System Design Series Part 8: CAP Theorem & Consistency
January 25, 2026Wasil Zafar35 min read
Master distributed systems fundamentals with CAP theorem and consistency models. Understand the trade-offs between consistency, availability, and partition tolerance in real-world systems.
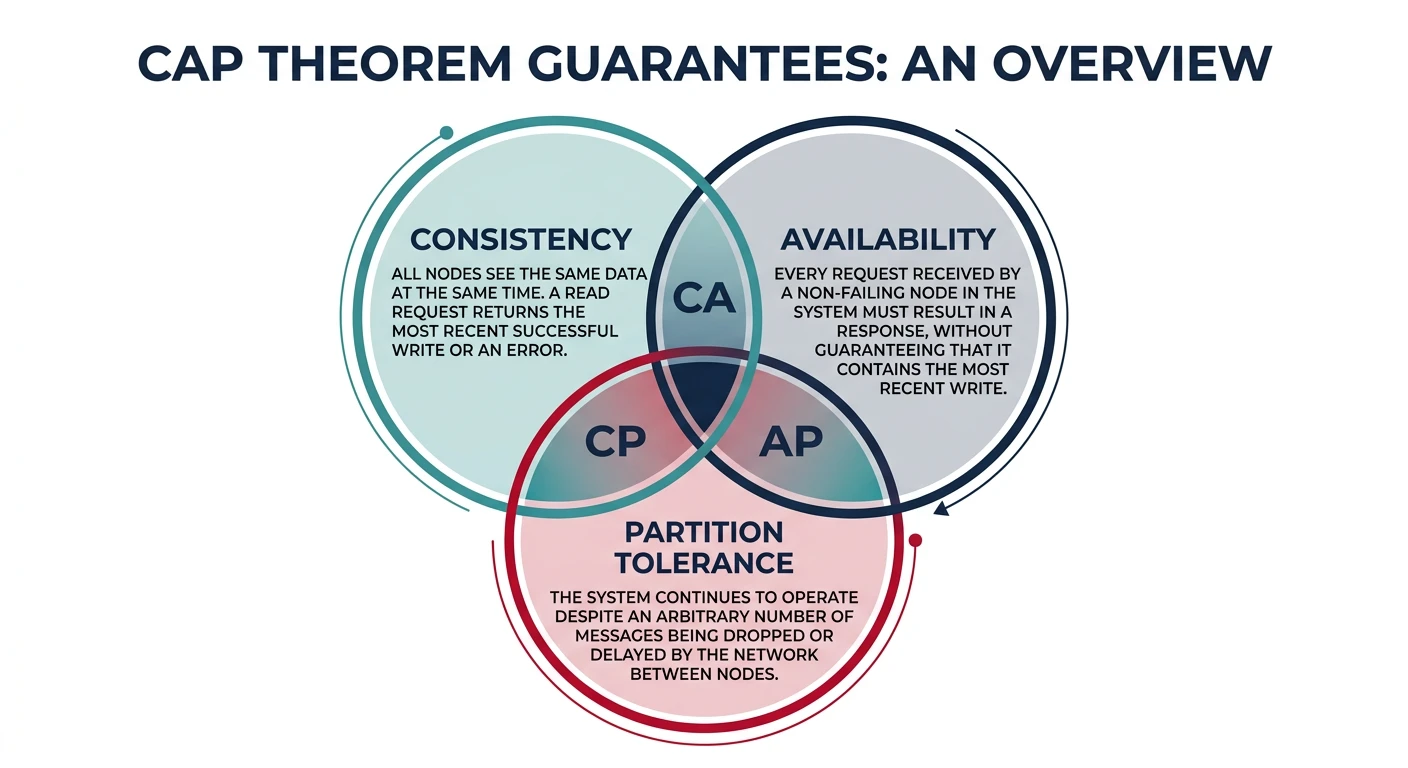
The CAP theorem states that a distributed system can provide at most two of three guarantees simultaneously: Consistency, Availability, and Partition tolerance. Understanding these trade-offs is fundamental to designing reliable distributed systems.
