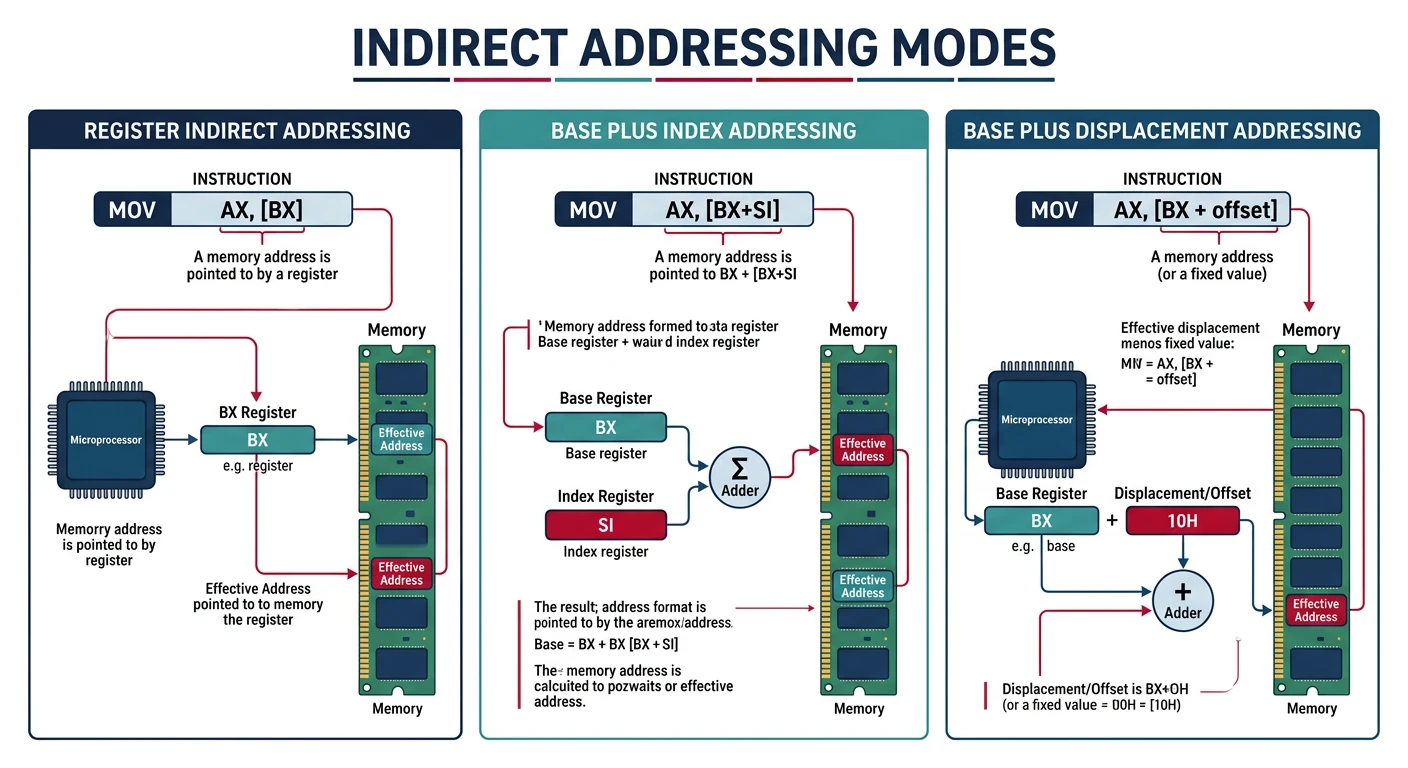
Key Concept: Addressing modes determine how the CPU calculates the location of operands. x86 offers rich addressing capabilities that enable efficient array access, struct navigation, and position-independent code.
