x86 Assembly Series Part 12: SIMD – SSE, AVX, AVX-512
February 6, 2026Wasil Zafar40 min read
Master SIMD (Single Instruction, Multiple Data) programming: SSE 128-bit vectors, AVX 256-bit operations, AVX-512 for maximum throughput, and practical use cases for parallel data processing.
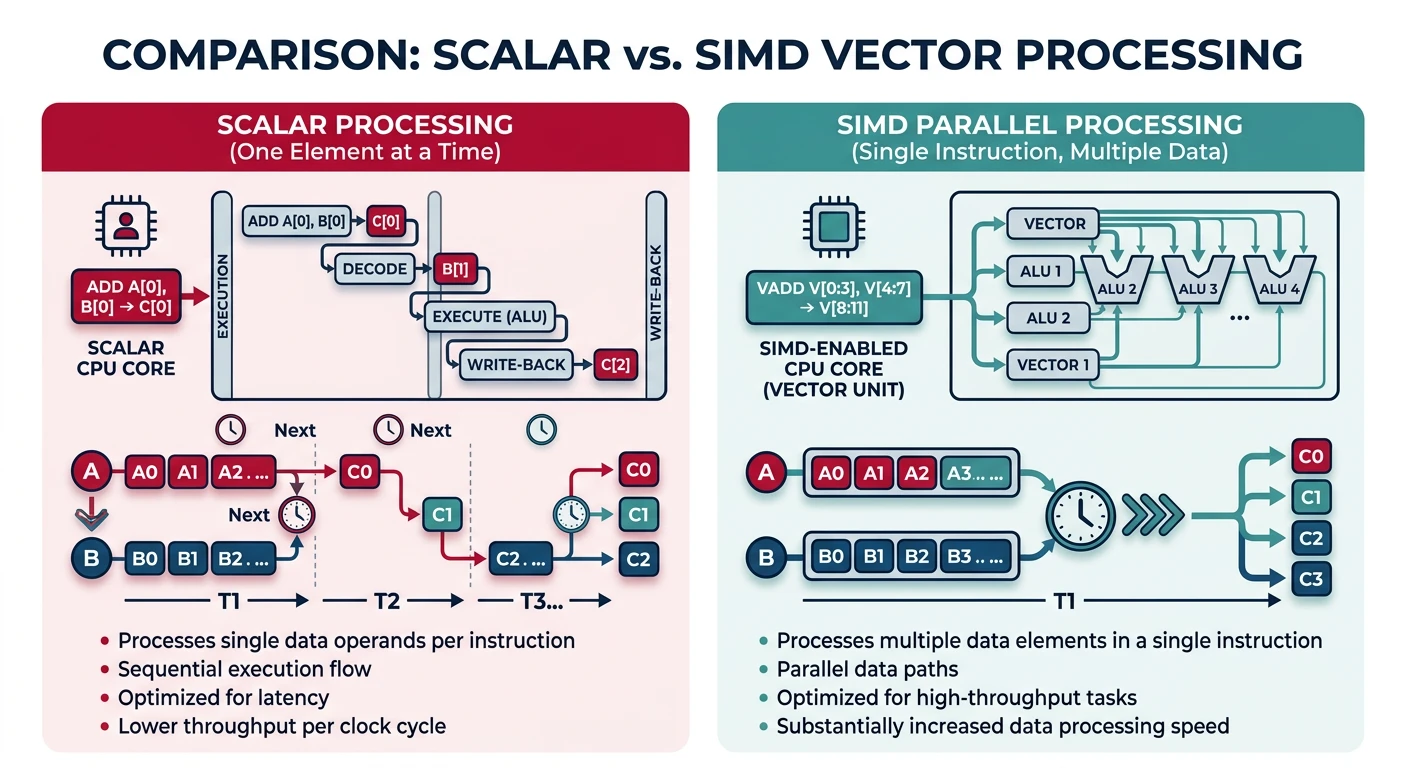
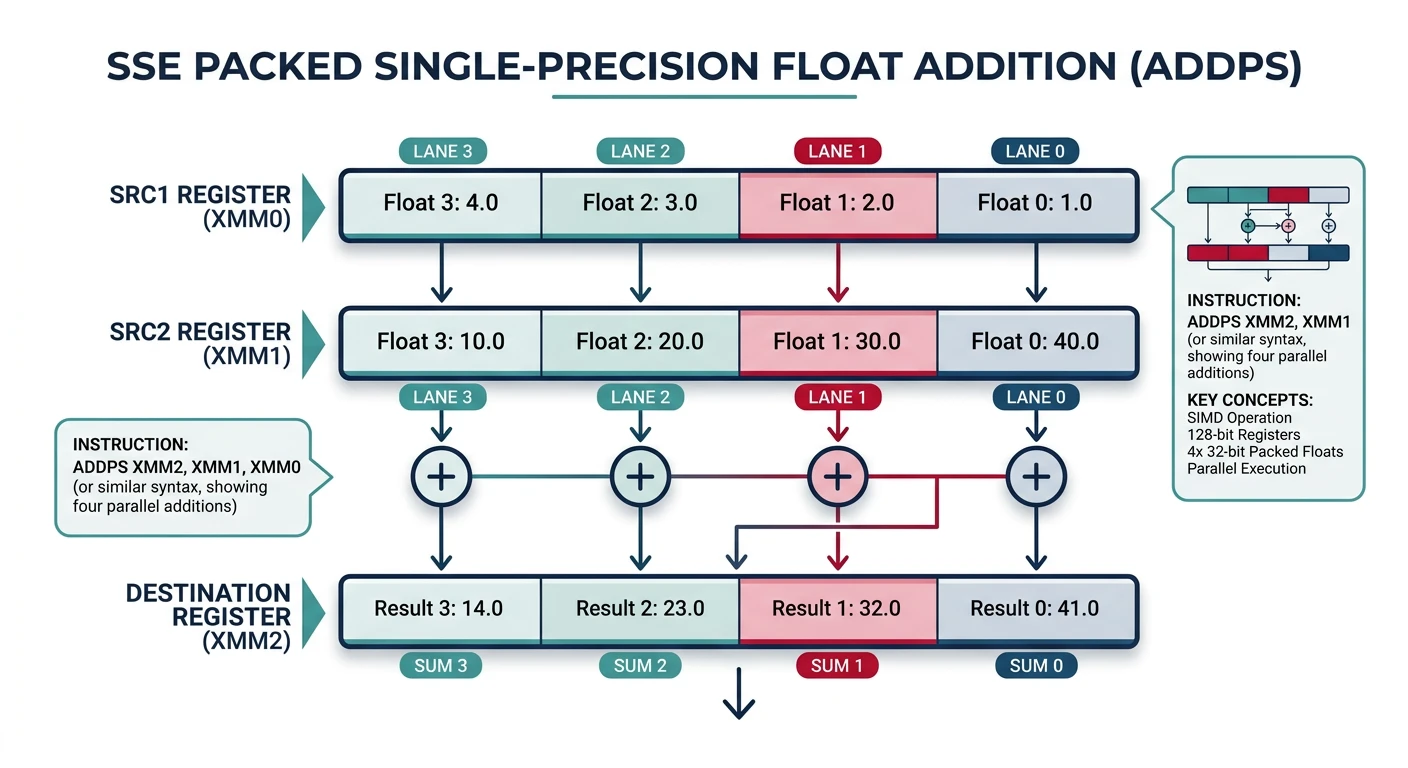
SIMD = Parallel Power: Process multiple data elements with a single instruction. Instead of adding 4 floats one at a time (4 instructions), add all 4 with ADDPS (1 instruction).
