Introduction
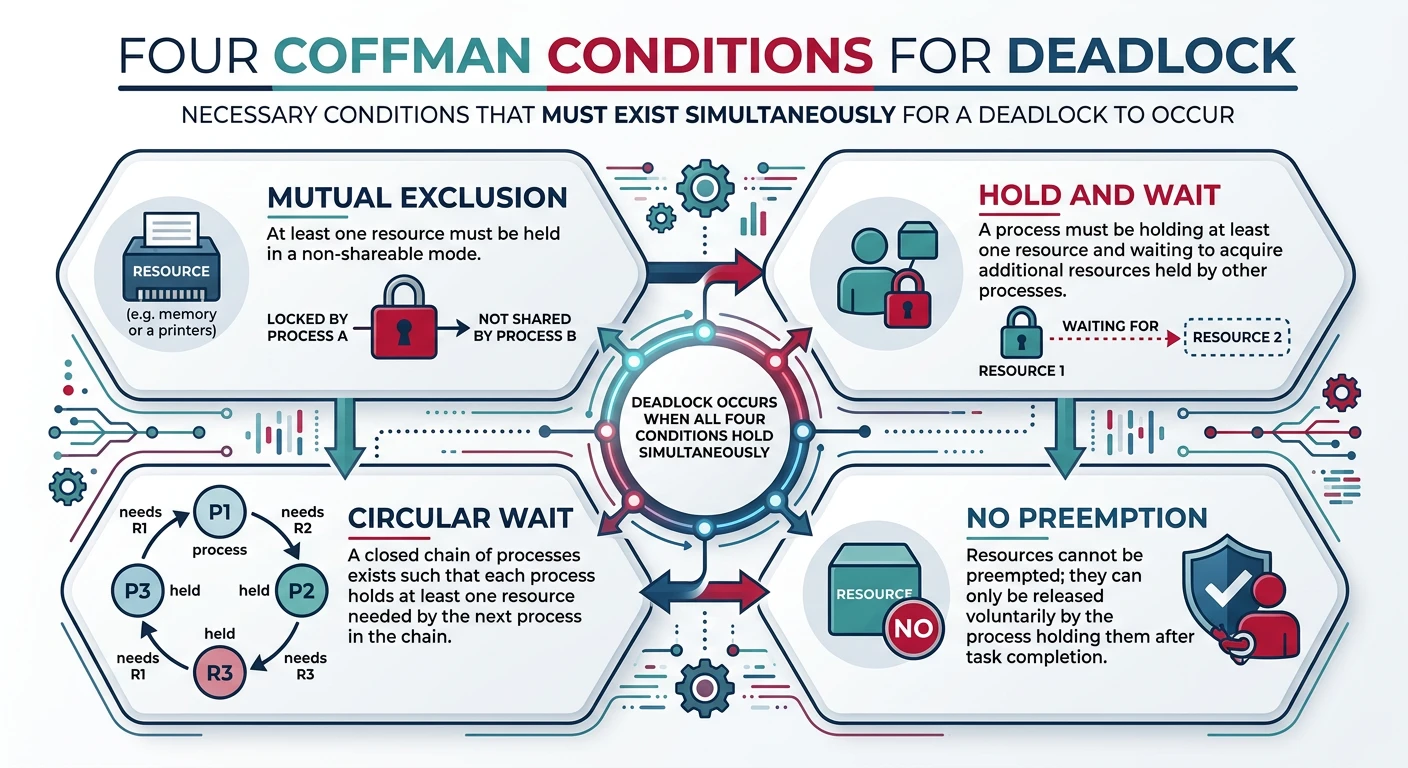
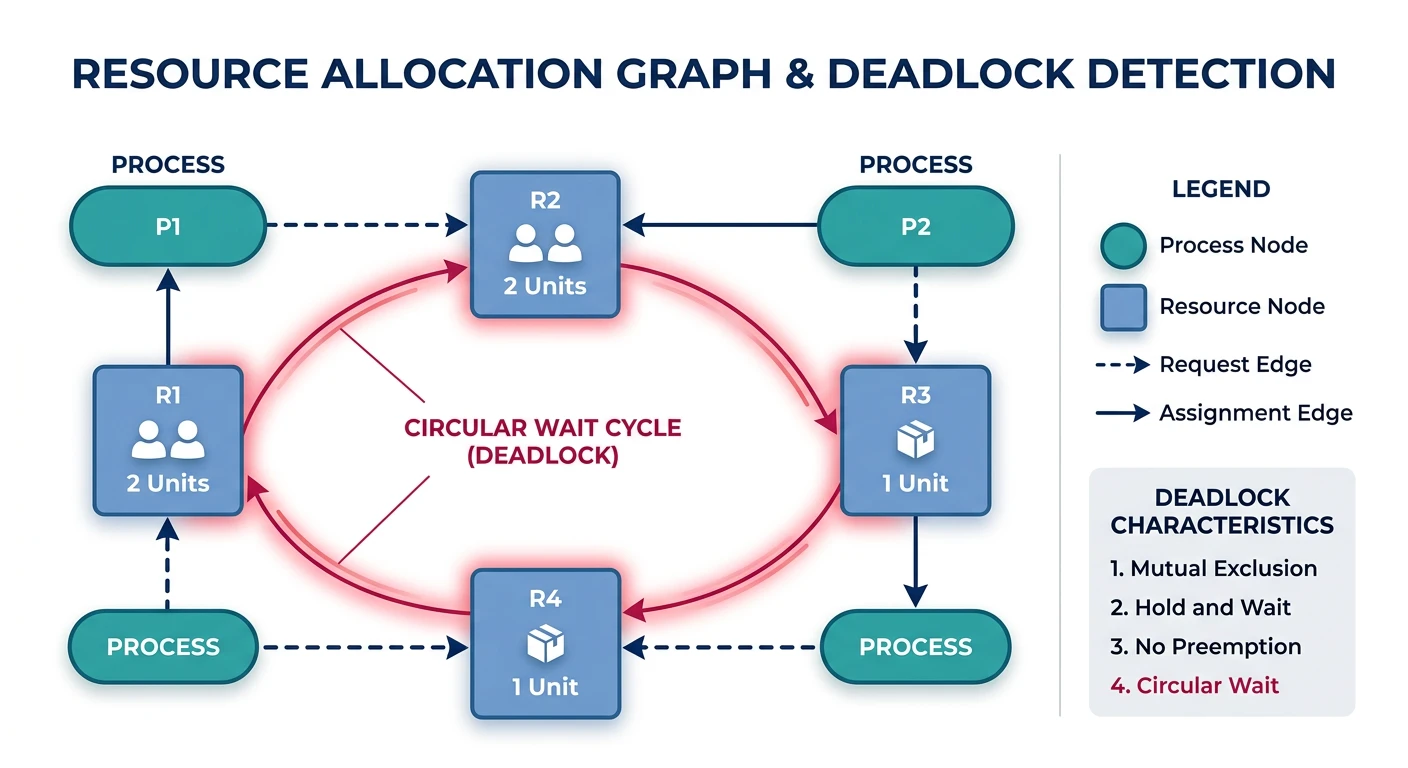
A deadlock occurs when processes are waiting for resources held by each other, creating a circular dependency that prevents any progress. Understanding deadlocks is crucial for building reliable systems.
Series Context: This is Part 13 of 24 in the Computer Architecture & Operating Systems Mastery series. Building on synchronization, we now explore the dangerous deadlock condition.
