities become more uniform")
print("- T=1: Original distribution preserved")Spelling Correction
Language models enable context-sensitive spelling correction. Given a potentially misspelled word, we generate candidates and rank them using P(correction) × P(context|correction). The Noisy Channel Model formalizes this:
$$P(\text{correct}|\text{observed}) \propto P(\text{observed}|\text{correct}) \times P(\text{correct})$$
Error Model × Language Model
import numpy as np
from collections import Counter
import re
class SpellingCorrector:
def __init__(self):
self.word_counts = Counter()
self.total_words = 0
def train(self, text):
"""Train language model from text"""
words = re.findall(r'\w+', text.lower())
self.word_counts.update(words)
self.total_words = sum(self.word_counts.values())
def P(self, word):
"""Unigram probability P(word)"""
return self.word_counts[word] / self.total_words
def edits1(self, word):
"""Generate all strings 1 edit away"""
letters = 'abcdefghijklmnopqrstuvwxyz'
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)]
deletes = [L + R[1:] for L, R in splits if R]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R) > 1]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters]
inserts = [L + c + R for L, R in splits for c in letters]
return set(deletes + transposes + replaces + inserts)
def edits2(self, word):
"""Generate all strings 2 edits away"""
return set(e2 for e1 in self.edits1(word) for e2 in self.edits1(e1))
def candidates(self, word):
"""Generate correction candidates"""
return (
self.known([word]) or # If word is known, return it
self.known(self.edits1(word)) or # Known words 1 edit away
self.known(self.edits2(word)) or # Known words 2 edits away
[word] # Return original if nothing found
)
def known(self, words):
"""Return words that exist in vocabulary"""
return set(w for w in words if w in self.word_counts)
def correct(self, word):
"""Return most probable correction"""
return max(self.candidates(word), key=self.P)
def correct_with_scores(self, word, top_k=5):
"""Return top k corrections with probabilities"""
cands = self.candidates(word)
scored = [(c, self.P(c)) for c in cands]
scored.sort(key=lambda x: -x[1])
return scored[:top_k]
# Training text
training_text = """
The quick brown fox jumps over the lazy dog.
Natural language processing is a field of artificial intelligence.
Machine learning algorithms learn patterns from data.
The weather today is beautiful and sunny.
I love to learn about programming and technology.
The cat sat on the mat near the window.
Programming languages include Python Java and JavaScript.
Data science combines statistics and computer science.
"""
# Train corrector
corrector = SpellingCorrector()
corrector.train(training_text * 10) # Repeat for more counts
print("Spelling Correction with Language Model:")
print("="*60)
# Test corrections
misspellings = [
('teh', 'the'),
('langauge', 'language'),
('computr', 'computer'),
('learnng', 'learning'),
('machne', 'machine'),
('progrm', 'program')
]
for misspelled, expected in misspellings:
correction = corrector.correct(misspelled)
status = '?' if correction == expected else '?'
print(f"'{misspelled}' ? '{correction}' (expected: '{expected}') {status}")
print("\nTop candidates for 'teh':")
print("-" * 40)
for word, prob in corrector.correct_with_scores('teh'):
print(f" {word:15} P = {prob:.6f}")Speech Recognition Decoding
In automatic speech recognition (ASR), the language model combines with the acoustic model to find the most likely transcription. Given acoustic features A, we seek:
$$W^* = \arg\max_W P(W|A) = \arg\max_W P(A|W) \times P(W)$$
Acoustic Model × Language Model
import numpy as np
from collections import defaultdict, Counter
# Simulated speech recognition scoring
class SimpleSpeechDecoder:
"""Simplified demonstration of LM in speech recognition"""
def __init__(self):
self.bigram_counts = defaultdict(Counter)
self.unigram_counts = Counter()
def train(self, corpus):
for sentence in corpus:
words = ['<s>'] + sentence.lower().split() + ['</s>']
for i in range(len(words) - 1):
self.unigram_counts[words[i]] += 1
self.bigram_counts[words[i]][words[i+1]] += 1
def lm_score(self, sentence):
"""Log probability from language model"""
words = ['<s>'] + sentence.lower().split() + ['</s>']
score = 0.0
for i in range(1, len(words)):
count_bi = self.bigram_counts[words[i-1]][words[i]] + 0.1
count_uni = self.unigram_counts[words[i-1]] + 10
score += np.log(count_bi / count_uni)
return score
def decode(self, acoustic_hypotheses, lm_weight=0.5):
"""
Re-rank ASR hypotheses using LM
acoustic_hypotheses: list of (text, acoustic_score) tuples
"""
results = []
for text, acoustic in acoustic_hypotheses:
lm = self.lm_score(text)
combined = (1 - lm_weight) * acoustic + lm_weight * lm
results.append((text, acoustic, lm, combined))
results.sort(key=lambda x: -x[3]) # Sort by combined score
return results
# Training corpus for LM
corpus = [
"I want to recognize speech",
"I want to wreck a nice beach", # Famous ASR joke!