The CAP theorem triangle showing the three guarantees and their pairwise combinations — distributed systems must choose between CP, AP, or CA trade-offs
Key Insight: In practice, partition tolerance is non-negotiable in distributed systems. The real choice is between consistency and availability during network partitions.
The Three Guarantees
Consistency (C): Every read receives the most recent write or an error. All nodes see the same data at the same time.
Availability (A): Every request receives a non-error response, without guarantee it's the most recent write.
Partition Tolerance (P): System continues operating despite arbitrary message loss or failure between nodes.
CAP Visualization
# CAP Theorem - You can only pick 2 out of 3
Consistency (C)
/\
/ \
/ \
/ CA \ # CA: Consistent + Available
/________\ # (Not partition tolerant)
/\ /\
/ \ / \
/ CP \ / AP \
/______\ /______\
Partition Availability
Tolerance (P) (A)
# CP Systems: Consistent + Partition Tolerant
# - May become unavailable during partitions
# - Examples: MongoDB, HBase, Redis Cluster
# AP Systems: Available + Partition Tolerant
# - May return stale data during partitions
# - Examples: Cassandra, DynamoDB, CouchDB
# CA Systems: Consistent + Available
# - Cannot tolerate network partitions
# - Examples: Traditional RDBMS (single node)
CAP Trade-offs
CP Systems (Consistency + Partition Tolerance)
Prioritize consistency over availability. During network partitions, the system may reject requests to maintain consistency.
# CP System Behavior During Partition
# Normal operation
Client --> Node A --> Node B --> Node C
(Write) (Replicate) (Replicate)
# All nodes have consistent data
# During network partition
Client --> Node A [PARTITION] Node B, C
# Node A can't confirm replication to B and C
# CP system OPTIONS:
# 1. Reject the write (preserve consistency)
# 2. Accept write but return error until sync
# 3. Block until partition heals
# Example: MongoDB with majority write concern
from pymongo import MongoClient, WriteConcern
client = MongoClient('mongodb://localhost:27017')
db = client.mydb
# Require majority of nodes to acknowledge write
collection = db.get_collection(
'orders',
write_concern=WriteConcern(w='majority', wtimeout=5000)
)
try:
result = collection.insert_one({'order_id': '123', 'status': 'new'})
print("Write acknowledged by majority")
except Exception as e:
print(f"Write failed - partition or timeout: {e}")
# System chose Consistency over Availability
Use when: Financial transactions, inventory systems, any data where correctness is critical
MongoDBHBaseZooKeeper
AP Systems (Availability + Partition Tolerance)
Prioritize availability over consistency. During partitions, nodes continue serving requests with potentially stale data.
# AP System Behavior During Partition
# Normal operation
Client --> Node A --> Node B --> Node C
(Write) (Async) (Async)
# Writes replicate asynchronously
# During network partition
Client A --> Node A [PARTITION] Node B <-- Client B
(Write X=1) (Read X=?)