Effective Address = Base + (Index × Scale) + Displacement
Where:
- Base: Any general-purpose register
- Index: Any GP register except RSP
- Scale: 1, 2, 4, or 8
- Displacement: 8, 16, or 32-bit signed constant
Immediate Addressing
mov rax, 42 ; Immediate value in instruction
mov rbx, 0xDEADBEEF ; Hex immediate
add rcx, 100 ; Add immediate to register
Register Addressing
mov rax, rbx ; Register to register
add rcx, rdx ; Both operands are registers
xor rax, rax ; Clear register (common idiom)
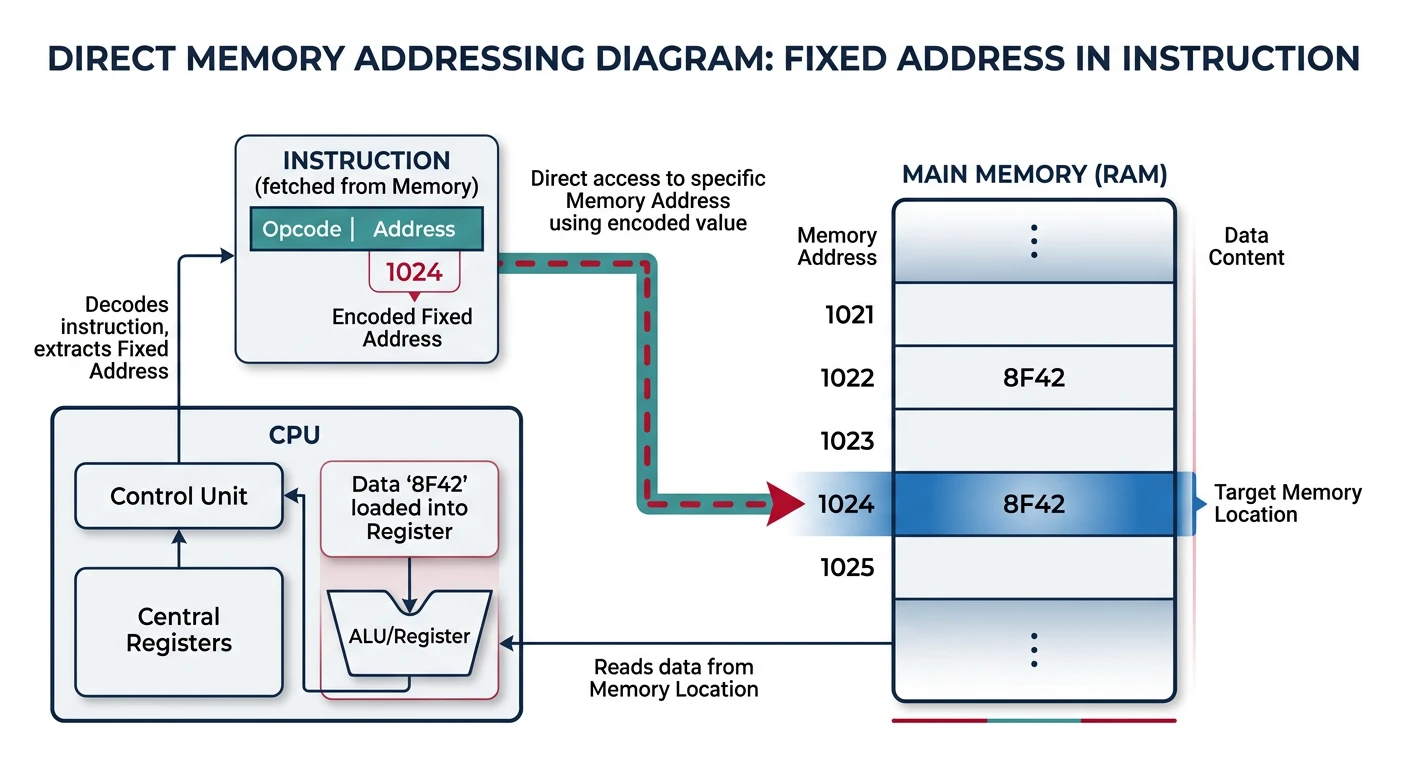
Direct Memory Addressing
Direct memory addressing uses a fixed address encoded directly in the instruction. Think of it like having a hardcoded street address—simple but inflexible.