"speech recognition is difficult",
"recognize speech accurately",
"the speech was excellent"
]
decoder = SimpleSpeechDecoder()
decoder.train(corpus)
print("Speech Recognition with Language Model:")
print("="*60)
# Simulated ASR output (ambiguous acoustically)
acoustic_hypotheses = [
("I want to recognize speech", -5.0),
("I want to wreck a nice beach", -4.8), # Slightly better acoustic
("I wand to recognize speach", -5.2),
]
print("\nHypotheses and Scores:")
print("-" * 60)
print(f"{'Text':^35} | {'Acoustic':^10} | {'LM':^10} | {'Combined':^10}")
print("-" * 60)
results = decoder.decode(acoustic_hypotheses, lm_weight=0.5)
for text, acoustic, lm, combined in results:
print(f"{text:35} | {acoustic:10.2f} | {lm:10.2f} | {combined:10.2f}")
print("\nWinner:", results[0][0])
print("\nNote: LM helps distinguish acoustically similar phrases!")N-gram Models in Modern Systems
While neural models dominate, n-grams remain useful:
- Keyboard Autocomplete: N-grams power fast, on-device text prediction
- Spam Filtering: Character n-grams detect obfuscated spam
- ASR Rescoring: N-gram LMs refine neural ASR output
- Language Identification: Character n-gram profiles identify languages
- Cache/Hybrid Models: N-grams adapt to recent context in neural systems
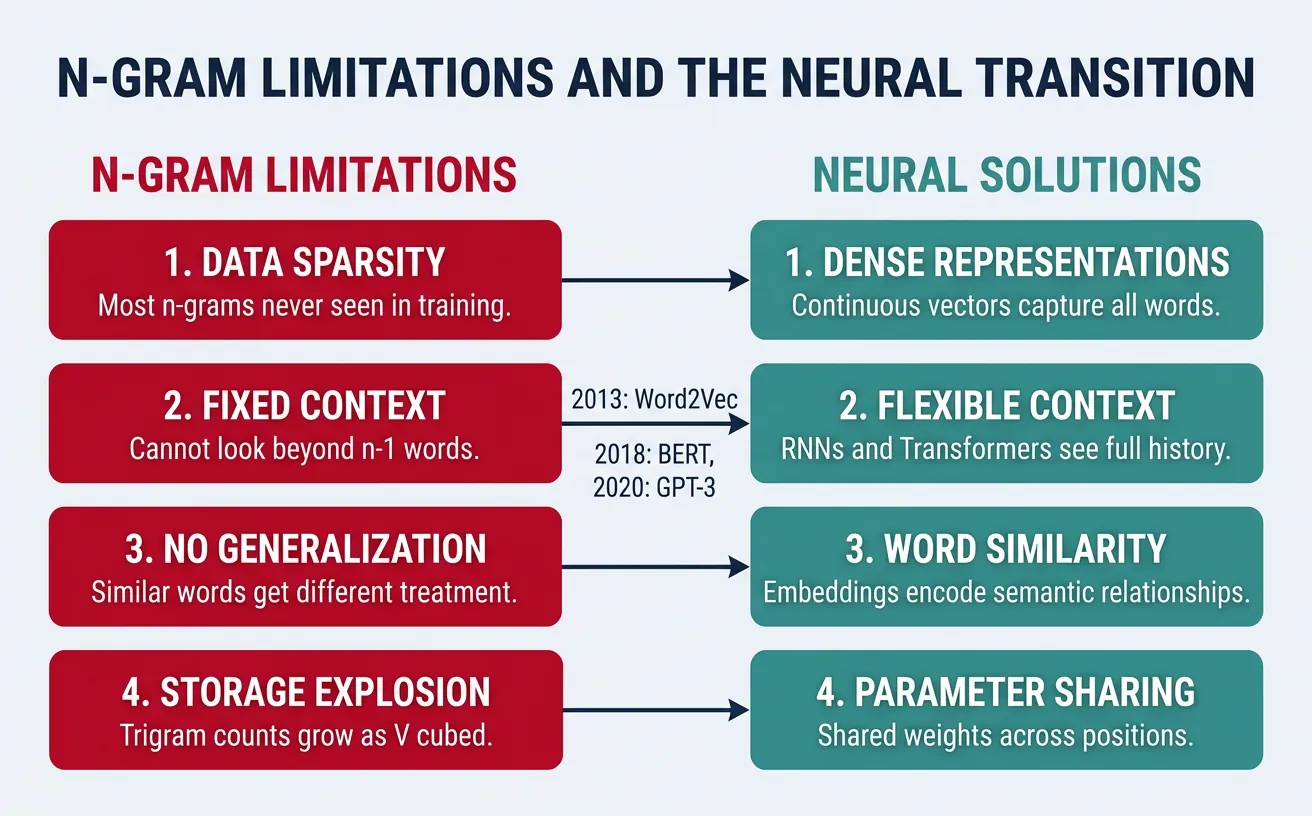
Limitations & Transition to Neural
While n-gram models provide an elegant foundation for language modeling, they suffer from fundamental limitations that motivated the development of neural language models. Understanding these limitations explains why modern NLP has shifted to neural approaches.