# AP system response:
# - Node A accepts write (X=1)
# - Node B serves read with old value (X=0)
# - Both clients get responses (Available!)
# - Data is temporarily inconsistent
# - After partition heals: conflict resolution
# Example: Cassandra with eventual consistency
from cassandra.cluster import Cluster
from cassandra import ConsistencyLevel
cluster = Cluster(['node1', 'node2', 'node3'])
session = cluster.connect('mydb')
# Write with ONE consistency (highly available)
session.execute(
"INSERT INTO orders (id, status) VALUES (%s, %s)",
('123', 'new'),
consistency_level=ConsistencyLevel.ONE # Just one node needed
)
# Read with ONE consistency (may get stale data)
result = session.execute(
"SELECT * FROM orders WHERE id = %s",
('123',),
consistency_level=ConsistencyLevel.ONE
)
Use when: Social media feeds, user sessions, analytics, shopping carts
CassandraDynamoDBCouchDB
CAP in Practice: System Comparison
Database
Default
Configurable
Notes
MongoDB
CP
Yes
Write concern adjustable
Cassandra
AP
Yes
Tunable consistency per query
DynamoDB
AP
Yes
Strong consistency option available
Redis Cluster
CP
Limited
Async replication with CP failover
CockroachDB
CP
No
Serializable isolation always
PostgreSQL
CA
N/A
Single node, no partition tolerance
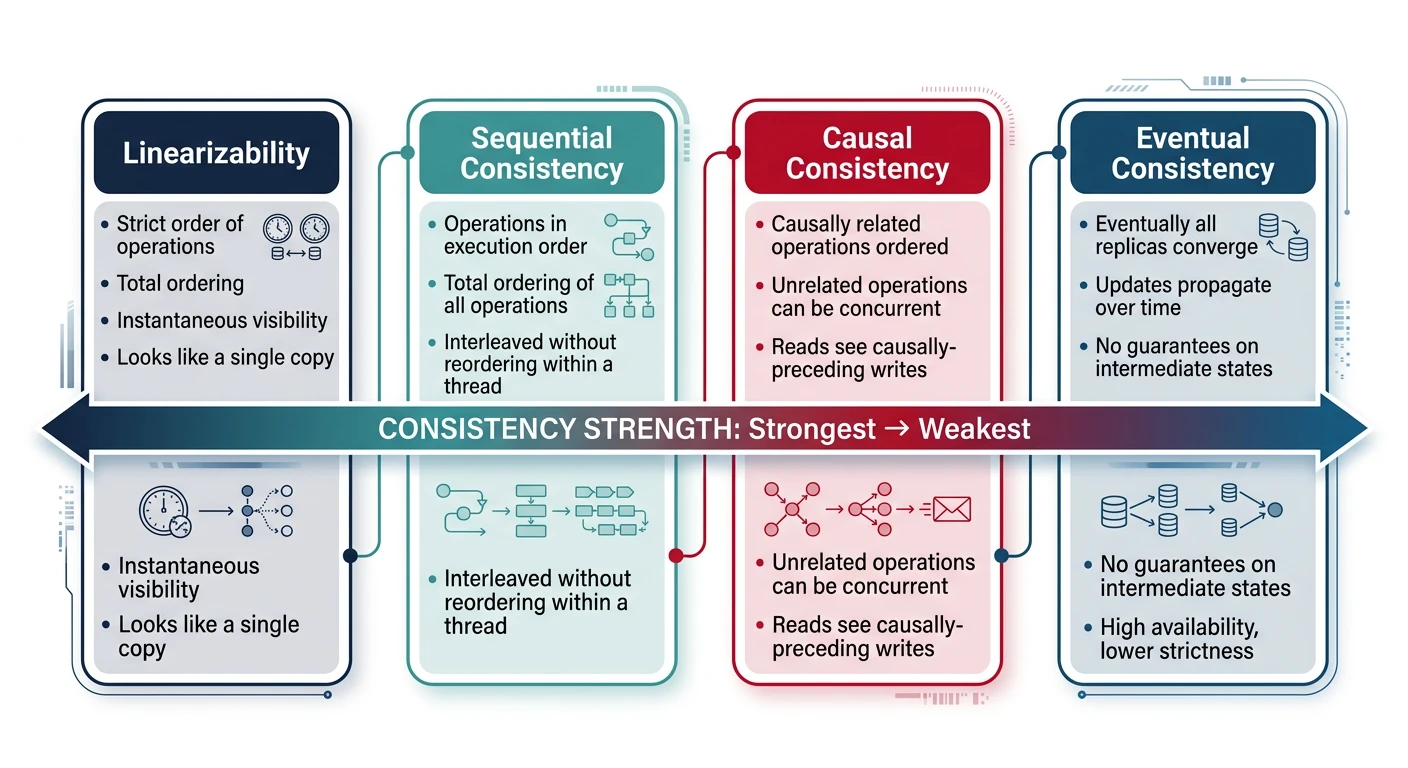
Consistency Models
Consistency models define the guarantees a distributed system provides about the order and visibility of operations across nodes.
The consistency model spectrum — from strict linearizability guaranteeing real-time ordering to eventual consistency allowing temporary divergence
Strong Consistency
Linearizability
The strongest consistency model. Operations appear instantaneous and in a global order that respects real-time.