Direct memory addressing — the operand address is encoded directly in the instruction, pointing to a fixed memory location.
section .data
my_var dq 42 ; 8-byte variable
buffer times 64 db 0 ; 64-byte buffer
section .text
; Direct addressing (32-bit mode style)
mov eax, [my_var] ; Load from fixed address
mov [buffer], bl ; Store byte at buffer
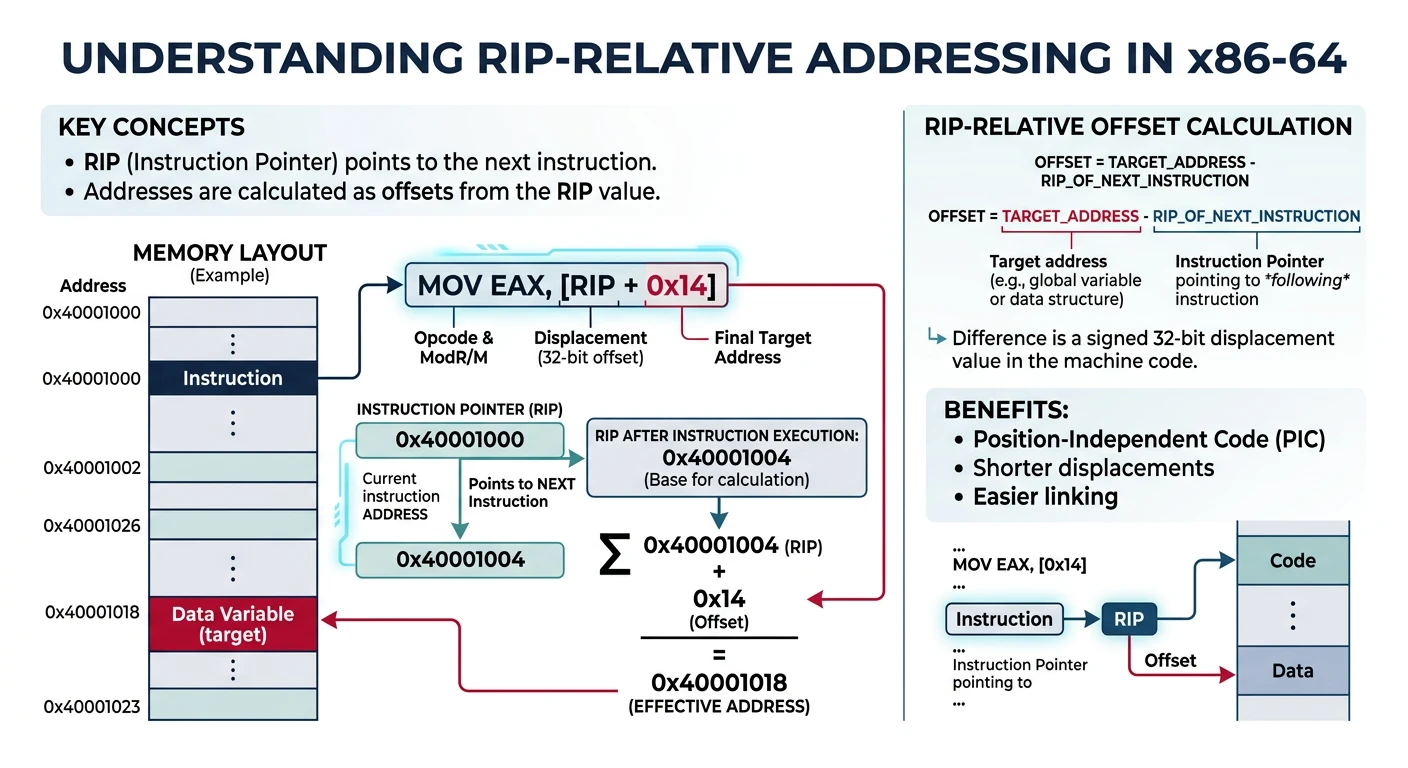
; In 64-bit mode, this becomes RIP-relative!
; Assembler converts [my_var] to [rip + offset_to_my_var]
64-bit Gotcha: In x86-64, "direct" addressing to labels compiles to RIP-relative. True absolute addresses require mov rax, QWORD [abs address] or using a register as base.
Real-World Use Case
section .data
; Global configuration values
debug_mode db 1
buffer_size dq 4096
error_count dd 0
section .text
global _start
_start:
; Check debug flag
cmp byte [debug_mode], 0
je .no_debug
; ... debug output ...
.no_debug:
; Increment error counter
inc dword [error_count]
; Exit
mov rax, 60
xor edi, edi
syscall
RIP-relative addressing in x86-64 — data is referenced as an offset from the current instruction pointer, enabling position-independent code.