The Sparsity Problem
The most severe limitation is data sparsity. The number of possible n-grams grows exponentially with n and vocabulary size (V^n). Even with billions of words of training data, most valid n-grams never appear. Smoothing helps but cannot solve the fundamental problem:
import numpy as np
def calculate_possible_ngrams(vocab_size, n):
"""Calculate number of possible n-grams"""
return vocab_size ** n
def estimate_coverage(vocab_size, n, corpus_size):
"""Estimate fraction of possible n-grams seen in corpus"""
possible = vocab_size ** n
# Rough estimate: unique n-grams ~ corpus_size for large corpora
estimated_seen = min(corpus_size * 0.7, possible) # Diminishing returns
return estimated_seen / possible
vocab_size = 50000 # Typical vocabulary
corpus_size = 1e9 # 1 billion words
print("N-gram Sparsity Analysis:")
print("="*60)
print(f"Vocabulary size: {vocab_size:,}")
print(f"Corpus size: {corpus_size/1e9:.1f} billion words")
print()
print(f"{'N':>5} | {'Possible N-grams':>20} | {'Coverage':>15}")
print("-" * 60)
for n in range(1, 6):
possible = calculate_possible_ngrams(vocab_size, n)
coverage = estimate_coverage(vocab_size, n, corpus_size)
if possible > 1e15:
possible_str = f"{possible:.2e}"
else:
possible_str = f"{possible:,.0f}"
print(f"{n:>5} | {possible_str:>20} | {coverage:>14.8%}")
print("\nKey insight: Coverage drops exponentially with n!")
print("Even 1 billion words see <1% of possible trigrams.")Limited Context Window
N-gram models have a fixed, short context window. They cannot capture dependencies that span more than n-1 words. Consider: "The author who wrote the book that influenced the movement that changed history was..." — predicting "was" requires understanding the distant subject "author," impossible for any reasonable n-gram order.
import numpy as np
# Demonstrate long-range dependency problem
sentences = [
# Subject-verb agreement across distance
("The cat that sat on the mat was happy", "was"),
("The cats that sat on the mat were happy", "were"),
# Context needed from far away
("The researcher who published the paper in the prestigious journal received an award", "received"),
]
print("Long-Range Dependency Problem:")
print("="*60)
for sentence, target in sentences:
words = sentence.split()
target_idx = words.index(target)
print(f"\nSentence: '{sentence}'")
print(f"Target word: '{target}' at position {target_idx}")
print(f"")
for n in [2, 3, 4, 5]:
context_start = max(0, target_idx - n + 1)
context = words[context_start:target_idx]
print(f" {n}-gram context: '{' '.join(context)}' ? {target}")
# Show what context would be needed
subject = words[0:2] # "The cat" or "The cats"
print(f" Actual needed context: '{' '.join(subject)}' (distance: {target_idx})")
print("\n" + "="*60)
print("N-grams cannot capture agreement when subject is far from verb!")No Generalization Across Similar Words
N-gram models treat each word as an atomic symbol with no similarity to other words. Seeing "dog chased cat" tells the model nothing about "puppy chased kitten"—these are completely unrelated n-grams. Neural models with word embeddings share statistical strength across similar words:
import numpy as np
from collections import defaultdict, Counter
# Demonstrate lack of generalization
class NgramModel:
def __init__(self):
self.bigram_counts = defaultdict(Counter)
self.unigram_counts = Counter()
def train(self, corpus):
for sentence in corpus:
words = sentence.lower().split()
for i in range(len(words) - 1):
self.unigram_counts[words[i]] += 1
self.bigram_counts[words[i]][words[i+1]] += 1
def probability(self, word, previous):
count = self.unigram_counts[previous.lower()]
if count == 0:
return 0.0
return self.bigram_counts[previous.lower()][word.lower()] / count
# Training: only see "dog" and "cat" examples
corpus = [
"the dog chased the cat",
"a dog barked loudly",
"the cat meowed softly",
"my dog is friendly"
]
model = NgramModel()
model.train(corpus)
print("N-gram Generalization Problem:")
print("="*60)
# Words we've seen
print("\nWords we trained on:")
print(" 'dog chased' ? seen")
print(" 'cat meowed' ? seen")
print("\nTrying to predict similar but unseen patterns:")
print("-" * 50)
test_cases = [
('chased', 'dog'), # Seen
('chased', 'puppy'), # Similar but unseen
('chased', 'hound'), # Similar but unseen
('meowed', 'cat'), # Seen
('meowed', 'kitten'), # Similar but unseen
]
for word, prev in test_cases:
prob = model.probability(word, prev)
status = "? seen" if prob > 0 else "? unseen (0 probability!)"