# Linearizability: Operations have a single, global order
# Once a write completes, all subsequent reads see it
Timeline:
Client A: |--Write(X=1)--|
Client B: |--Read(X)--| # Must see X=1
Client C: |--Read(X)--| # May see X=0 or X=1
# (read started before write completed)
# Linearizable systems guarantee:
# 1. After write returns, all reads see new value
# 2. If read returns new value, all subsequent reads do too
# 3. Operations are totally ordered
# Implementation typically requires:
# - Consensus protocol (Raft, Paxos)
# - Quorum reads and writes
# - Coordination overhead (higher latency)
Sequential Consistency
Operations appear in a global order consistent with each client's program order, but not necessarily real-time order.
# Sequential Consistency Example
# All clients see same order, but may not match wall-clock time
# Client A operations:
A1: Write(X=1)
A2: Write(Y=1)
# Client B operations:
B1: Read(Y) -> 1
B2: Read(X) -> 0 # This is VALID in sequential consistency!
# Valid global ordering: A1, B2, B1, A2
# - Respects A's order (A1 before A2)
# - Respects B's order (B1 before B2)
# - But doesn't respect real-time (A2 "happened before" B1)
# Sequential consistency is weaker than linearizability
# because it doesn't preserve real-time ordering
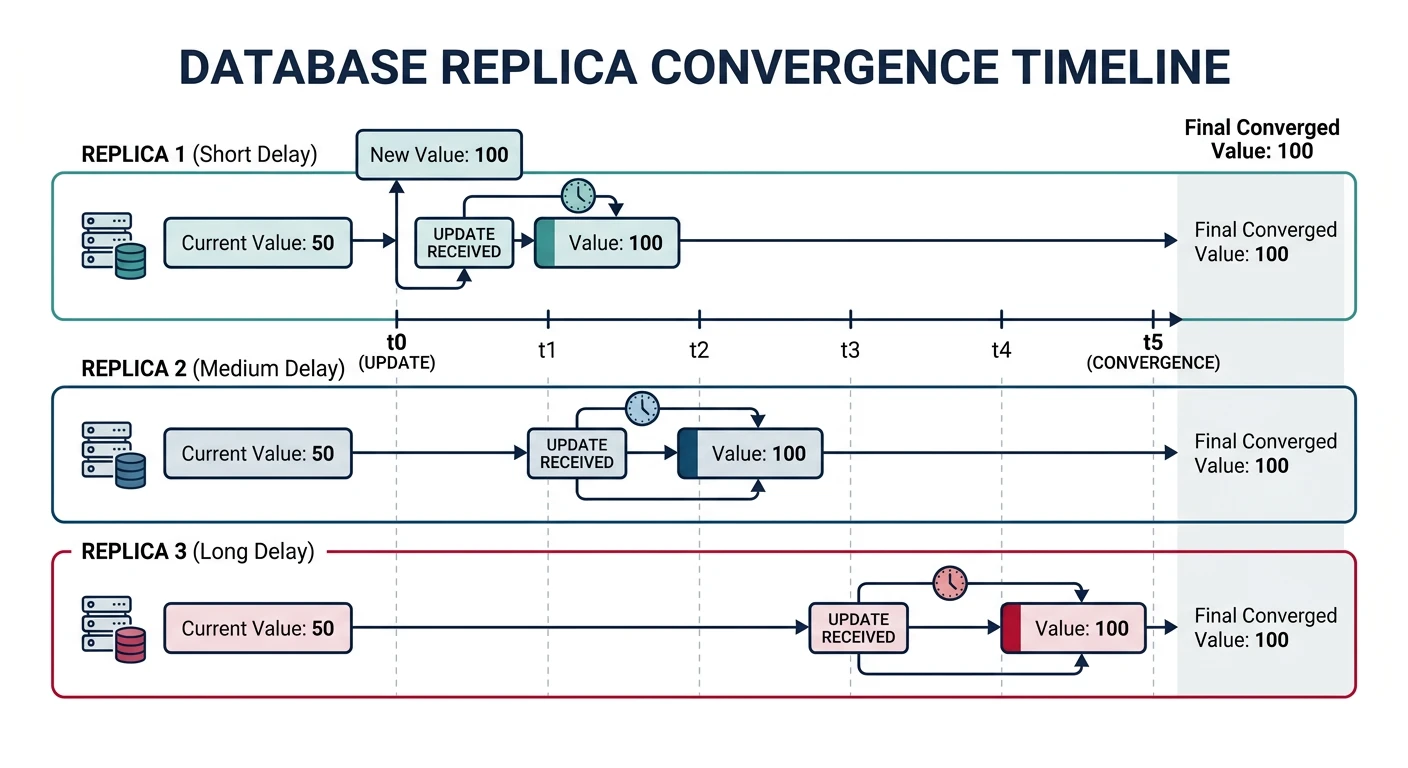
Eventual Consistency
If no new updates are made, eventually all replicas will converge to the same value. The "eventually" can range from milliseconds to hours.
