Series Navigation: This is Part 13 of the 17-part API Development Series. Review Part 12: Monitoring & Analytics first.
API Development Mastery
Your 17-step learning path • Currently on Step 13
Backend API Fundamentals
REST, HTTP, status codes, URI designData Layer & Persistence
Database integration, CRUD, transactions, RedisOpenAPI Specification
Contract-first design, OpenAPI 3.0/3.1Documentation & DX
Swagger UI, Redoc, developer portalsAuthentication & Authorization
OAuth 2.0, JWT, RBAC, ABACSecurity Hardening
OWASP Top 10, input validation, CORSAWS API Gateway
REST/HTTP APIs, Lambda integration, WAFAzure API Management
Policies, products, developer portalGCP Apigee
API proxies, monetization, analyticsArchitecture Patterns
Gateway, BFF, microservices, DDDVersioning & Governance
SemVer, deprecation, lifecycleMonitoring & Analytics
Observability, tracing, SLIs/SLOs13
Performance & Rate Limiting
Caching, throttling, load testing14
GraphQL & gRPC
Alternative API styles, Protocol Buffers15
Testing & Contracts
Contract testing, Pact, Postman/Newman16
CI/CD & Automation
Spectral, GitHub Actions, Terraform17
API Product Management
API as Product, monetization, ecosystemsLatency Optimization
Understanding Latency
API latency is the time from when a client sends a request to when it receives the response. Optimizing latency improves user experience and reduces infrastructure costs.
