Distributed Systems Fundamentals
Series Navigation: This is Part 13 of the 15-part System Design Series. Review Part 12: Low-Level Design first.
System Design Mastery
Your 15-step learning path • Currently on Step 13
Introduction to System Design
Fundamentals, why it matters, key conceptsScalability Fundamentals
Horizontal vs vertical scaling, stateless designLoad Balancing & Caching
Algorithms, Redis, CDN patternsDatabase Design & Sharding
SQL vs NoSQL, replication, partitioningMicroservices Architecture
Decomposition, discovery, testing, resilienceAPI Design & REST/GraphQL
RESTful principles, GraphQL, gRPCMessage Queues & Event-Driven
Kafka, outbox, event sourcing, idempotent consumersCAP Theorem & Consistency
Distributed trade-offs, eventual consistencyRate Limiting & Security
Throttling algorithms, DDoS protectionMonitoring & Observability
Logging, metrics, distributed tracingReal-World Case Studies
URL shortener, chat, feed, video streamingData Modeling & Schema Design
Data modeling, schema design, indexing13
Distributed Systems Deep Dive
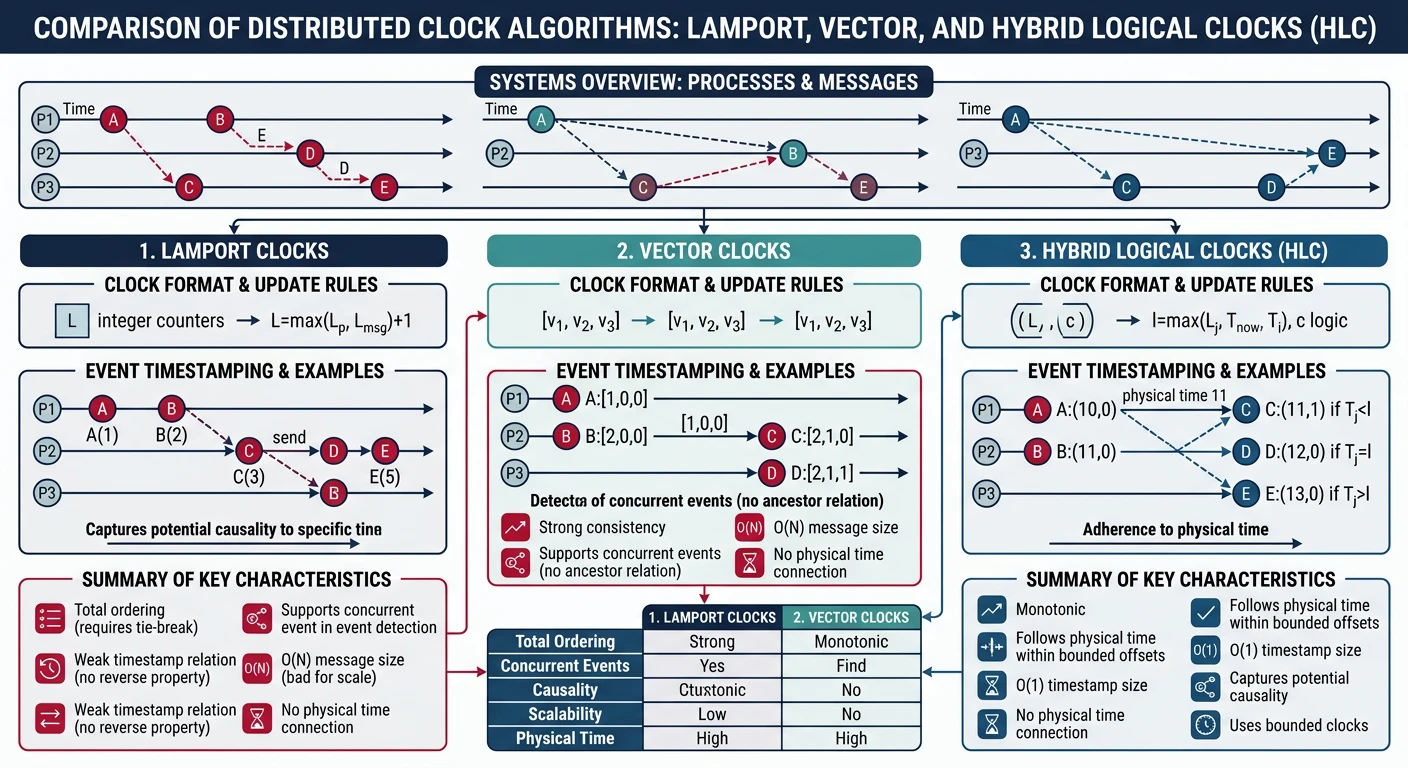
Consensus, Paxos, Raft, coordination14
Authentication & Security
OAuth, JWT, zero trust, compliance15
Questions & Trade-offs
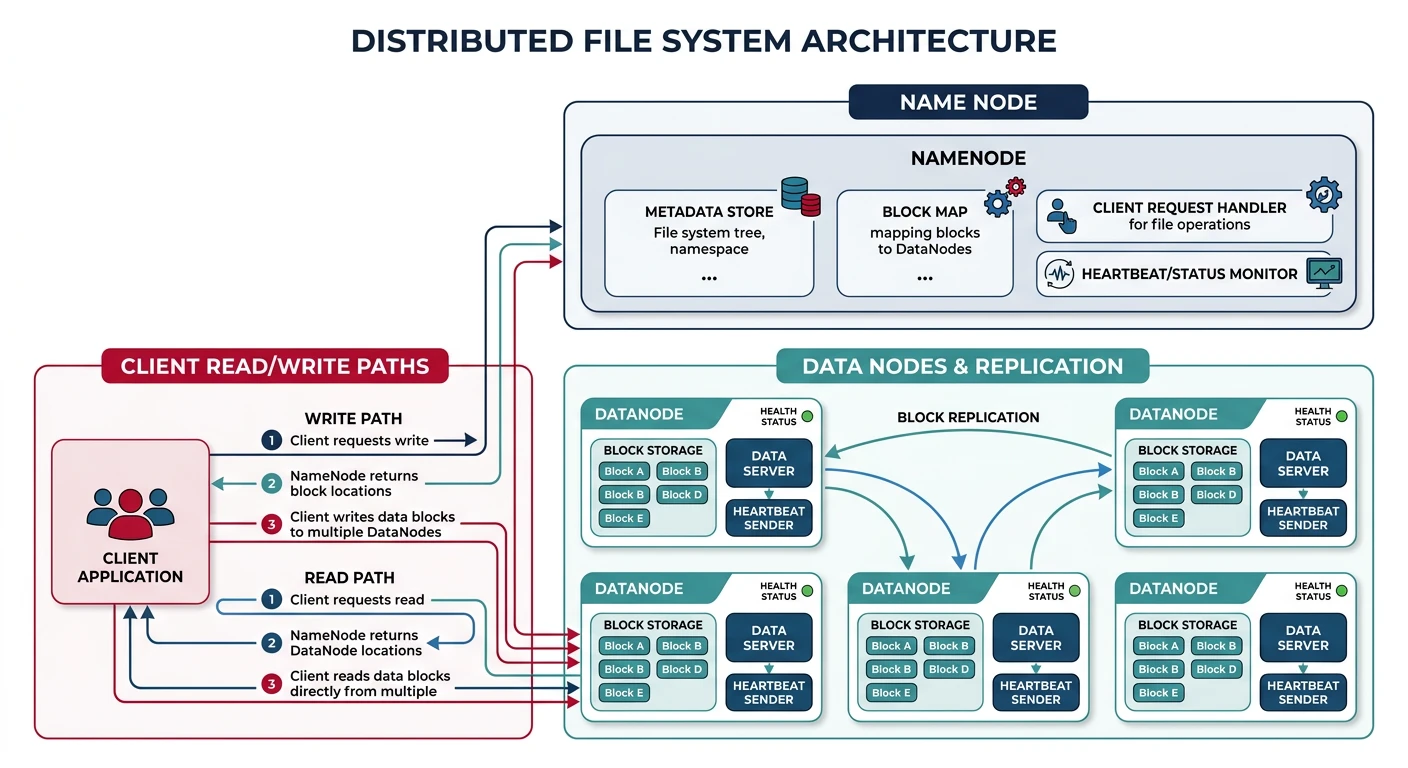
Common questions, SQL vs NoSQL, push vs pullDistributed Systems are systems where components are located on different networked computers and communicate by passing messages. They present unique challenges around consistency, availability, and partition tolerance that don't exist in single-machine systems.