Eventual consistency in action — replicas receive updates at different times but eventually converge to the same state
Eventual Consistency in Action
# Eventual Consistency Example: DNS
# When you update a DNS record, it propagates gradually
# T=0: Update DNS record
update_dns("example.com", "1.2.3.4", "5.6.7.8")
# T=1s: Server 1 sees new IP (5.6.7.8)
# T=5s: Server 2 still has old IP (1.2.3.4)
# T=30s: Server 3 gets update (5.6.7.8)
# T=60s: All servers consistent (5.6.7.8)
# Another example: Shopping cart in DynamoDB
class ShoppingCart:
def add_item(self, user_id, item):
# Write to nearest region (low latency)
self.db.put_item(
TableName='carts',
Item={
'user_id': user_id,
'items': self.get_items(user_id) + [item],
'updated_at': time.time()
}
)
# Replication to other regions happens async
# User in another region may see stale cart briefly
def get_items(self, user_id):
# Eventually consistent read (fast, cheap)
response = self.db.get_item(
TableName='carts',
Key={'user_id': user_id},
ConsistentRead=False # Eventually consistent
)
return response.get('Item', {}).get('items', [])
Tunable Consistency (Cassandra/DynamoDB)
# Cassandra Tunable Consistency
# N = Total replicas, W = Write acknowledgments, R = Read acknowledgments
# Strong consistency: W + R > N
# Example: N=3, W=2, R=2 (quorum)
# At least one node in read overlaps with write
# Eventual consistency: W + R <= N
# Example: N=3, W=1, R=1
# Reads may miss recent writes
# Common configurations:
# QUORUM: W=N/2+1, R=N/2+1 (strong, balanced)
# ONE/ONE: W=1, R=1 (fast, eventual)
# ALL/ONE: W=N, R=1 (write slow, read fast, strong)
# ONE/ALL: W=1, R=N (write fast, read slow, strong)
PACELC Extension: During Partition: choose Availability or Consistency. Else: choose Latency or Consistency. Even without partitions, there's a latency-consistency trade-off.
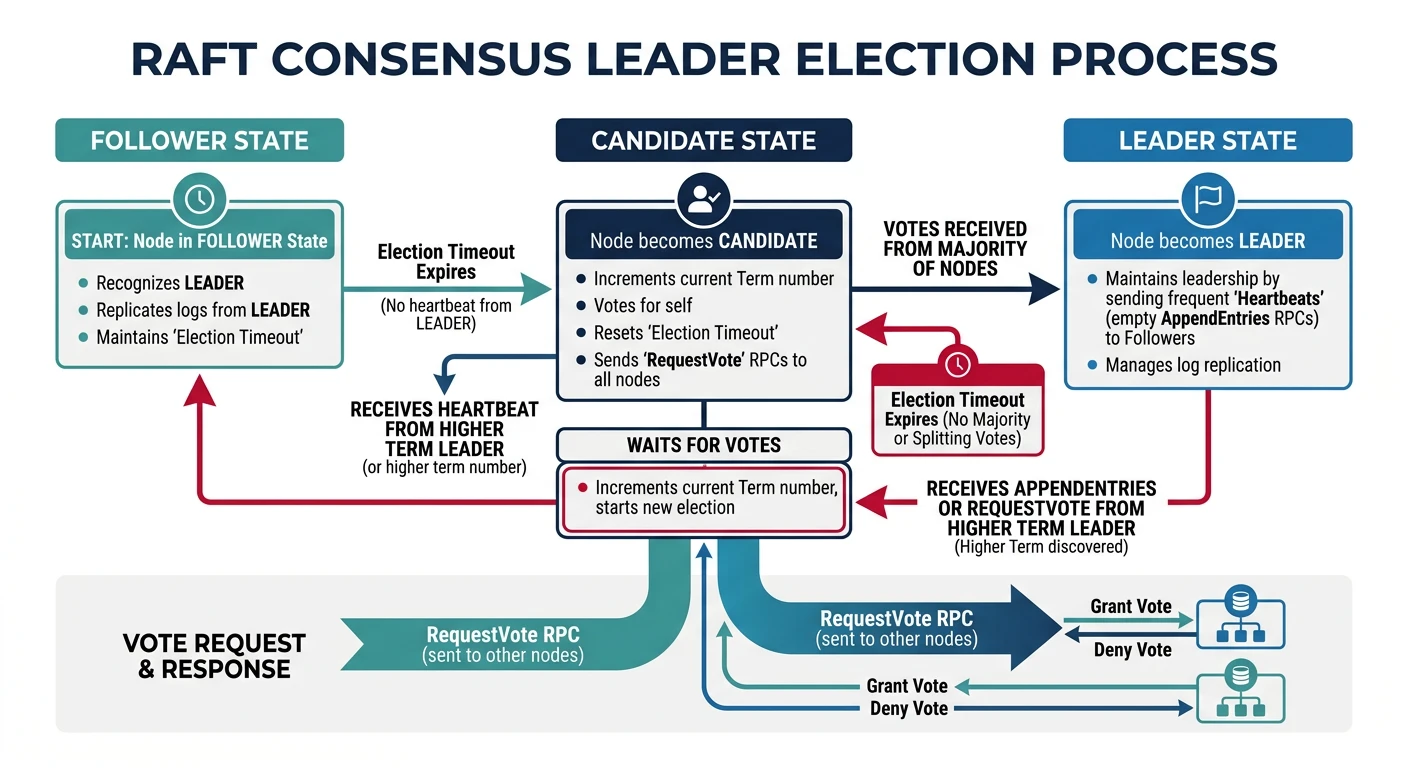
Consensus Algorithms
Consensus algorithms enable distributed nodes to agree on a single value even when some nodes fail. They are the foundation of consistent distributed systems.
