Load Balancing
Series Navigation: This is Part 3 of the 15-part System Design Series. Review Part 2: Scalability first.
System Design Mastery
Your 15-step learning path • Currently on Step 3
Introduction to System Design
Fundamentals, why it matters, key conceptsScalability Fundamentals
Horizontal vs vertical scaling, stateless design3
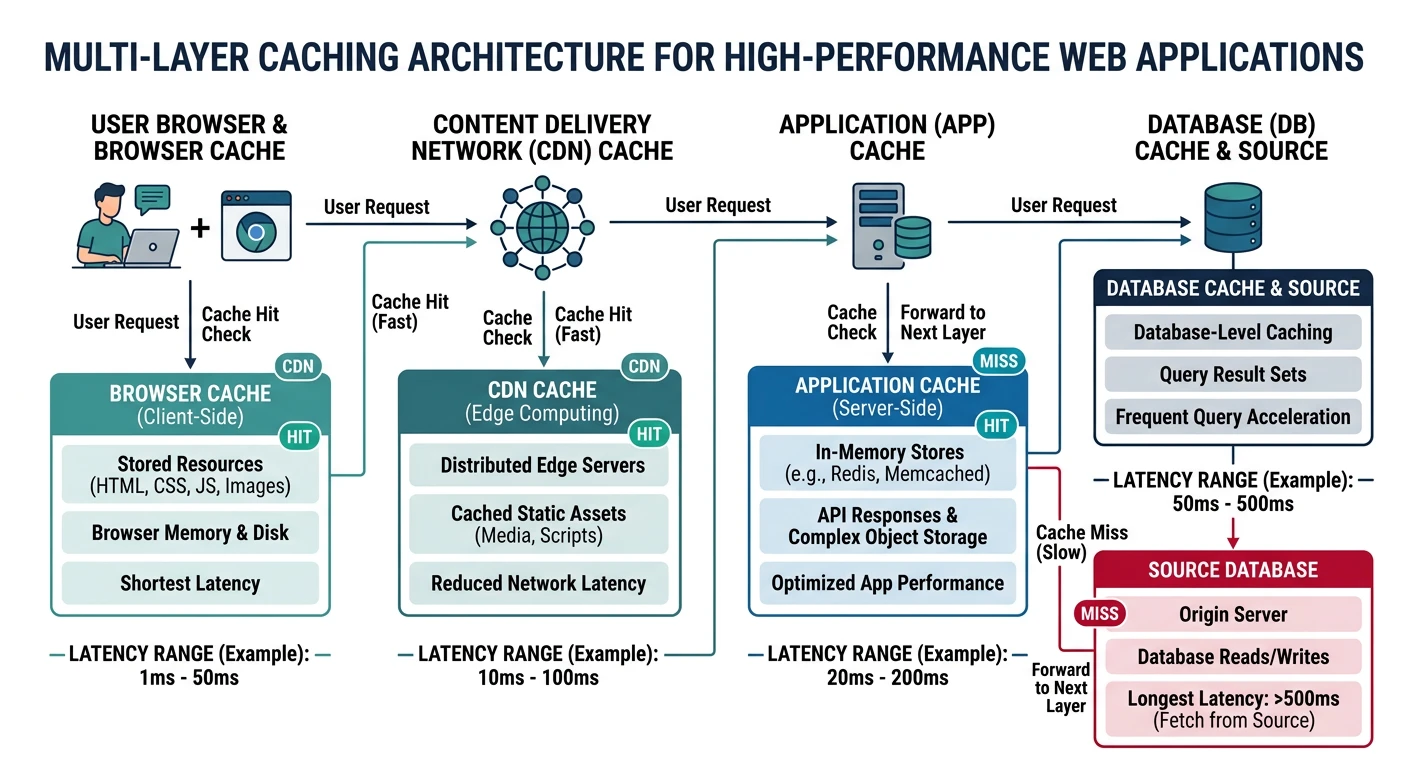
Load Balancing & Caching
Algorithms, Redis, CDN patterns4
Database Design & Sharding
SQL vs NoSQL, replication, partitioning5
Microservices Architecture
Decomposition, discovery, testing, resilience6
API Design & REST/GraphQL
RESTful principles, GraphQL, gRPC7
Message Queues & Event-Driven
Kafka, outbox, event sourcing, idempotent consumers8
CAP Theorem & Consistency
