IEEE 754 Representation
IEEE 754: The standard for floating-point arithmetic. A float consists of sign bit, exponent, and mantissa (fraction). Understanding this format is essential for debugging FP code.
x86 Assembly Mastery
Your 25-step learning path • Currently on Step 12
Development Environment, Tooling & Workflow
IDEs, debuggers, build tools, workflow setupAssembly Language Fundamentals & Toolchain Setup
Syntax basics, assemblers, linkers, object filesx86 CPU Architecture Overview
Instruction pipeline, execution units, microarchitectureRegisters – Complete Deep Dive
GPRs, segment, control, flags, MSRsInstruction Encoding & Binary Layout
Opcode bytes, ModR/M, SIB, prefixes, encoding schemesNASM Syntax, Directives & Macros
Sections, labels, EQU, %macro, conditional assemblyComplete Assembler Comparison
NASM vs MASM vs GAS vs FASM, syntax differencesMemory Addressing Modes
Direct, indirect, indexed, base+displacement, RIP-relativeStack Internals & Calling Conventions
Push/pop, stack frames, cdecl, System V ABI, fastcallControl Flow & Procedures
Jumps, loops, conditionals, CALL/RET, function designInteger, Bitwise & Arithmetic Operations
ADD, SUB, MUL, DIV, AND, OR, XOR, shifts, rotates12
