We use cookies to enhance your browsing experience, serve personalized content, and analyze our traffic.
By clicking "Accept All", you consent to our use of cookies. See our
Privacy Policy
for more information.
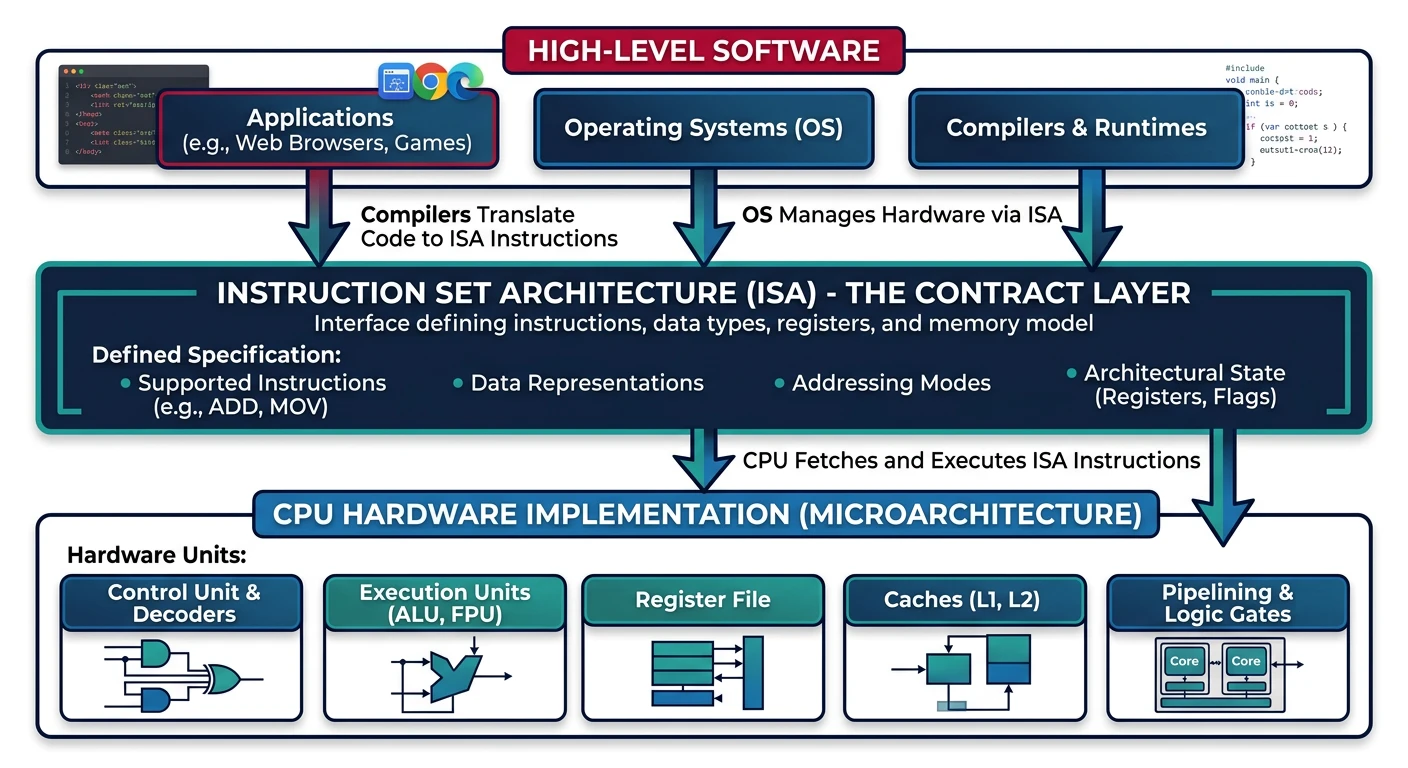
The Instruction Set Architecture (ISA) defines the interface between software and hardware—it specifies what instructions a processor can execute and how those instructions are encoded.
The ISA defines the interface contract between software and hardware
Series Context: This is Part 3 of 24 in the Computer Architecture & Operating Systems Mastery series. Building on digital logic foundations, we now explore how processors understand and execute instructions.
An ISA is like a contract between hardware and software. It specifies what the processor can do, but not how it's implemented. This abstraction allows software to run on different microarchitectures that share the same ISA.