Position-Independent Code: In 64-bit mode, RIP-relative addressing is the default for accessing global data, enabling position-independent executables (PIE).
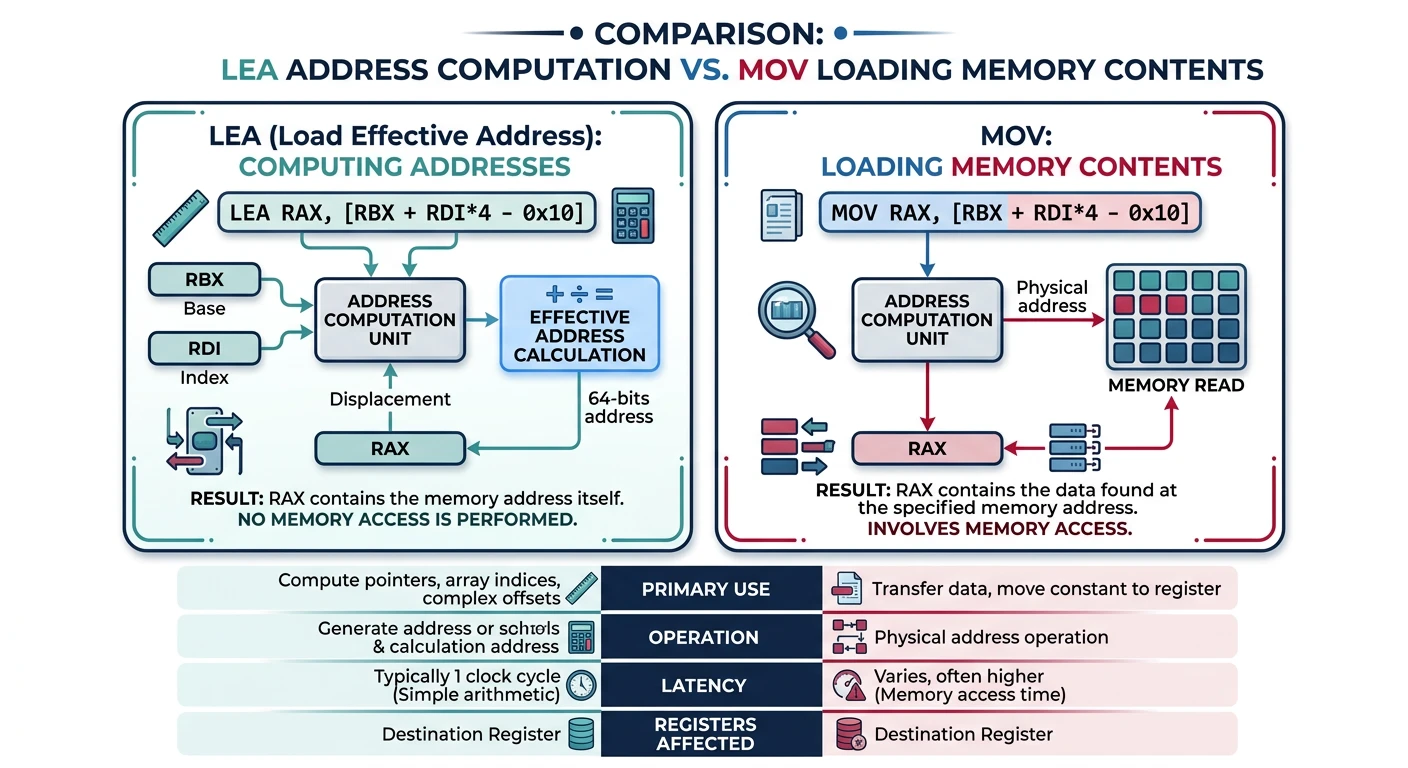
Load Effective Address computes an address but stores the address itself, not the memory contents. It's like getting directions to a restaurant instead of the food.
LEA vs MOV — LEA computes and stores the effective address itself, while MOV dereferences the address to load memory contents.
Key Insight: LEA doesn't access memory! It's a pure arithmetic operation that uses the address calculation hardware. This makes it perfect for fast multiply-add math.