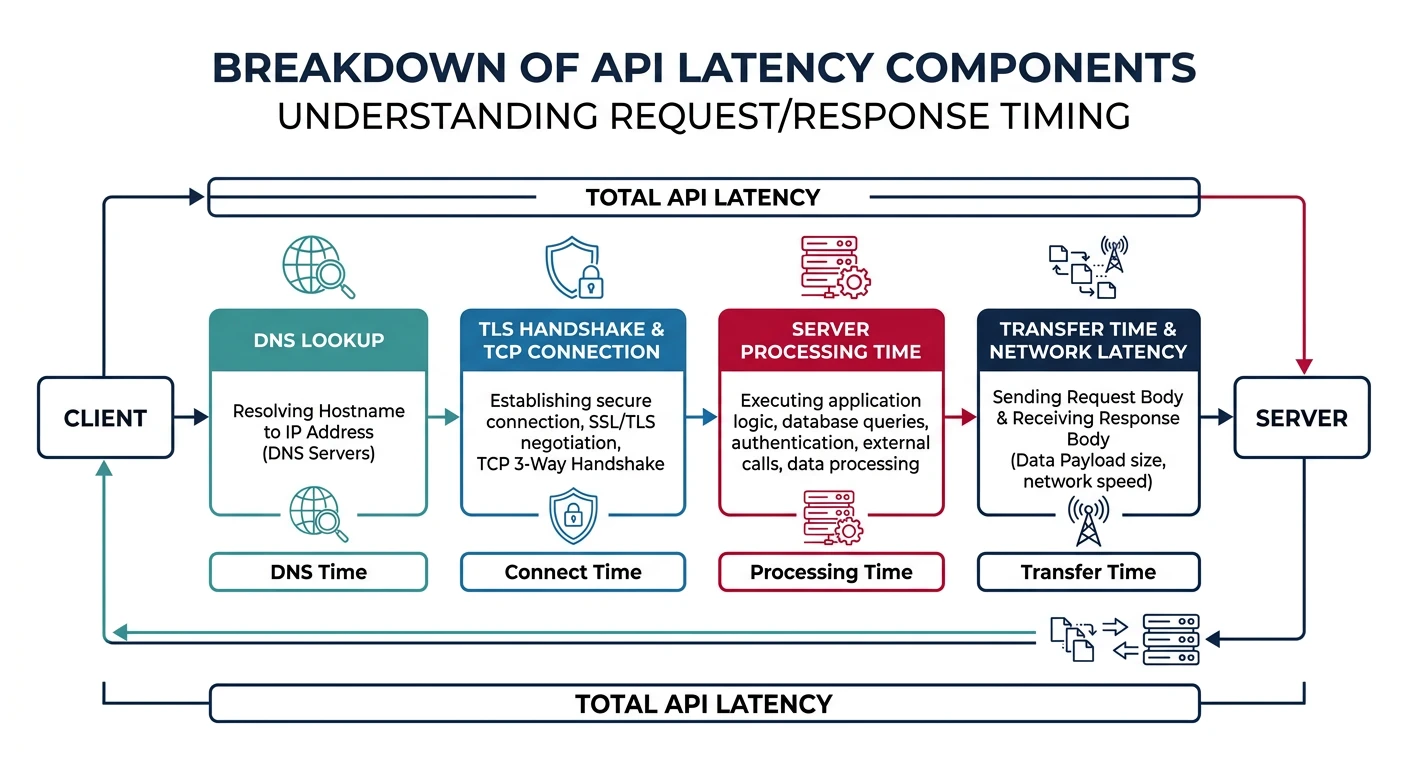
Latency Components
| Component | Typical Time | Optimization |
|---|---|---|
| DNS Lookup | 20-120ms | DNS caching, shorter TTL |
| TCP/TLS Handshake | 50-150ms | Connection pooling, HTTP/2 |
| Server Processing | 10-500ms | Query optimization, caching |
| Data Transfer | Variable | Compression, pagination |
// Database query optimization
const { Pool } = require('pg');
const pool = new Pool({
max: 20, // Connection pool size
idleTimeoutMillis: 30000,
connectionTimeoutMillis: 2000
});
// Optimized query with indexes
async function getTasksOptimized(userId, status, limit = 20, cursor) {
// Use index: CREATE INDEX idx_tasks_user_status ON tasks(user_id, status, created_at DESC)
const query = `
SELECT id, title, status, created_at
FROM tasks
WHERE user_id = $1
AND status = $2
AND ($3::timestamp IS NULL OR created_at < $3)
ORDER BY created_at DESC
LIMIT $4
`;
const result = await pool.query(query, [userId, status, cursor, limit]);
return {
items: result.rows,
nextCursor: result.rows.length === limit
? result.rows[limit - 1].created_at
: null
};
}Caching Strategies
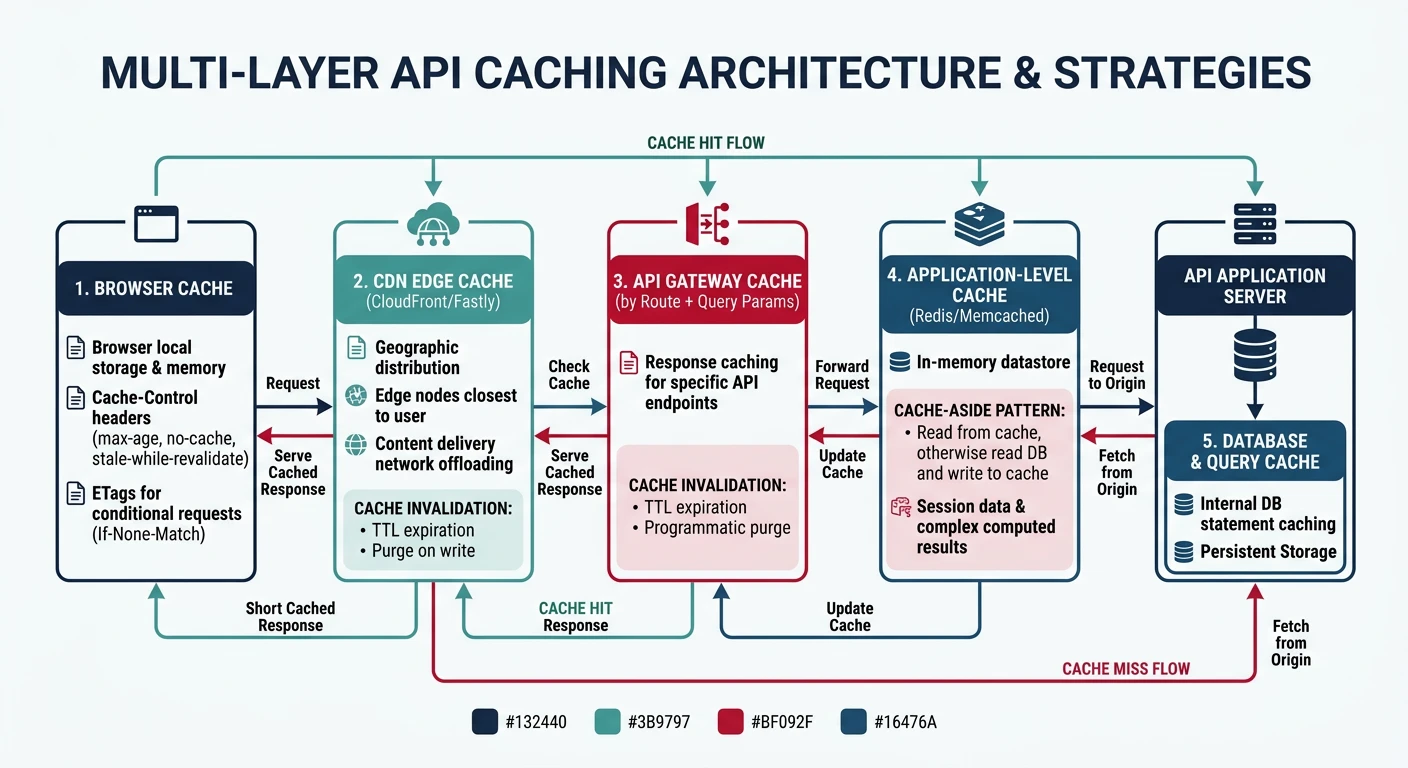
Cache Layers
Multi-Layer Caching:
- CDN: Edge caching for static/public data