SIMD processes multiple data elements in parallel with a single instruction — 4× throughput for packed single-precision floats using SSE
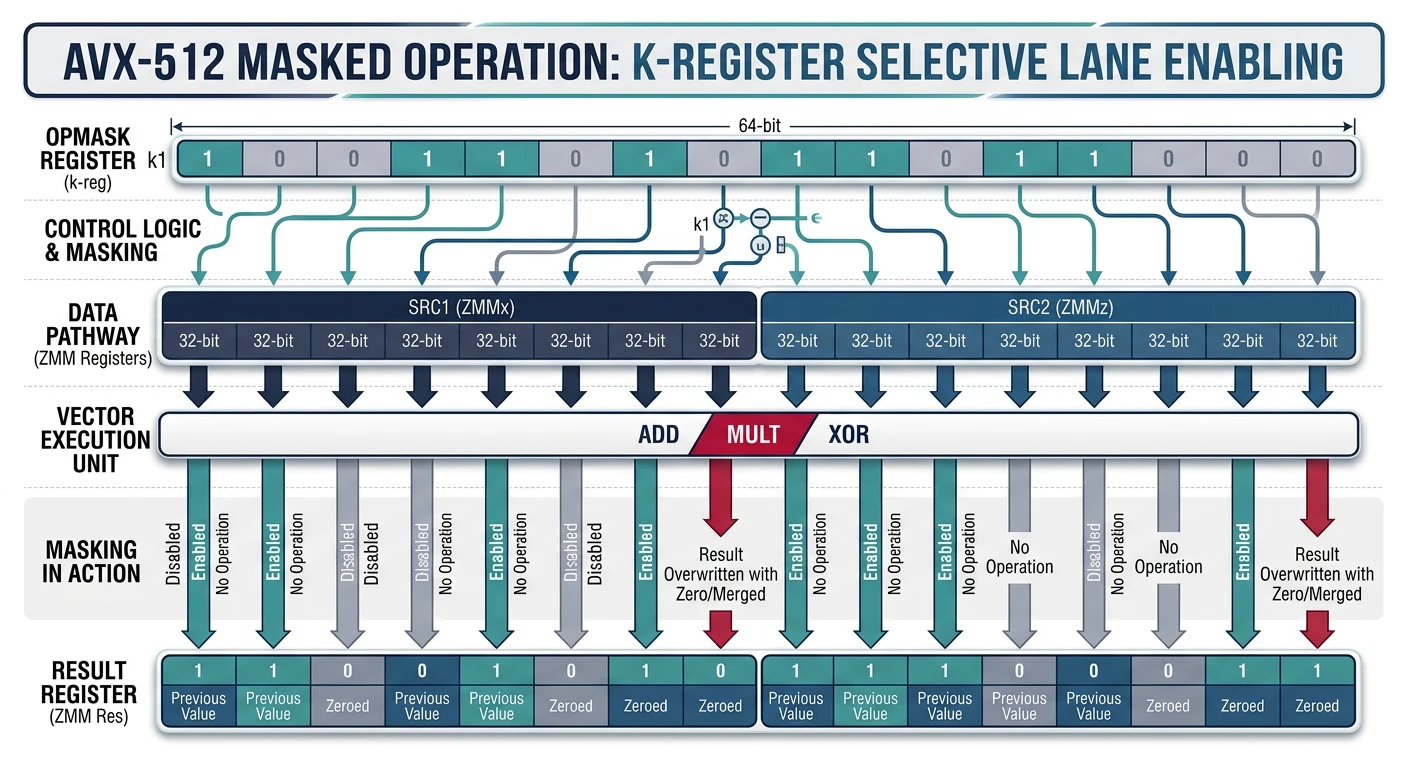
AVX-512 mask registers (k0–k7) enable per-lane predication — only lanes with corresponding mask bits set are written to the destination
; Load and operate on 16 floats at once
vmovaps zmm0, [array] ; Load 64 bytes (16 floats)
vaddps zmm0, zmm1, zmm2 ; ZMM0 = ZMM1 + ZMM2
; Masked operations - only process some lanes
kxnorw k1, k1, k1 ; k1 = all 1s (enable all lanes)
kmovw k2, eax ; k2 from integer mask
vaddps zmm0 {k2}, zmm1, zmm2 ; Add only where k2 bits are set
vaddps zmm0 {k2}{z}, zmm1, zmm2 ; Same, but zero masked lanes
; Broadcast (replicate scalar to all lanes)
vbroadcastss zmm0, [scalar] ; All 16 floats = scalar value
; Ternary logic (any 3-input boolean function!)