Address Calculation Use
section .data
array dq 10, 20, 30, 40, 50
section .text
mov rcx, 3 ; index = 3
lea rax, [array + rcx*8] ; rax = address of array[3]
mov rbx, [rax] ; rbx = array[3] = 40
; Get address of struct field
; RDI points to struct, salary at offset 36
lea rsi, [rdi + 36] ; rsi = address of person->salary
Arithmetic "Trick"
LEA performs up to 2 adds and 1 shift in a single instruction—faster than separate operations:
Pro Tip: Use LEA when you need the result without affecting FLAGS, or when combining operations. Compilers often use LEA for x = a + b + constant patterns.
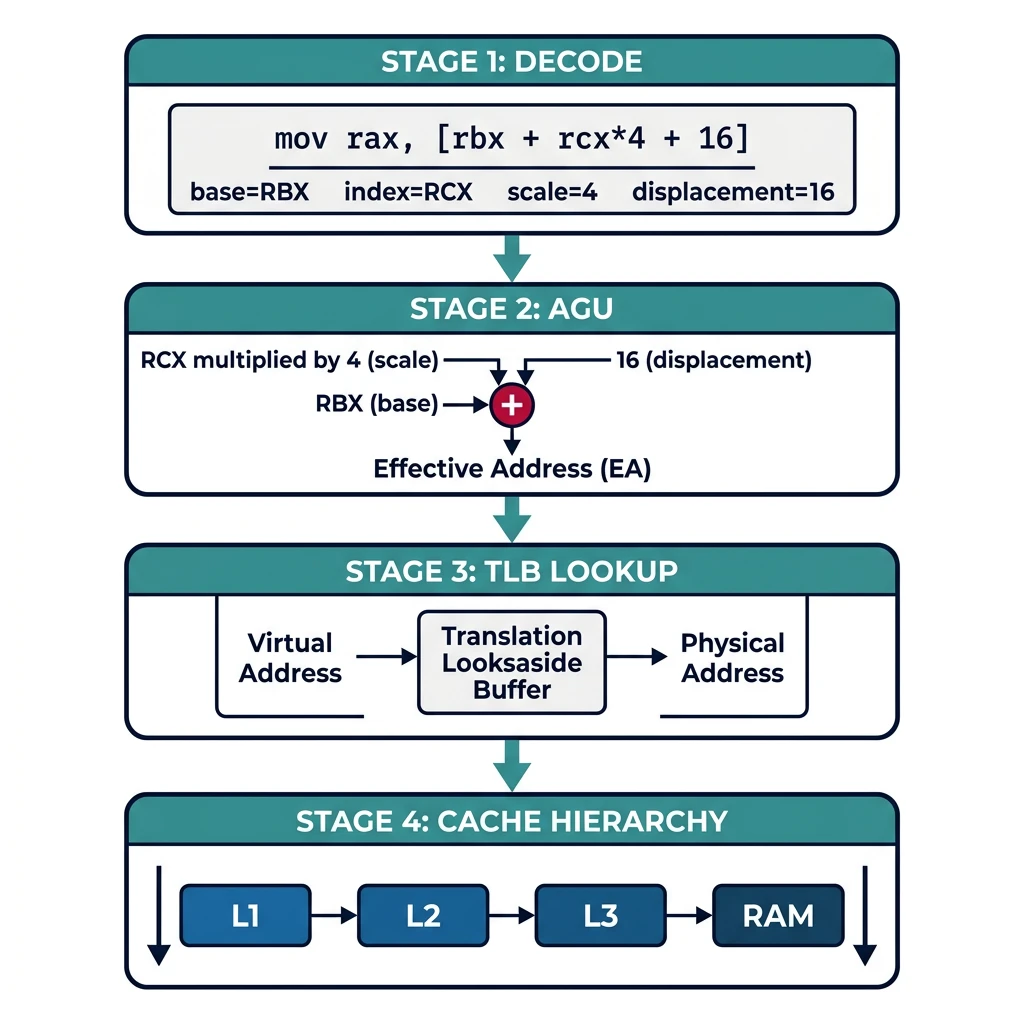
Effective Address Calculation
When the CPU decodes a memory operand, dedicated Address Generation Units (AGUs) compute the effective address in parallel with other operations.
Effective address calculation pipeline — the Address Generation Unit (AGU) computes the address, followed by TLB translation and cache lookup.