- API Gateway: Response caching per route
- Application: In-memory (Redis) for hot data
- Database: Query result caching
// Redis caching middleware
const Redis = require('ioredis');
const redis = new Redis(process.env.REDIS_URL);
const cacheMiddleware = (options = {}) => {
const { ttl = 300, keyFn } = options;
return async (req, res, next) => {
// Generate cache key
const key = keyFn
? keyFn(req)
: `cache:${req.method}:${req.originalUrl}`;
// Try cache first
const cached = await redis.get(key);
if (cached) {
res.set('X-Cache', 'HIT');
return res.json(JSON.parse(cached));
}
// Store original json method
const originalJson = res.json.bind(res);
res.json = async (data) => {
// Cache successful responses
if (res.statusCode < 400) {
await redis.setex(key, ttl, JSON.stringify(data));
}
res.set('X-Cache', 'MISS');
return originalJson(data);
};
next();
};
};
// Usage
app.get('/api/products/:id',
cacheMiddleware({ ttl: 600 }),
getProduct
);Cache Invalidation
// Cache invalidation patterns
async function updateTask(taskId, updates) {
// Update database
const task = await db.tasks.update(taskId, updates);
// Invalidate related caches
await Promise.all([
redis.del(`cache:GET:/api/tasks/${taskId}`),
redis.del(`cache:GET:/api/users/${task.userId}/tasks`),
redis.del(`cache:GET:/api/tasks?status=${task.status}`)
]);