Raft consensus state machine — nodes transition between follower, candidate, and leader roles through election timeouts and vote requests
Raft Consensus
Raft is designed to be understandable. It uses leader election and log replication.
# Raft Consensus Overview
# Node States
class NodeState:
FOLLOWER = "follower" # Default state, follows leader
CANDIDATE = "candidate" # Seeking to become leader
LEADER = "leader" # Accepts writes, replicates to followers
# Key Components:
# 1. Leader Election
# 2. Log Replication
# 3. Safety
class RaftNode:
def __init__(self, node_id, peers):
self.node_id = node_id
self.peers = peers
self.state = NodeState.FOLLOWER
self.current_term = 0
self.voted_for = None
self.log = [] # List of (term, command) entries
self.commit_index = 0
self.last_applied = 0
self.election_timeout = random.uniform(150, 300) # ms
def start_election(self):
"""Follower timeout -> become candidate"""
self.state = NodeState.CANDIDATE
self.current_term += 1
self.voted_for = self.node_id
votes = 1 # Vote for self
# Request votes from all peers
for peer in self.peers:
response = peer.request_vote(
term=self.current_term,
candidate_id=self.node_id,
last_log_index=len(self.log) - 1,
last_log_term=self.log[-1][0] if self.log else 0
)
if response.vote_granted:
votes += 1
# Majority wins
if votes > len(self.peers) // 2:
self.become_leader()
def become_leader(self):
"""Won election -> start leading"""
self.state = NodeState.LEADER
# Send heartbeats to prevent new elections
self.send_heartbeats()
def append_entries(self, command):
"""Leader receives client command"""
if self.state != NodeState.LEADER:
return redirect_to_leader()
# Append to local log
self.log.append((self.current_term, command))
# Replicate to followers
success_count = 1
for peer in self.peers:
if peer.replicate_log(self.log):
success_count += 1
# Commit when majority has entry
if success_count > len(self.peers) // 2:
self.commit_index = len(self.log) - 1
self.apply_command(command)
return success
etcdConsulCockroachDB
Paxos Consensus
Paxos is the original consensus algorithm. More complex but more flexible than Raft.