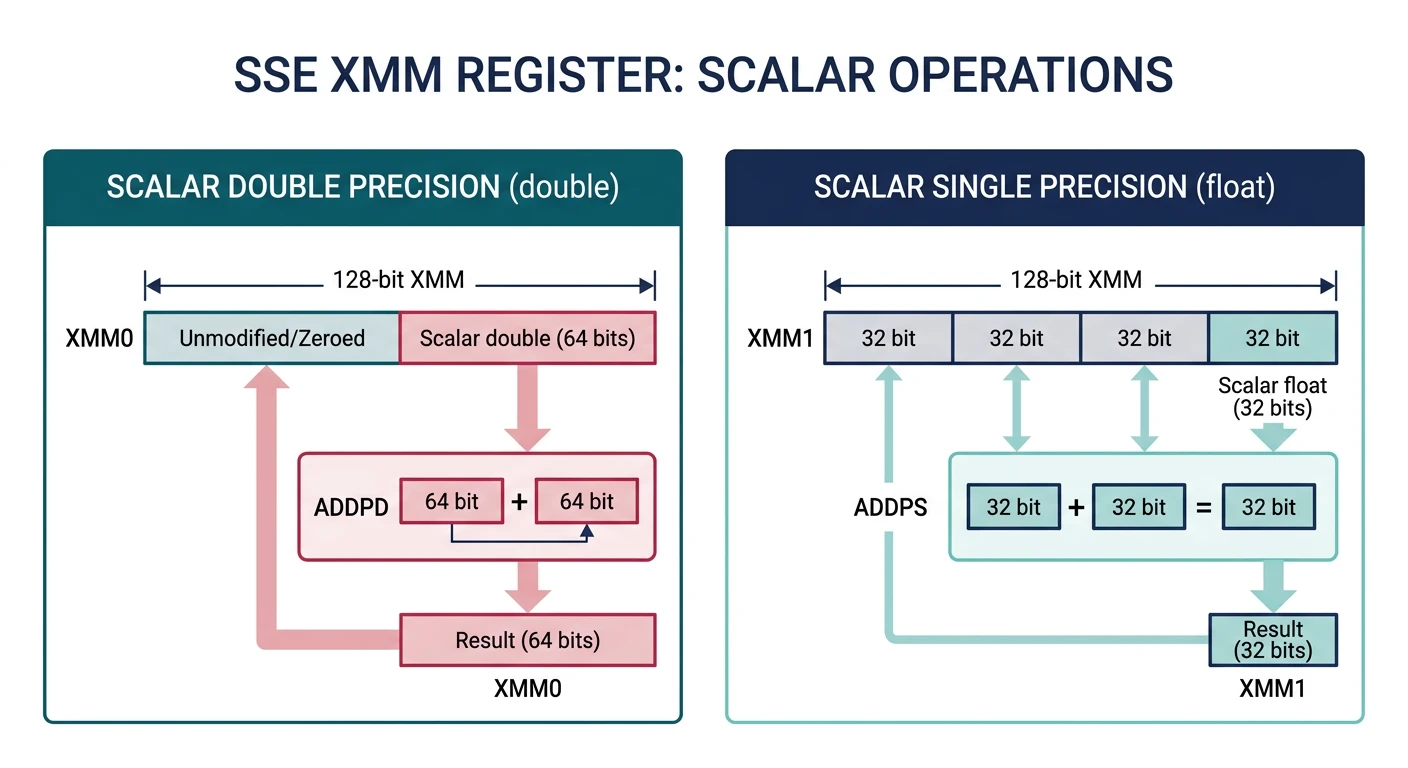
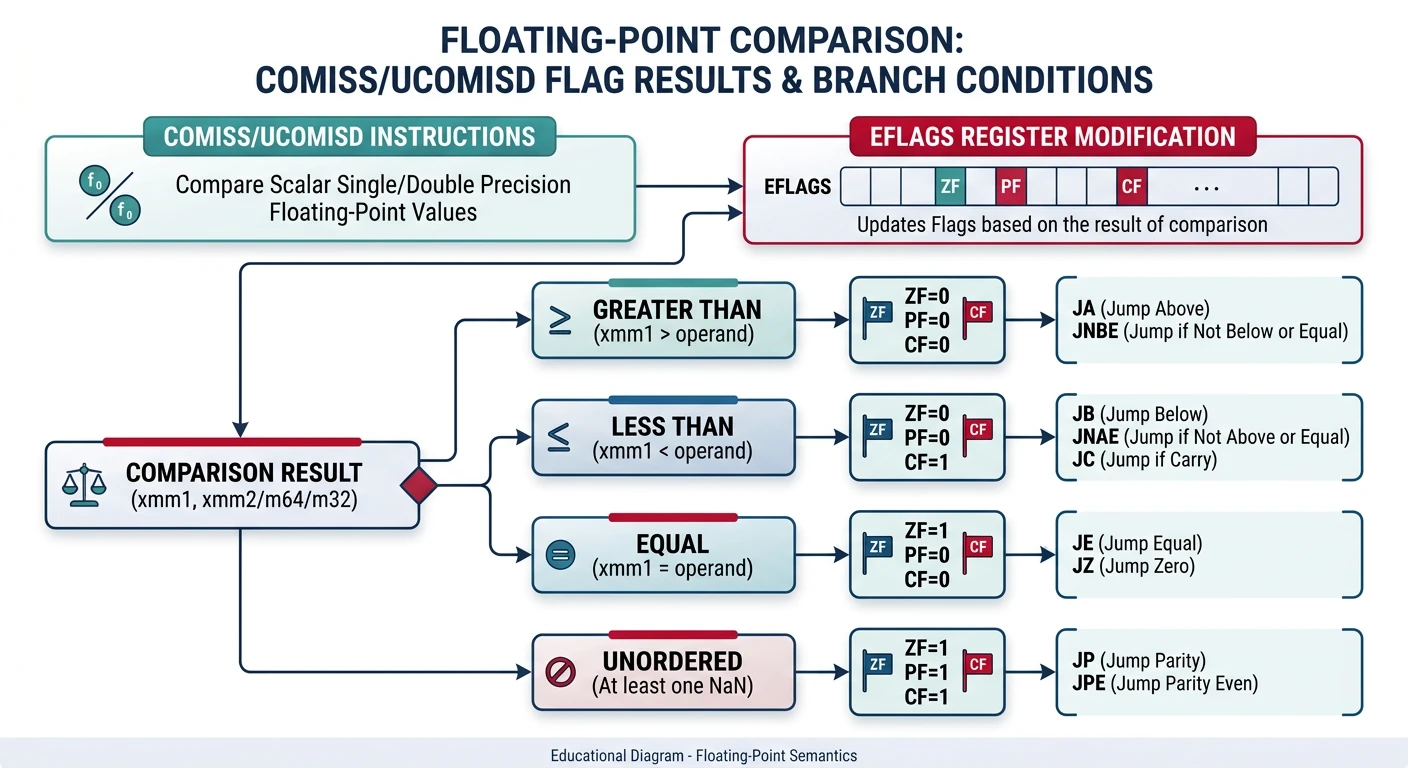
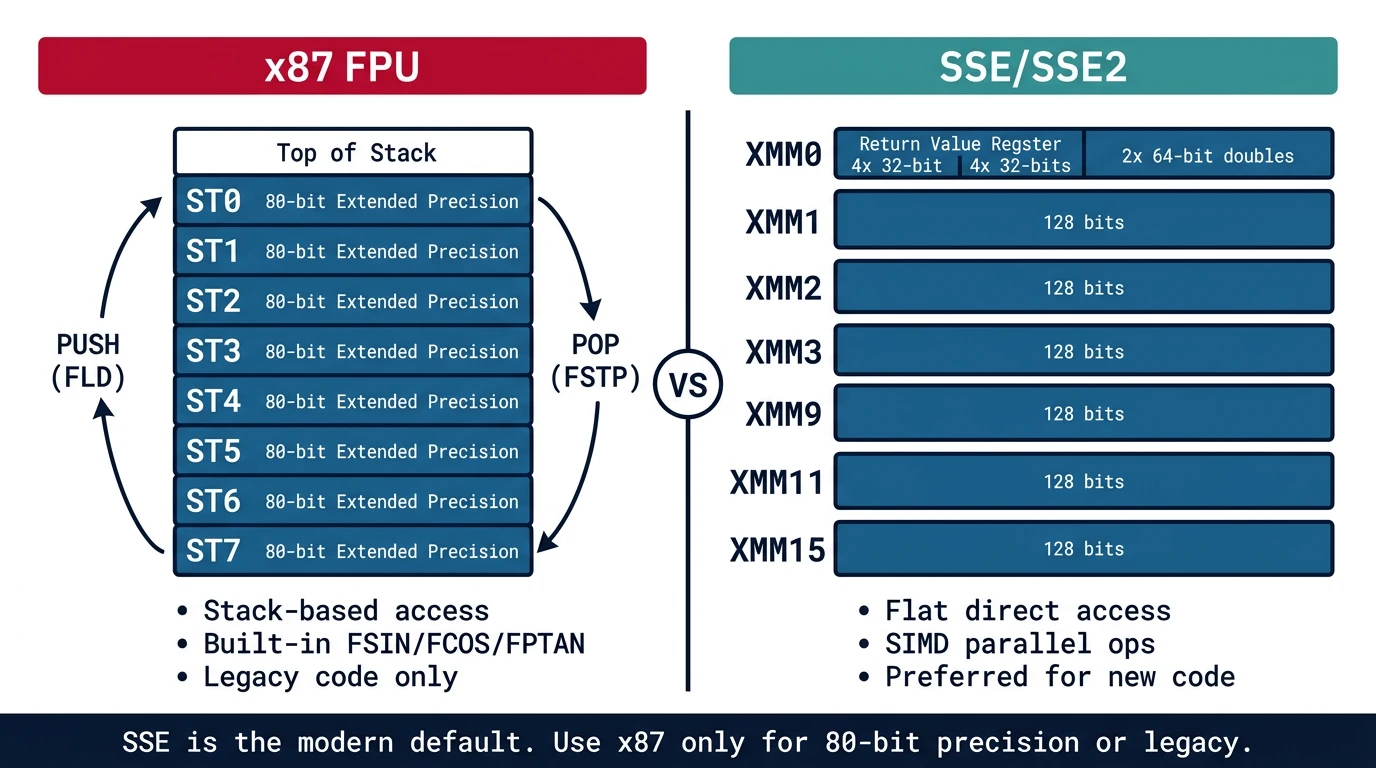
Floating Point & SIMD Foundations
x87 FPU, IEEE 754, SSE scalar, precision control13
SIMD, Vectorization & Performance
SSE, AVX, AVX-512, data-parallel processing14
System Calls, Interrupts & Privilege Transitions
INT, SYSCALL, IDT, ring transitions, exception handling15
Debugging & Reverse Engineering
GDB, breakpoints, disassembly, binary analysis, IDA16
Linking, Relocation & Loader Behavior
ELF/PE formats, symbol resolution, dynamic linking, GOT/PLT17
x86-64 Long Mode & Advanced Features
64-bit extensions, RIP addressing, canonical addresses18
Assembly + C/C++ Interoperability
Inline assembly, calling C from ASM, ABI compliance19
Memory Protection & Security Concepts
DEP, ASLR, stack canaries, ROP, mitigations20
Bootloaders & Bare-Metal Programming
BIOS/UEFI, MBR, real mode, protected mode transition21
Kernel-Level Assembly
Context switching, interrupt handlers, TSS, GDT/LDT22
Complete Emulator & Simulator Guide
QEMU, Bochs, instruction-level simulation, debugging VMs23
Advanced Optimization & CPU Internals