vpternlogd zmm0, zmm1, zmm2, 0xCA ; Complex bitwise operation
AVX-512 Feature Subsets
AVX-512 has many subsets. Check CPU support with CPUID:
AVX-512F: Foundation (512-bit ops, mask regs)
AVX-512VL: Vector Length (use AVX-512 features on XMM/YMM)
AVX-512BW: Byte and Word operations
AVX-512DQ: Doubleword and Quadword
AVX-512VNNI: Vector Neural Network Instructions
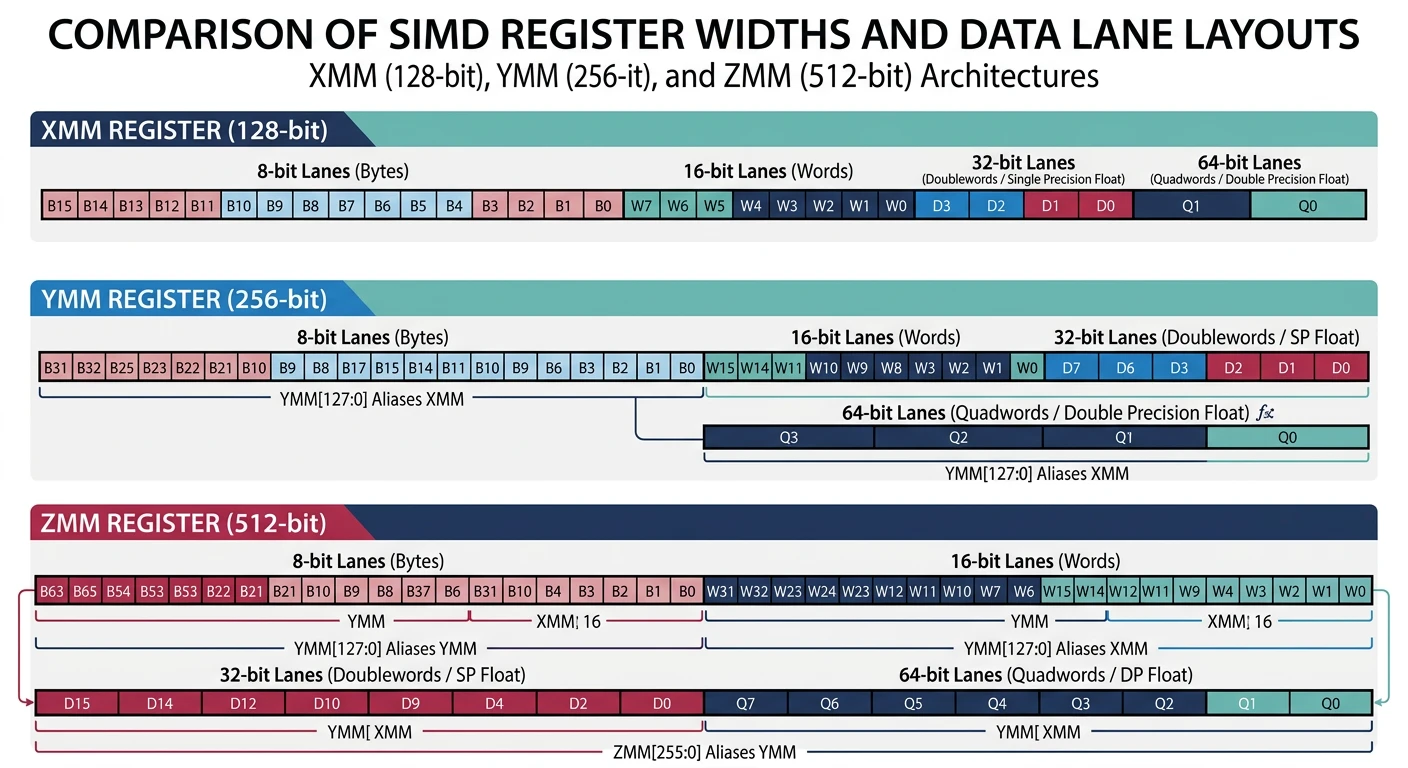
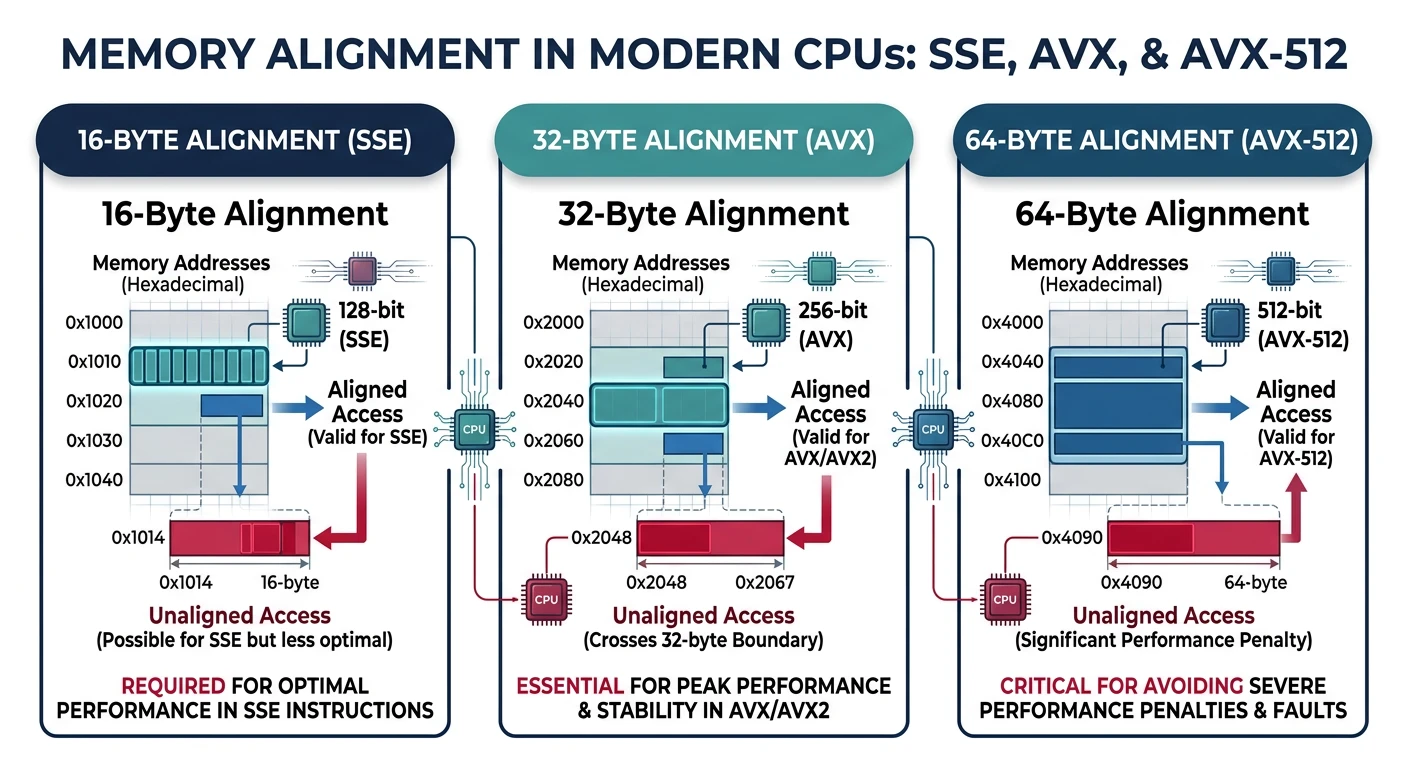
Memory Alignment
SIMD loads/stores have strict alignment requirements:
Aligned SIMD loads (MOVAPS/VMOVAPS) require addresses divisible by the register width — misaligned access causes a #GP fault
Instruction
Requires
Penalty for Misalign
movaps / movapd
16-byte aligned
#GP fault (crash!)
movups / movupd
Any
Slight performance hit
vmovaps ymm
32-byte aligned
#GP fault
vmovups ymm
Any
Performance hit
vmovaps zmm
64-byte aligned
#GP fault
section .data
align 16
sse_array: times 4 dd 1.0 ; 16-byte aligned for SSE
align 32
avx_array: times 8 dd 1.0 ; 32-byte aligned for AVX
align 64
avx512_array: times 16 dd 1.0 ; 64-byte aligned for AVX-512