# Paxos Basic Protocol (Single-Decree)
# Three roles: Proposers, Acceptors, Learners
# Phase 1: Prepare
class Proposer:
def prepare(self, proposal_number):
"""Send prepare request to acceptors"""
promises = []
for acceptor in self.acceptors:
promise = acceptor.receive_prepare(proposal_number)
if promise:
promises.append(promise)
# Need majority of promises to proceed
if len(promises) > len(self.acceptors) // 2:
return self.phase2(proposal_number, promises)
class Acceptor:
def __init__(self):
self.promised_number = 0
self.accepted_number = 0
self.accepted_value = None
def receive_prepare(self, proposal_number):
"""Promise not to accept lower-numbered proposals"""
if proposal_number > self.promised_number:
self.promised_number = proposal_number
return Promise(
accepted_number=self.accepted_number,
accepted_value=self.accepted_value
)
return None # Reject
# Phase 2: Accept
class Proposer:
def phase2(self, proposal_number, promises):
"""Send accept request with value"""
# Use highest-numbered accepted value, or propose own
value = self.choose_value(promises)
accepts = 0
for acceptor in self.acceptors:
if acceptor.receive_accept(proposal_number, value):
accepts += 1
if accepts > len(self.acceptors) // 2:
# Value is chosen! Notify learners
self.notify_learners(value)
class Acceptor:
def receive_accept(self, proposal_number, value):
"""Accept if we haven't promised higher"""
if proposal_number >= self.promised_number:
self.promised_number = proposal_number
self.accepted_number = proposal_number
self.accepted_value = value
return True
return False
ChubbySpanner
Consensus Algorithm Comparison
Algorithm
Complexity
Performance
Used By
Raft
Understandable
Good
etcd, Consul, TiKV
Paxos
Complex
Good
Chubby, Spanner
ZAB
Moderate
Good
ZooKeeper
PBFT
High
Lower
Blockchain (Hyperledger)
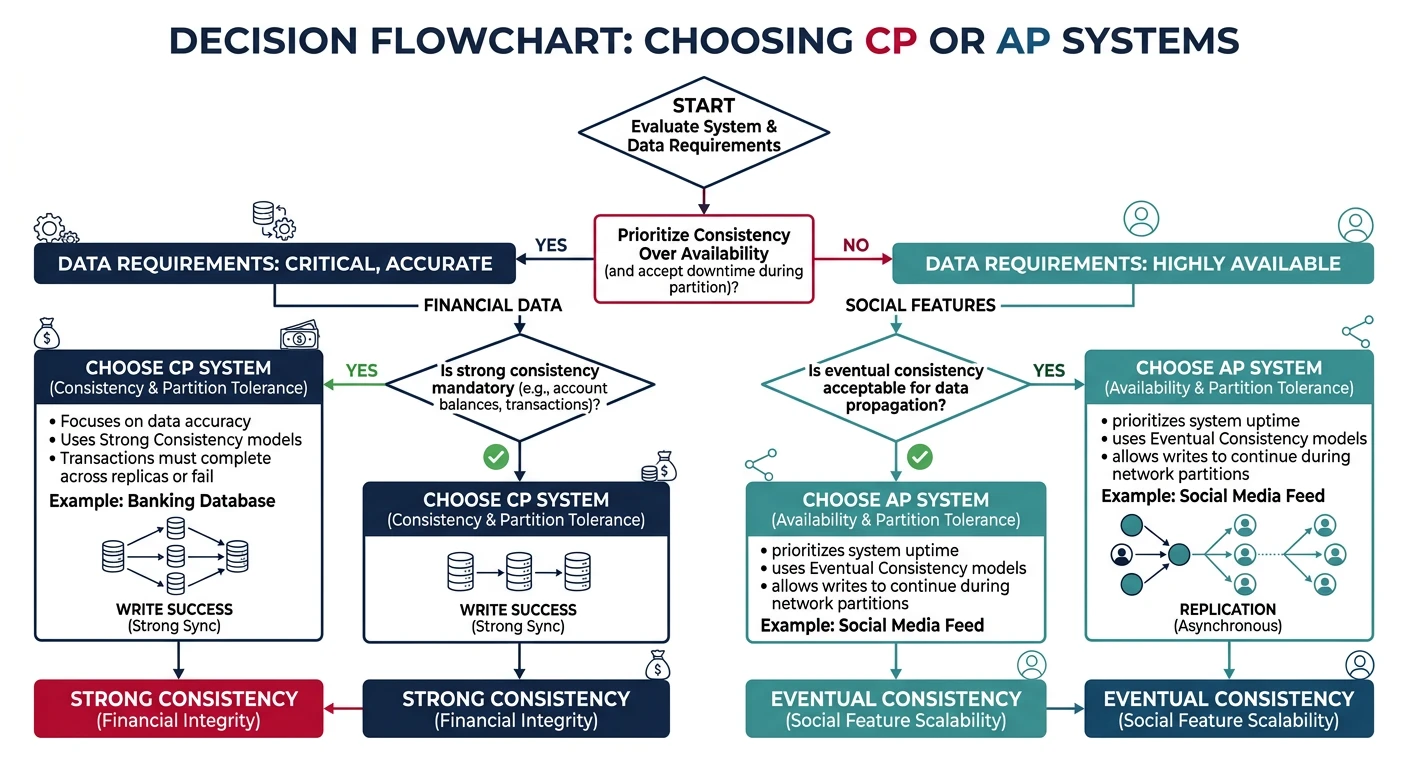
Decision flowchart for selecting CP vs AP trade-offs — financial and inventory systems favor consistency while social and analytics features prioritize availability
Practical Applications
E-commerce Inventory
# Problem: Prevent overselling during flash sales
# Solution: Strong consistency for inventory
class InventoryService:
def __init__(self, db):