Pipeline hazards, branch prediction, cache optimization, ILP24
Real-World Assembly Projects
Shellcode, drivers, cryptography, signal processing25
Assembly Mastery Capstone
Final project, comprehensive review, advanced techniques
Single Precision (32-bit float)
IEEE 754 Single Precision
| Sign (1 bit) | Exponent (8 bits) | Mantissa (23 bits) |
| 31 | 30-23 | 22-0 |
Value = (-1)^S × 1.M × 2^(E-127)
Examples:
1.0 = 0x3F800000 = 0 01111111 00000000000000000000000
-2.0 = 0xC0000000 = 1 10000000 00000000000000000000000
3.14 ≈ 0x4048F5C3Double Precision (64-bit double)
IEEE 754 Double Precision
| Sign (1 bit) | Exponent (11 bits) | Mantissa (52 bits) |
| 63 | 62-52 | 51-0 |
Value = (-1)^S × 1.M × 2^(E-1023)
Examples:
1.0 = 0x3FF0000000000000
-2.0 = 0xC000000000000000
3.14159265358979 ≈ 0x400921FB54442D18
Special Values:
+∞ = 0x7FF0000000000000 (exponent all 1s, mantissa 0)
-∞ = 0xFFF0000000000000
NaN = 0x7FF8000000000000 (exponent all 1s, mantissa non-zero)Precision Comparison
| Type | Bits | Significant Digits | Range |
|---|---|---|---|
| Float (single) | 32 | ~7 | ±1.18×10⁻³⁸ to ±3.4×10³⁸ |
| Double | 64 | ~15-16 | ±2.23×10⁻³⁰⁸ to ±1.8×10³⁰⁸ |
| x87 Extended | 80 | ~19 | ±3.65×10⁻⁴⁹³² to ±1.18×10⁴⁹³² |