return task;
}
// Pattern-based invalidation
async function invalidateCachePattern(pattern) {
const keys = await redis.keys(pattern);
if (keys.length > 0) {
await redis.del(...keys);
}
}Load Testing
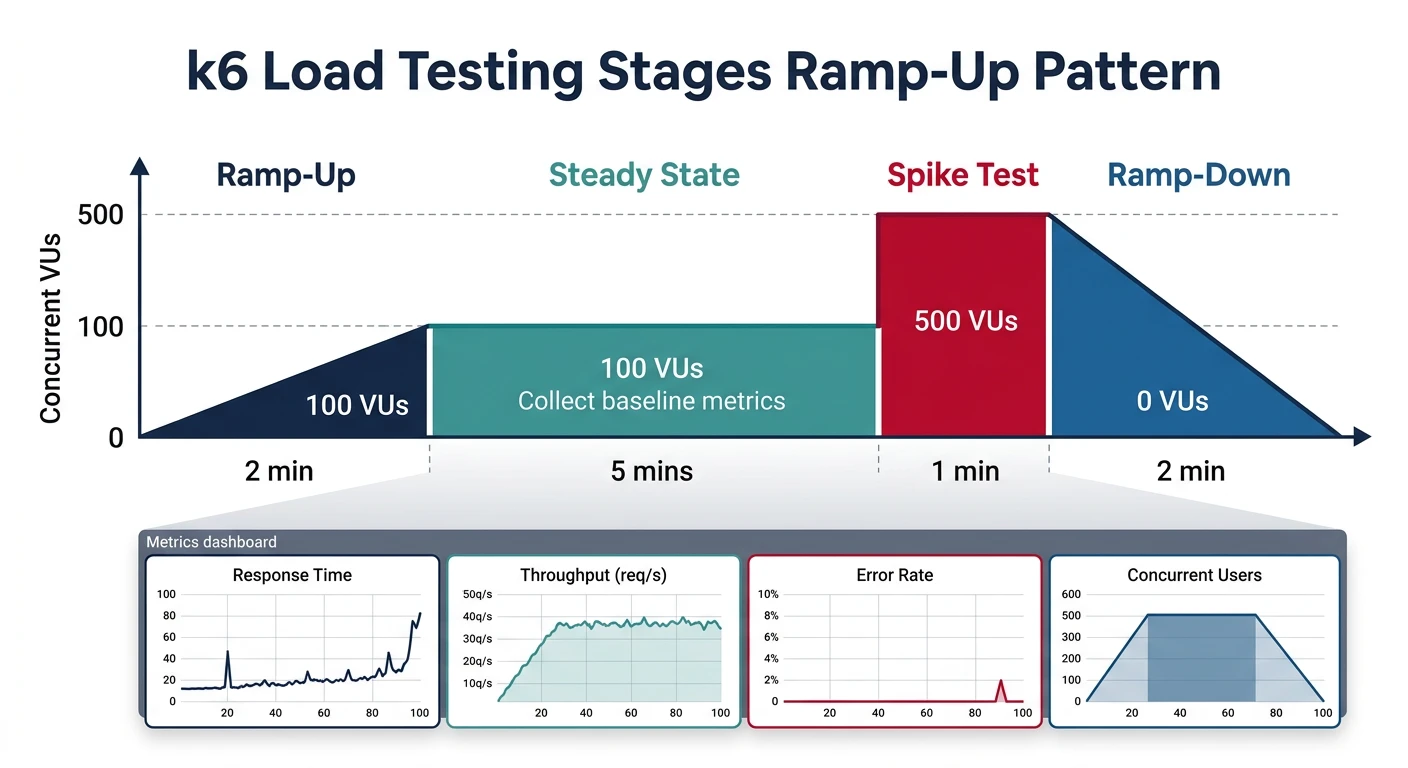
K6 Load Testing
// load-test.js - K6 script
import http from 'k6/http';
import { check, sleep } from 'k6';
import { Rate, Trend } from 'k6/metrics';
const errorRate = new Rate('errors');
const taskLatency = new Trend('task_latency');
export const options = {
stages: [
{ duration: '30s', target: 10 }, // Ramp up to 10 users
{ duration: '1m', target: 50 }, // Ramp up to 50 users
{ duration: '2m', target: 50 }, // Stay at 50 users
{ duration: '30s', target: 0 } // Ramp down
],
thresholds: {
http_req_duration: ['p(95)<200'], // 95% under 200ms
errors: ['rate<0.01'] // Error rate under 1%
}
};
export default function () {
const baseUrl = 'https://api.example.com';
const token = 'Bearer ' + __ENV.API_TOKEN;
// Test: List tasks
const listRes = http.get(`${baseUrl}/api/tasks`, {
headers: { Authorization: token }
});
check(listRes, {
'list status 200': (r) => r.status === 200,
'list has items': (r) => JSON.parse(r.body).items.length > 0
});
errorRate.add(listRes.status !== 200);
taskLatency.add(listRes.timings.duration);
sleep(1);
// Test: Create task