Distributed trade-offs, eventual consistency9
Rate Limiting & Security
Throttling algorithms, DDoS protection10
Monitoring & Observability
Logging, metrics, distributed tracing11
Real-World Case Studies
URL shortener, chat, feed, video streaming12
Data Modeling & Schema Design
Data modeling, schema design, indexing13
Distributed Systems Deep Dive
Consensus, Paxos, Raft, coordination14
Authentication & Security
OAuth, JWT, zero trust, compliance15
Questions & Trade-offs
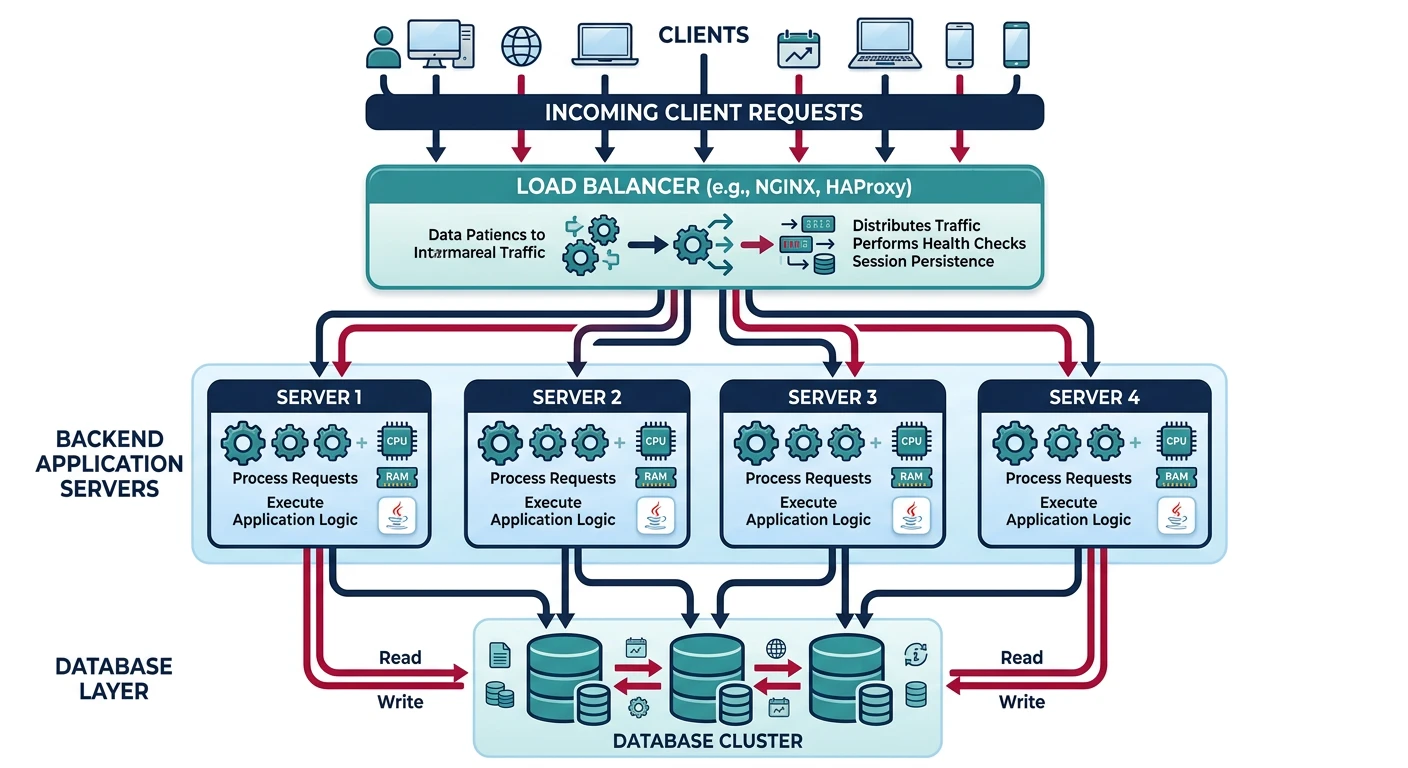
Common questions, SQL vs NoSQL, push vs pullLoad balancing is the process of distributing network traffic across multiple servers to ensure no single server bears too much demand. This improves responsiveness and availability of applications.