Computer Architecture & OS Mastery
Your 24-step learning path • Currently on Step 13
1
Part 1: Foundations of Computer Systems
System overview, architectures, OS role2
Digital Logic & CPU Building Blocks
Gates, registers, datapath, microarchitecture3
Instruction Set Architecture (ISA)
RISC vs CISC, instruction formats, addressing4
Assembly Language & Machine Code
Registers, stack, calling conventions5
Assemblers, Linkers & Loaders
Object files, ELF, dynamic linking6
Compilers & Program Translation
Lexing, parsing, code generation7
CPU Execution & Pipelining
Fetch-decode-execute, hazards, prediction8
OS Architecture & Kernel Design
Monolithic, microkernel, system calls9
Processes & Program Execution
Process lifecycle, PCB, fork/exec10
Threads & Concurrency
Threading models, pthreads, race conditions11
CPU Scheduling Algorithms
FCFS, RR, CFS, real-time scheduling12
Synchronization & Coordination
Locks, semaphores, classic problems13
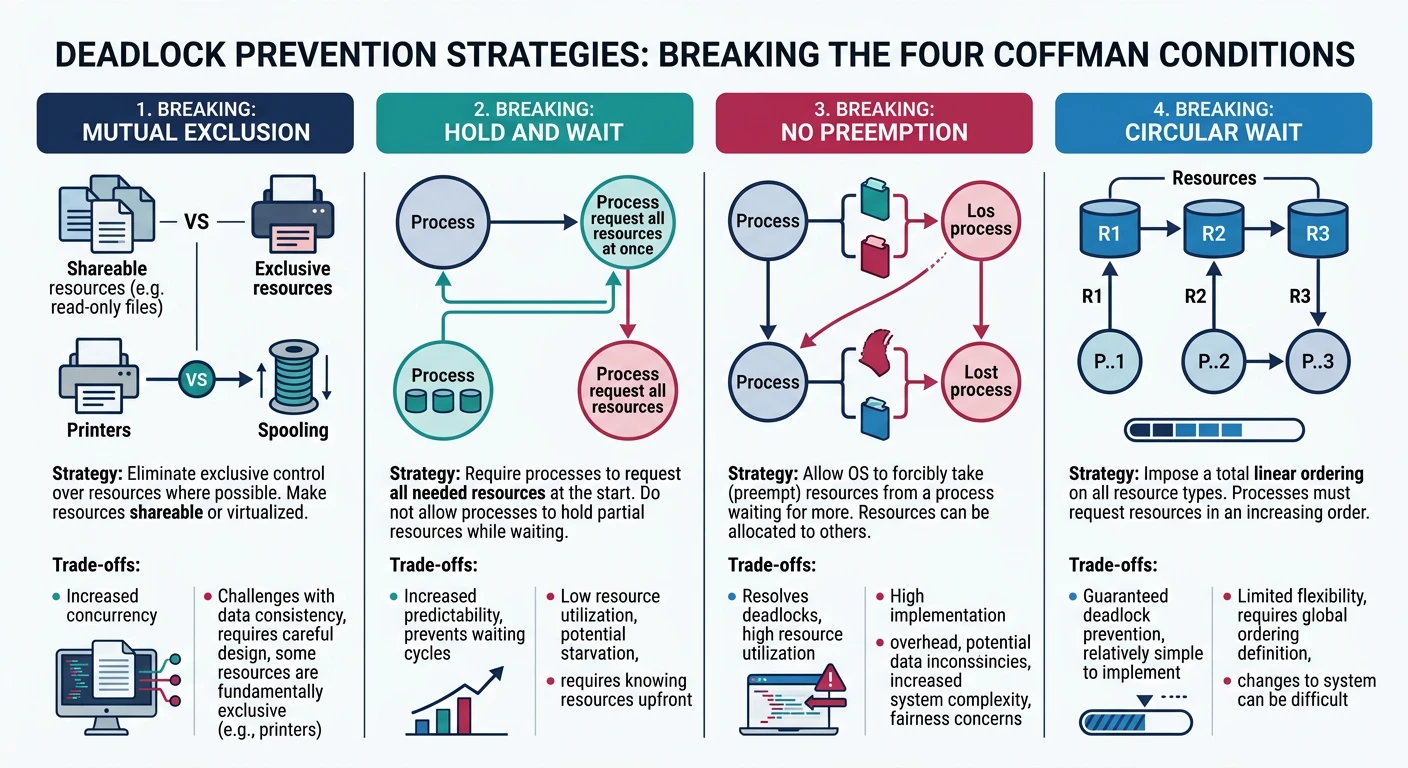
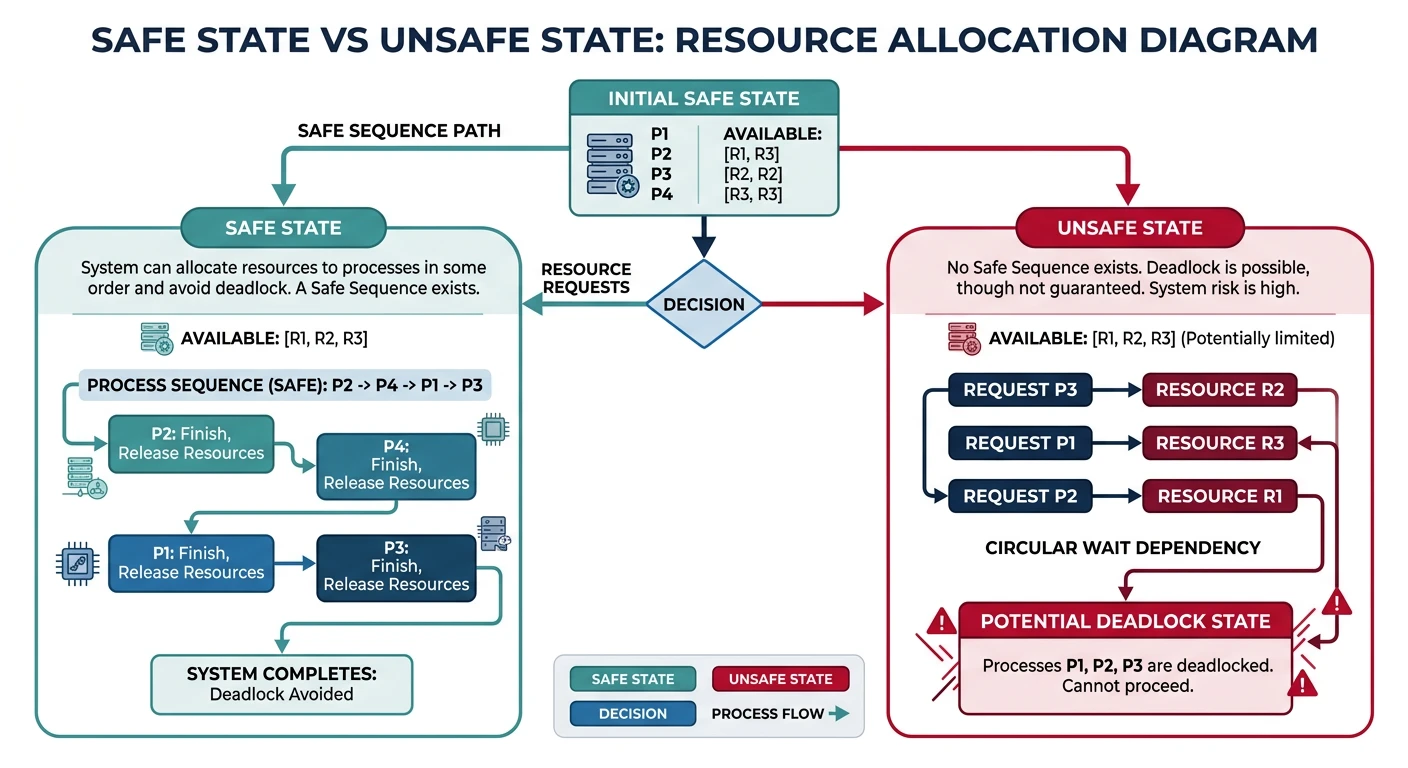
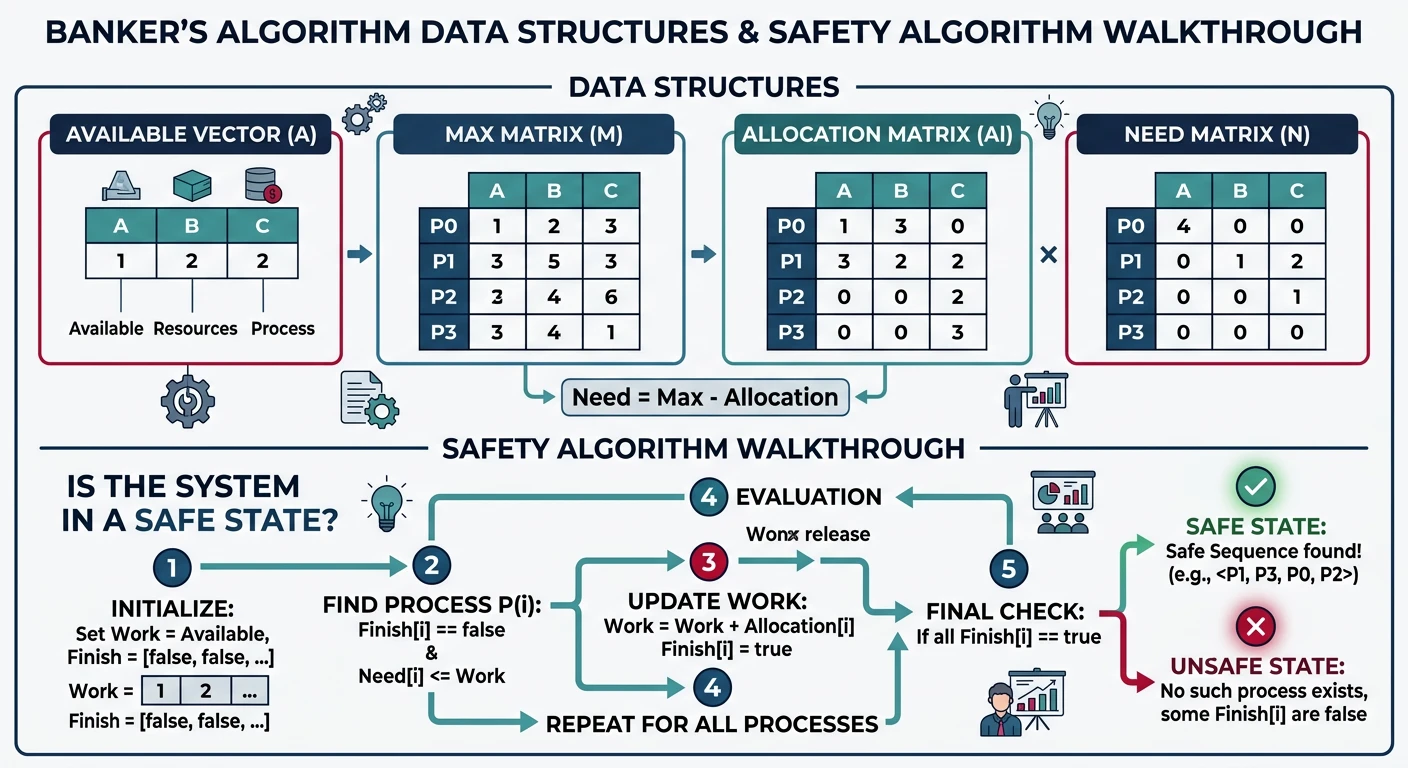
Deadlocks & Prevention
Coffman conditions, Banker's algorithm14
Memory Hierarchy & Cache
L1/L2/L3, cache coherence, NUMA15
Memory Management Fundamentals
Address spaces, fragmentation, allocation16
Virtual Memory & Paging
Page tables, TLB, demand paging17
File Systems & Storage
Inodes, journaling, ext4, NTFS18
I/O Systems & Device Drivers
Interrupts, DMA, disk scheduling19
Multiprocessor Systems
SMP, NUMA, cache coherence20
OS Security & Protection
Privilege levels, ASLR, sandboxing21
Virtualization & Containers
Hypervisors, namespaces, cgroups22
Advanced Kernel Internals
Linux subsystems, kernel debugging23
Case Studies
Linux vs Windows vs macOS24
Capstone Projects
Shell, thread pool, paging simulator
The Deadlock Problem: Two cars meet on a narrow bridge. Neither can proceed because each is waiting for the other to back up. This is deadlock—and it happens in computer systems too!