print(f"P({word}|{prev:8}) = {prob:.4f} {status}")
print("\n" + "="*60)
print("N-grams can't generalize: 'puppy' ? 'dog' in this model.")
print("Neural models share weights across similar words via embeddings.")Why Neural Language Models?
Neural language models address all these limitations:
- Dense Representations: Words become vectors, enabling smooth probability estimates
- Generalization: Similar words have similar vectors, share statistical strength
- Long Context: RNNs/Transformers capture dependencies across hundreds/thousands of tokens
- Compositional: Learn to compose meaning from parts, not memorize n-grams
Storage and Computational Costs
Storing n-gram counts requires massive memory for large vocabularies and corpora. Google's n-gram corpus (released 2006) contains 1 trillion tokens but requires careful pruning to be usable. Neural models can be more parameter-efficient while capturing richer patterns:
import numpy as np
def estimate_ngram_storage(vocab_size, max_n, avg_count_bytes=4):
"""Estimate storage for n-gram model"""
total_bytes = 0
print(f"N-gram Storage Estimation (V={vocab_size:,}):")
print("="*50)
for n in range(1, max_n + 1):
# Theoretical maximum (sparse in practice)
max_entries = vocab_size ** n
# Realistic: assume 1% coverage for bigrams, decreasing
coverage = 0.01 * (0.1 ** (n - 2)) if n > 1 else 1.0
estimated_entries = int(max_entries * min(coverage, 1.0))
estimated_entries = min(estimated_entries, 1e10) # Cap at 10B
# Storage: (n words × 4 bytes each) + count (4 bytes)
bytes_per_entry = n * avg_count_bytes + avg_count_bytes
storage = estimated_entries * bytes_per_entry
print(f" {n}-gram: ~{estimated_entries:,.0f} entries = {storage/1e9:.2f} GB")
total_bytes += storage
return total_bytes
print("Small Vocabulary (V=10,000):")
small = estimate_ngram_storage(10000, 4)
print(f" Total: {small/1e9:.2f} GB\n")
print("Large Vocabulary (V=100,000):")
large = estimate_ngram_storage(100000, 4)
print(f" Total: {large/1e9:.2f} GB\n")
print("Comparison with Neural Models:")
print("="*50)
print(" GPT-2 Small (117M params): ~0.5 GB")
print(" GPT-2 Large (774M params): ~3.0 GB")
print(" BERT Base (110M params): ~0.4 GB")
print("\nNeural models pack more knowledge into fewer bytes!")N-grams vs Neural: When to Use Each
| Use N-grams When... | Use Neural When... |
|---|---|
| Interpretability is critical | Best quality is required |
| Low latency needed (mobile) | Long context matters |
| Limited compute resources | Generalization is important |
| Domain-specific, small vocab | Large, diverse vocabulary |
| Baseline/hybrid systems | State-of-the-art performance |
Conclusion & Next Steps
Statistical language models and n-grams represent a foundational pillar of NLP that, despite their limitations, continue to inform modern approaches. We've explored how these models assign probabilities to word sequences, the trade-offs between different n-gram orders, and the critical role of smoothing techniques in handling unseen data.
Key Takeaways
- Language Models: Assign P(sequence) using the chain rule of probability
- Markov Assumption: Approximate full history with fixed n-1 word context
- MLE: Count-based estimation, simple but assigns zero to unseen events
- Smoothing: Essential for handling sparsity (Laplace, Add-k, Kneser-Ney)
- Interpolation/Backoff: Combine n-gram orders for robustness
- Perplexity: Standard evaluation metric (lower = better)
- Limitations: Sparsity, fixed context, no similarity generalization
The concepts learned here—probability estimation, smoothing, evaluation metrics, and the tension between model capacity and data requirements—carry forward to neural language models. Understanding why n-grams struggle provides intuition for why architectures like RNNs and Transformers were developed.