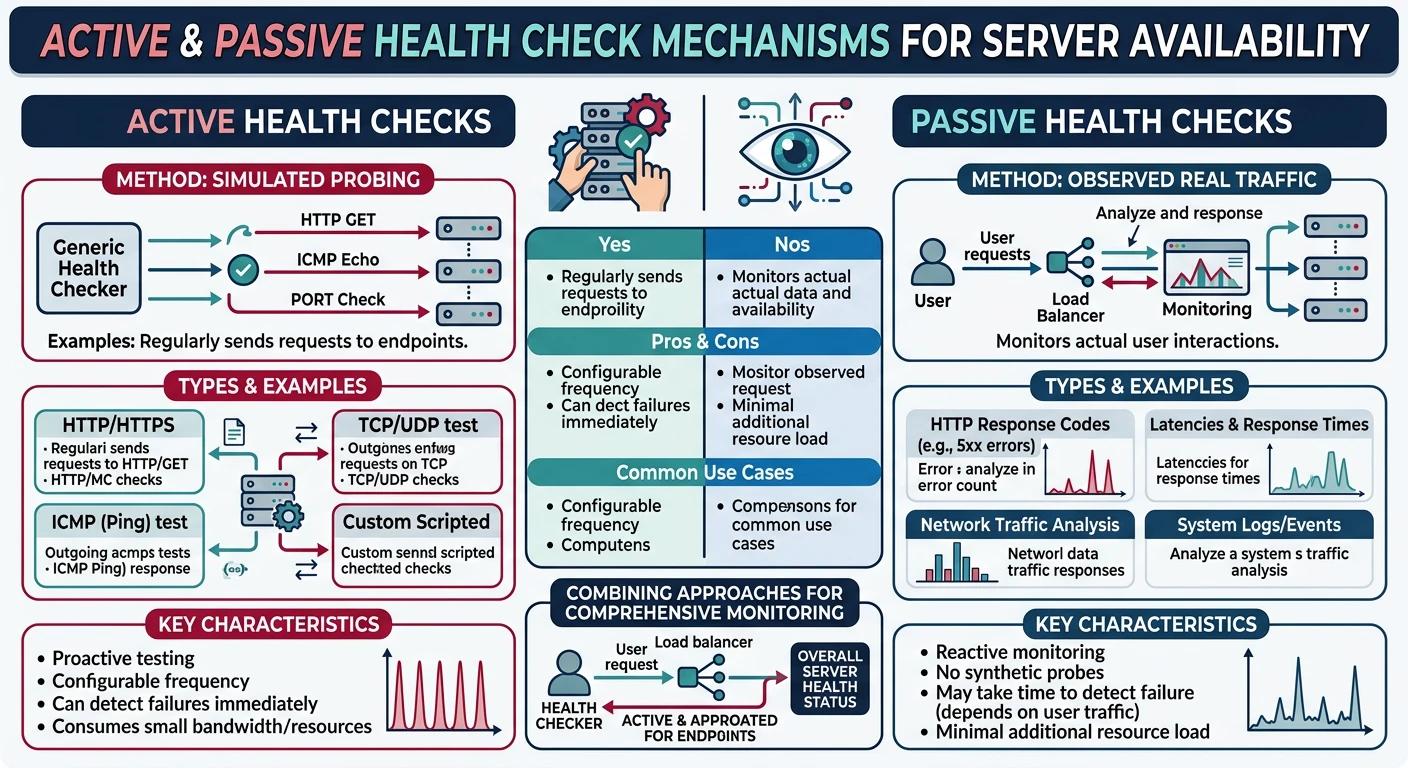
Key Insight: A good load balancer is invisible to users—it seamlessly routes requests while handling server failures and traffic spikes.
Why Load Balancing Matters
Without load balancing, a single server handles all incoming requests, creating a single point of failure. When traffic exceeds the server's capacity or the server fails, your entire application becomes unavailable.
Load balancers solve this by:
- Distributing traffic across multiple servers
- Detecting failures and routing around unhealthy servers
- Enabling scaling by adding/removing servers dynamically
- Improving performance through optimal server selection
- Providing SSL termination to offload encryption from backend servers
Types of Load Balancers
Load balancers operate at different layers of the OSI model:
Layer 4 (Transport Layer) Load Balancer
Operates at the TCP/UDP level. Routes traffic based on IP address and port number without inspecting packet contents.
- Pros: Very fast, low latency, simple to configure
- Cons: No content-based routing, limited visibility
- Use cases: High-throughput applications, database connections
Layer 7 (Application Layer) Load Balancer
Operates at the HTTP/HTTPS level. Can inspect request content and make intelligent routing decisions.