self.db = db # Using CP database (e.g., CockroachDB)
def reserve_stock(self, product_id, quantity):
"""Atomic stock reservation with optimistic locking"""
with self.db.transaction() as tx:
# Read current stock with lock
product = tx.execute(
"SELECT stock, version FROM products WHERE id = %s FOR UPDATE",
(product_id,)
).fetchone()
if product['stock'] < quantity:
raise InsufficientStockError()
# Decrement stock with version check
result = tx.execute("""
UPDATE products
SET stock = stock - %s, version = version + 1
WHERE id = %s AND version = %s
""", (quantity, product_id, product['version']))
if result.rowcount == 0:
raise ConcurrencyConflictError("Retry")
return ReservationConfirmed(product_id, quantity)
Social Media Timeline
# Problem: Show user posts in timeline
# Solution: Eventual consistency is acceptable
class TimelineService:
def __init__(self, cassandra):
self.db = cassandra # AP database
def get_timeline(self, user_id):
"""Get timeline with eventual consistency (fast)"""
# Eventual consistent read - may miss recent posts
return self.db.execute(
"SELECT * FROM timeline WHERE user_id = %s LIMIT 100",
(user_id,),
consistency_level=ConsistencyLevel.ONE
)
def post_update(self, user_id, content):
"""Write post, fan out asynchronously"""
post_id = generate_id()
# Write to posts table
self.db.execute(
"INSERT INTO posts (id, user_id, content, created_at) VALUES (%s, %s, %s, %s)",
(post_id, user_id, content, datetime.now()),
consistency_level=ConsistencyLevel.QUORUM # Durable write
)
# Async fan-out to followers' timelines
self.queue.publish('timeline-fanout', {
'post_id': post_id,
'author_id': user_id
})
Design Decision Framework:
Financial data: Strong consistency (CP)
User sessions: Eventual consistency (AP)
Inventory: Strong consistency for decrements
Analytics: Eventual consistency
Configuration: Strong consistency (etcd/Consul)
Next Steps
Architecture Decision Record (ADR) Generator
Document your architecture trade-offs and CAP theorem choices. Download as Word, Excel, PDF, or PowerPoint.
Draft auto-saved
All data stays in your browser. Nothing is sent to or stored on any server.
Continue the Series
Part 7: Message Queues & Event-Driven
Review message queues and event-driven architecture patterns.