# Summary: Complete N-gram Pipeline
import numpy as np
from collections import defaultdict, Counter
import math
class CompleteNgramModel:
"""Production-ready n-gram model with all techniques"""
def __init__(self, n=3, smoothing='kneser-ney', discount=0.75):
self.n = n
self.smoothing = smoothing
self.discount = discount
# Storage for counts
self.ngram_counts = [defaultdict(Counter) for _ in range(n)]
self.context_totals = [defaultdict(int) for _ in range(n)]
self.continuation_counts = Counter()
self.vocab = set()
def train(self, corpus):
"""Train on corpus with proper tokenization"""
continuation_contexts = defaultdict(set)
for sentence in corpus:
tokens = ['<s>'] * (self.n - 1) + sentence.lower().split() + ['</s>']
self.vocab.update(tokens)
for i in range(len(tokens)):
# Count n-grams of all orders
for order in range(1, min(i + 2, self.n + 1)):
context = tuple(tokens[i - order + 1:i])
word = tokens[i]
self.ngram_counts[order - 1][context][word] += 1
self.context_totals[order - 1][context] += 1
if order == 2: # Track continuation counts for Kneser-Ney
continuation_contexts[word].add(context)
for word, contexts in continuation_contexts.items():
self.continuation_counts[word] = len(contexts)
self.total_continuations = sum(self.continuation_counts.values())
print(f"Trained {self.n}-gram model on {len(corpus)} sentences")
print(f"Vocabulary size: {len(self.vocab)}")
def probability(self, word, context):
"""Calculate smoothed probability"""
word = word.lower()
context = tuple(w.lower() for w in context)
if self.smoothing == 'kneser-ney':
return self._kneser_ney_prob(word, context)
else:
return self._additive_prob(word, context)
def _kneser_ney_prob(self, word, context):
"""Interpolated Kneser-Ney probability"""
if len(context) == 0:
# Base case: continuation probability
return self.continuation_counts[word] / max(1, self.total_continuations)
order = len(context)
count = self.ngram_counts[order][context][word]
total = self.context_totals[order][context]
if total == 0:
return self._kneser_ney_prob(word, context[1:])
# Discounted probability + interpolation weight × lower-order
num_types = len(self.ngram_counts[order][context])
lambda_weight = self.discount * num_types / total
first_term = max(count - self.discount, 0) / total
lower_order = self._kneser_ney_prob(word, context[1:])
return first_term + lambda_weight * lower_order
def _additive_prob(self, word, context, k=0.01):
"""Add-k smoothed probability"""
order = len(context)
count = self.ngram_counts[order][context][word]
total = self.context_totals[order][context]
V = len(self.vocab)
return (count + k) / (total + k * V)
def perplexity(self, test_corpus):
"""Calculate perplexity on test set"""
total_log_prob = 0
total_words = 0
for sentence in test_corpus:
tokens = ['<s>'] * (self.n - 1) + sentence.lower().split() + ['</s>']
for i in range(self.n - 1, len(tokens)):
context = tuple(tokens[i - self.n + 1:i])
word = tokens[i]
p = self.probability(word, context)
total_log_prob += math.log2(max(p, 1e-10))
total_words += 1
return 2 ** (-total_log_prob / total_words)
# Quick demonstration
corpus = [
"I love natural language processing",
"Language models are fascinating",
"I want to learn more about NLP",
"Statistical models provide foundations"
]
model = CompleteNgramModel(n=3, smoothing='kneser-ney')
model.train(corpus)
test = ["I love language models"]
pp = model.perplexity(test)
print(f"Test perplexity: {pp:.2f}")What's Next: Neural Language Models
In the next part of our series, we'll explore how neural networks overcome n-gram limitations. You'll learn how word embeddings enable generalization, how RNNs/LSTMs capture long-range dependencies, and how attention mechanisms (leading to Transformers) revolutionized language modeling.
Your Learning Path
- Implement from scratch: Build your own n-gram model with smoothing
- Experiment with NLTK: Use `nltk.lm` for production n-gram models
- Compare orders: Train 2/3/4-gram models, compare perplexity
- Build an application: Create a simple autocomplete or text generator
- Move to neural: Continue to Part 6 for neural language models
Statistical language models may seem simple compared to modern transformers, but they embody timeless principles: probabilistic modeling, handling uncertainty, trading off bias and variance, and the fundamental goal of predicting human language. These foundations will serve you well as you advance through the rest of this NLP series.