- Pros: Content-based routing, SSL termination, request modification
- Cons: Higher latency, more resource-intensive
- Use cases: Web applications, API gateways, microservices
# NGINX Layer 7 Load Balancer Configuration
upstream api_servers {
server api1.example.com:8080;
server api2.example.com:8080;
server api3.example.com:8080;
}
upstream static_servers {
server static1.example.com:80;
server static2.example.com:80;
}
server {
listen 443 ssl;
server_name example.com;
# Route API requests to API servers
location /api/ {
proxy_pass http://api_servers;
}
# Route static content to static servers
location /static/ {
proxy_pass http://static_servers;
}
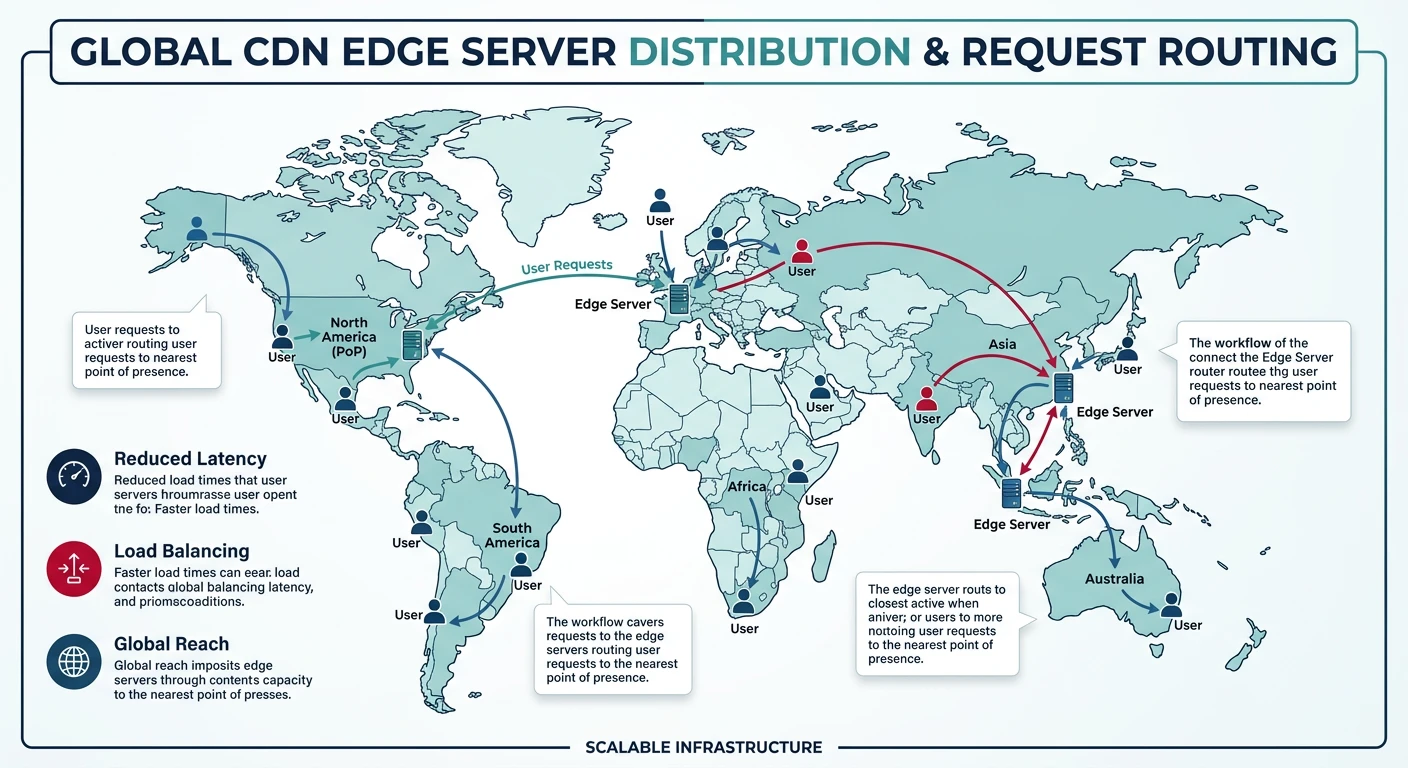
}Global vs. Local Load Balancing
| Feature | Local Load Balancing | Global Load Balancing (GSLB) |
|---|---|---|
| Scope | Single data center | Multiple data centers/regions |
| Routing Decision | Server health, capacity | Geographic location, latency, availability |
| Technology | HAProxy, NGINX, AWS ALB | DNS-based, Cloudflare, AWS Route 53 |
| Failover | Within data center | Across regions/continents |