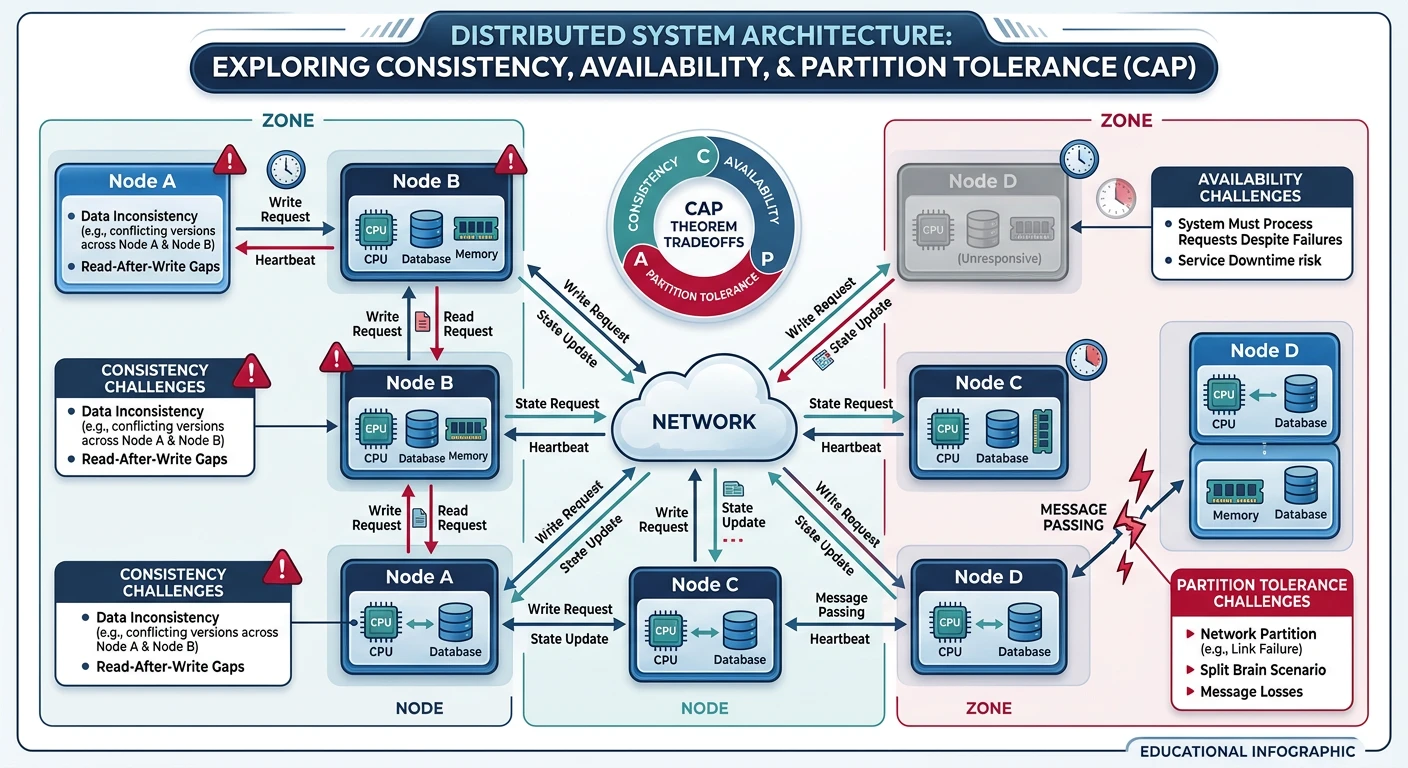
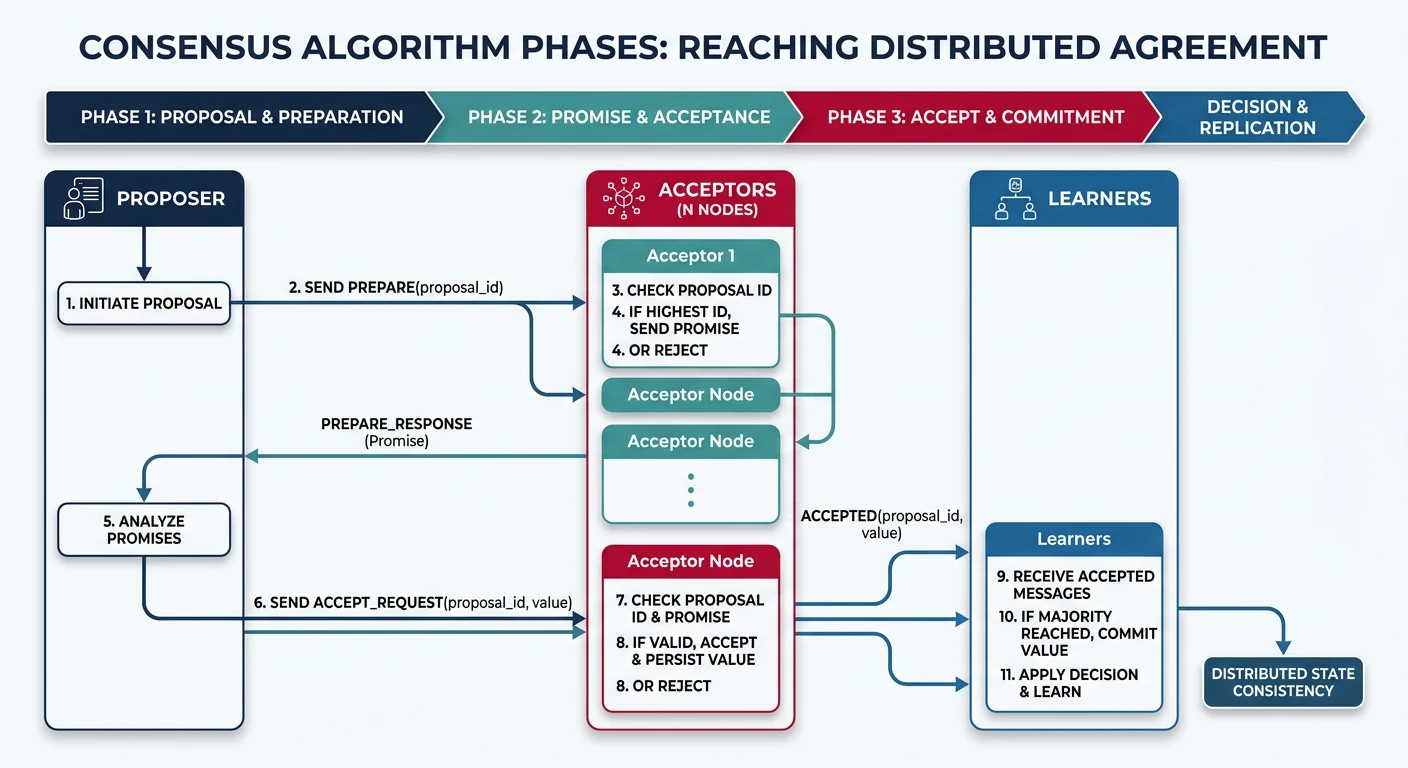
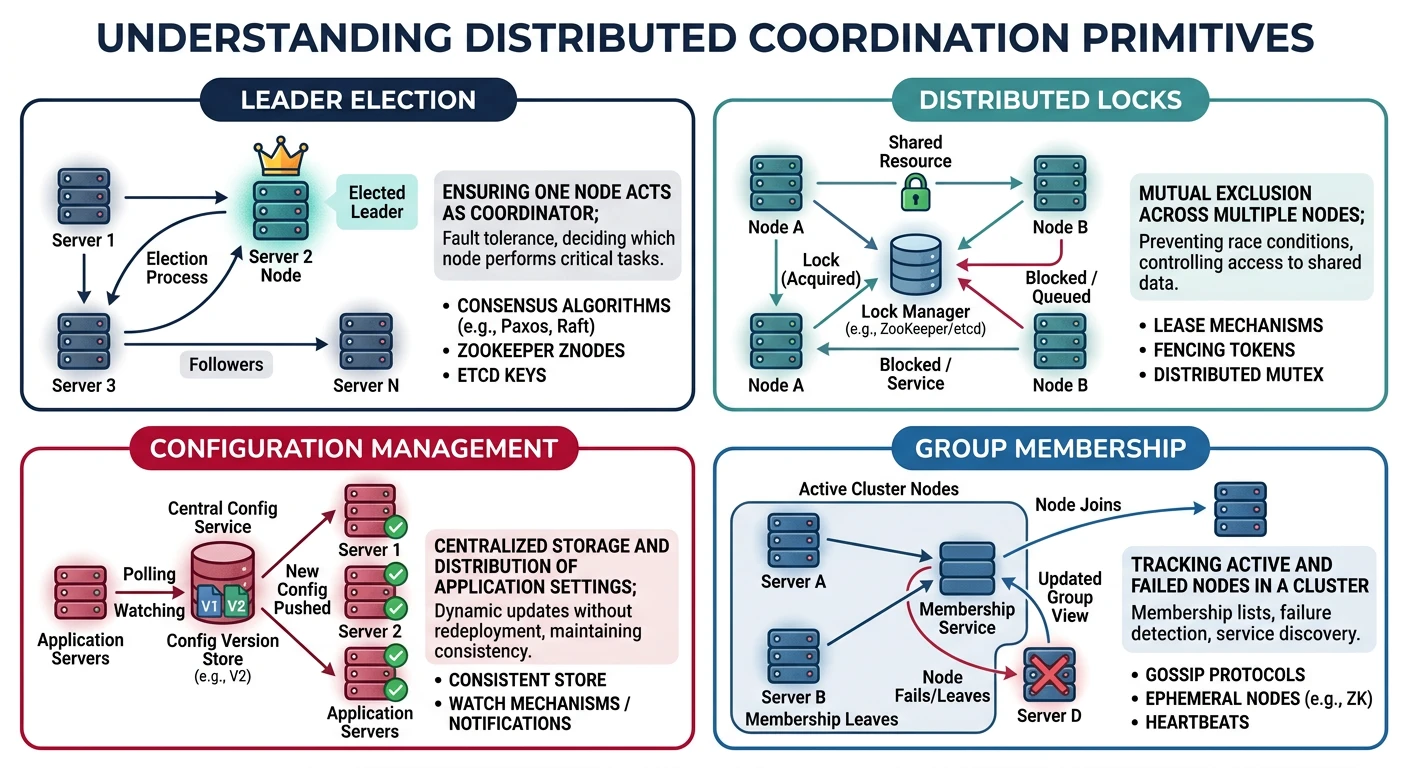
Key Insight: Distributed systems fail in ways that single-machine systems never do. Understanding consensus algorithms and coordination patterns is essential for building reliable distributed architectures.