section .bss
align 32
result: resd 8 ; Aligned output buffer
section .text
; Safe: aligned load
movaps xmm0, [sse_array] ; OK - 16-byte aligned
; Dangerous: unaligned load with aligned instruction
; movaps xmm0, [sse_array + 4] ; CRASH! Not 16-byte aligned
; Safe: use unaligned instruction
movups xmm0, [sse_array + 4] ; Works, slightly slower
Stack Alignment: Local arrays on the stack may not be naturally aligned. Use and rsp, -32 to force alignment, or explicitly align with sub rsp; and rsp.
Practical Examples
Array Sum (SSE)
; Sum an array of floats using SSE
; rdi = array pointer, rsi = count (multiple of 4)
; Returns sum in xmm0
array_sum_sse:
xorps xmm0, xmm0 ; Accumulator = 0
.loop:
cmp rsi, 0
jle .done
addps xmm0, [rdi] ; Add 4 floats
add rdi, 16 ; Advance pointer
sub rsi, 4 ; Decrement count
jmp .loop
.done:
; Horizontal add: xmm0 = [a, b, c, d]
movhlps xmm1, xmm0 ; xmm1 = [c, d, ?, ?]
addps xmm0, xmm1 ; xmm0 = [a+c, b+d, ...]
movaps xmm1, xmm0
shufps xmm1, xmm1, 0x55 ; xmm1 = [b+d, b+d, ...]
addss xmm0, xmm1 ; Final sum in xmm0[0]
ret