const createRes = http.post(`${baseUrl}/api/tasks`,
JSON.stringify({ title: `Load Test Task ${Date.now()}` }),
{
headers: {
Authorization: token,
'Content-Type': 'application/json'
}
}
);
check(createRes, {
'create status 201': (r) => r.status === 201
});
sleep(1);
}Rate Limiting Algorithms
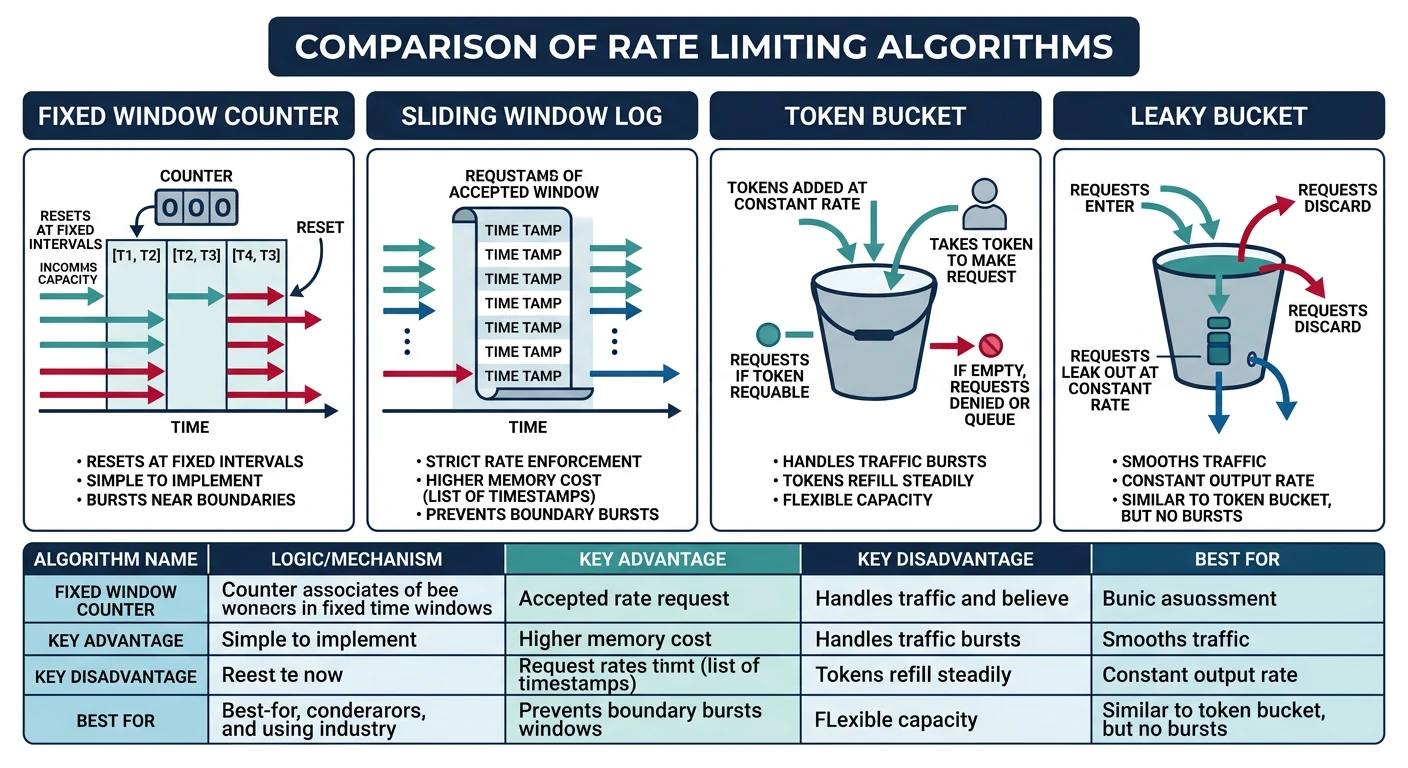
Algorithm Comparison
Rate Limiting Algorithms
| Algorithm | How It Works | Best For |
|---|---|---|
| Fixed Window | Count per time window | Simple quota enforcement |
| Sliding Window | Weighted rolling window | Smooth rate control |
| Token Bucket | Tokens refill over time | Burst handling |
| Leaky Bucket | Fixed output rate queue | Consistent throughput |
// Sliding window rate limiter with Redis
const Redis = require('ioredis');
const redis = new Redis();
async function slidingWindowRateLimit(key, limit, windowMs) {
const now = Date.now();
const windowStart = now - windowMs;
const multi = redis.multi();
// Remove old entries
multi.zremrangebyscore(key, 0, windowStart);
// Count current window
multi.zcard(key);
// Add current request
multi.zadd(key, now, `${now}-${Math.random()}`);
// Set expiry
multi.pexpire(key, windowMs);
const results = await multi.exec();
const count = results[1][1];
return {
allowed: count < limit,
current: count,
limit,
remaining: Math.max(0, limit - count),
resetAt: now + windowMs
};
}
// Rate limiting middleware
const rateLimitMiddleware = (options) => {
return async (req, res, next) => {
const key = `ratelimit:${req.ip}:${req.path}`;
const result = await slidingWindowRateLimit(key, options.limit, options.windowMs);
// Set standard headers
res.set({
'X-RateLimit-Limit': result.limit,
'X-RateLimit-Remaining': result.remaining,
'X-RateLimit-Reset': Math.ceil(result.resetAt / 1000),
'RateLimit-Policy': `${result.limit};w=${options.windowMs / 1000}`
});
if (!result.allowed) {
res.set('Retry-After', Math.ceil((result.resetAt - Date.now()) / 1000));
return res.status(429).json({
error: 'Too Many Requests',
retryAfter: Math.ceil((result.resetAt - Date.now()) / 1000)
});
}
next();
};
};
// Usage: 100 requests per minute
app.use('/api/', rateLimitMiddleware({ limit: 100, windowMs: 60000 }));Throttling Patterns
Tiered Rate Limits
// Tiered rate limits by subscription plan
const rateLimitTiers = {
free: { limit: 100, windowMs: 60000 }, // 100/min
basic: { limit: 1000, windowMs: 60000 }, // 1000/min
premium: { limit: 10000, windowMs: 60000 }, // 10000/min
enterprise: { limit: Infinity } // Unlimited
};
async function tieredRateLimit(req, res, next) {
const subscription = await getSubscription(req.user.id);
const tier = rateLimitTiers[subscription.plan];
if (tier.limit === Infinity) {
return next(); // Skip rate limiting for enterprise
}
const key = `ratelimit:${req.user.id}`;
const result = await slidingWindowRateLimit(key, tier.limit, tier.windowMs);
if (!result.allowed) {
return res.status(429).json({
error: 'Rate limit exceeded',
plan: subscription.plan,
upgradeUrl: '/pricing'
});
}
next();
}Scaling Strategies
Horizontal Scaling
Scaling Approaches:
- Vertical: Bigger servers (limited by hardware)
- Horizontal: More instances behind load balancer
- Auto-scaling: Dynamic based on metrics
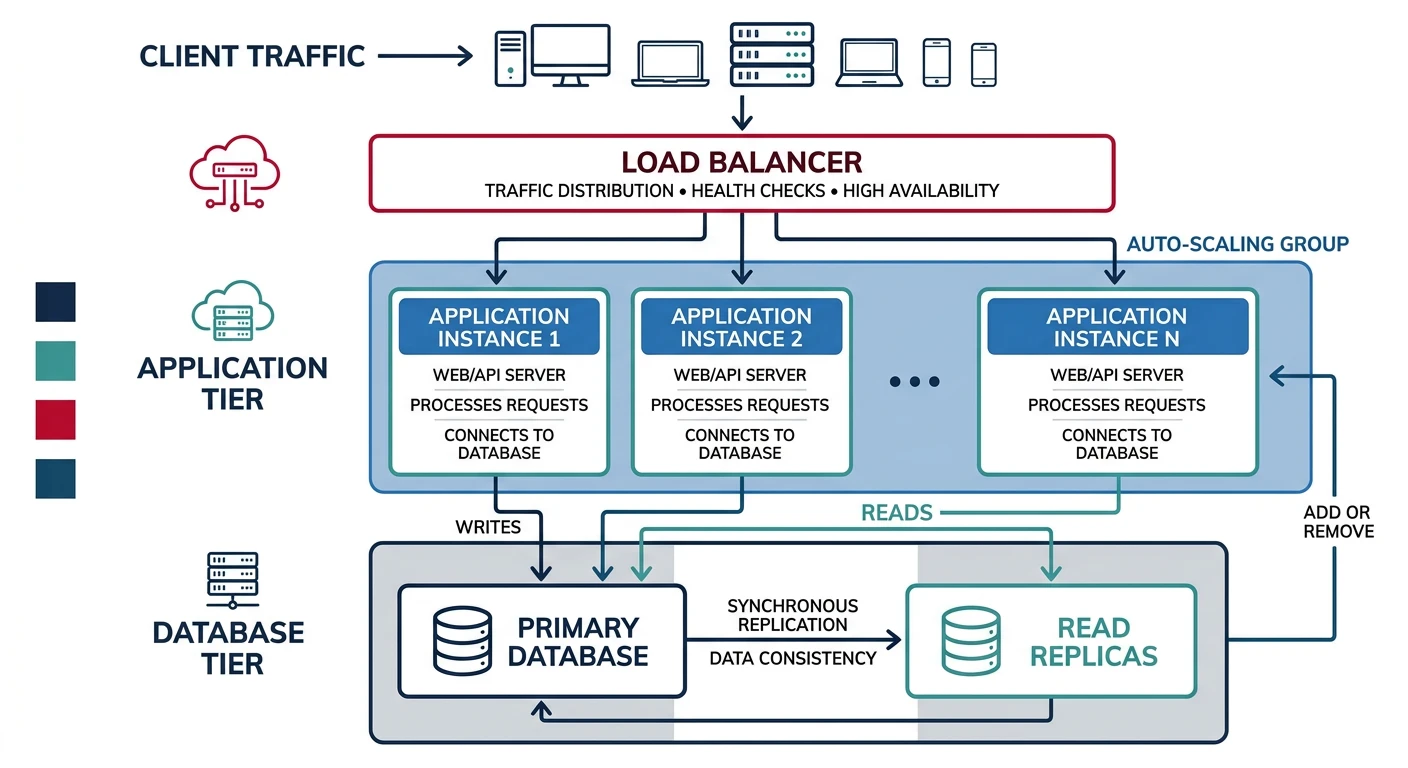
# Kubernetes HPA for auto-scaling
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: task-api-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: task-api
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
# Custom metric: requests per second
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: "1000"Practice Exercises
Exercise 1: Redis Caching
- Set up Redis caching middleware
- Add cache-control headers
- Implement cache invalidation on updates
Exercise 2: K6 Load Test Suite
- Write K6 load test for your API
- Define performance thresholds
- Run with different load profiles
Exercise 3: Tiered Rate Limiting
- Implement sliding window rate limiter
- Add subscription-based tiers
- Add rate limit headers and 429 responses