The ISA as a Contract
Key Concept
Think of the ISA like a restaurant menu:
ISA (Menu) — Lists what dishes (instructions) are available
Microarchitecture (Kitchen) — How dishes are actually prepared
Software (Customer) — Orders from the menu without knowing kitchen details
Intel Core i9 and AMD Ryzen both implement x86-64 (same menu), but have very different "kitchens" inside!
What Does an ISA Define?
Component
What It Specifies
Example
Instructions
Operations the CPU can perform
ADD, SUB, MOV, JMP, CALL
Registers
Number, size, and purpose of registers
x86-64: 16 general-purpose 64-bit registers
Data Types
Supported data formats
8/16/32/64-bit integers, floats
Addressing Modes
How operands are accessed
Immediate, register, direct, indexed
Memory Model
How memory is organized and accessed
Byte-addressable, little-endian
I/O Model
How devices are accessed
Memory-mapped I/O vs port I/O
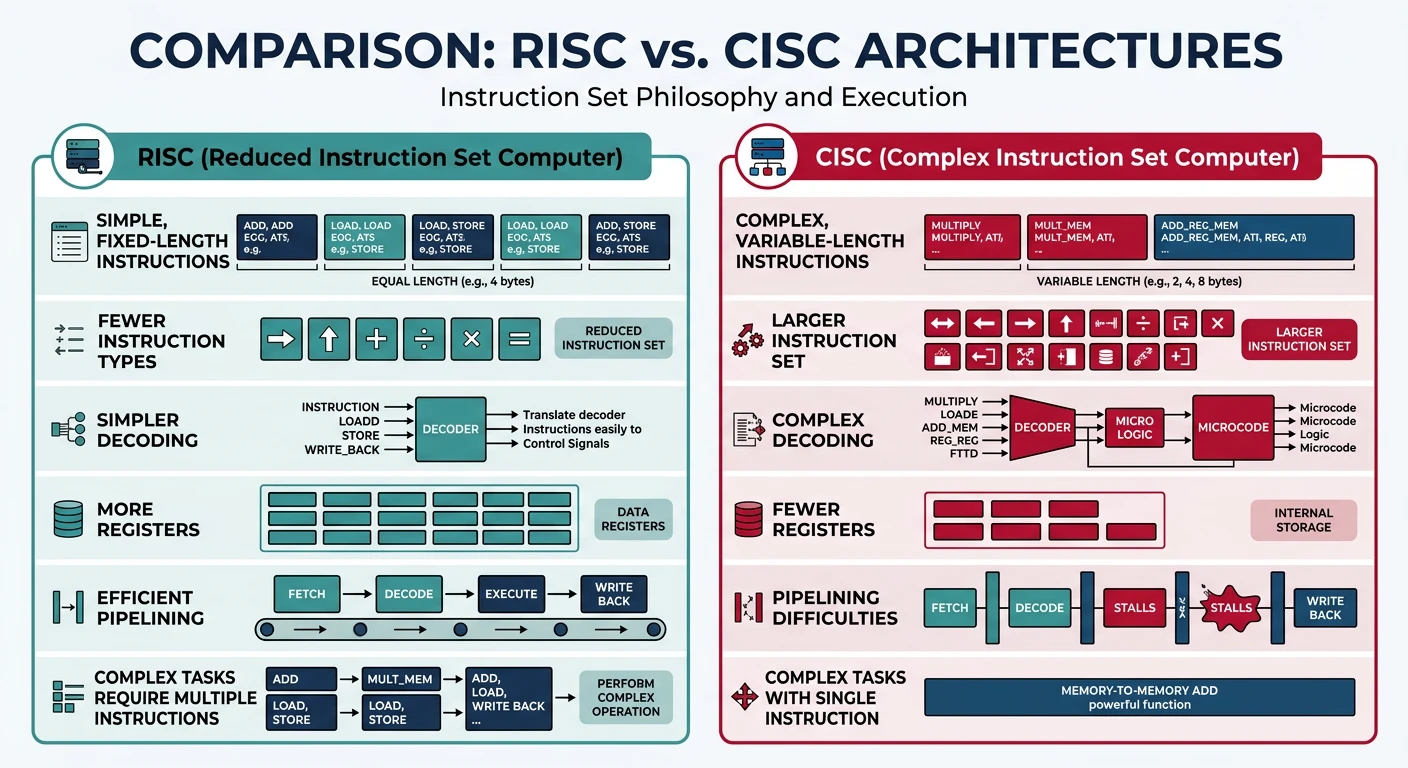
RISC vs CISC
The two major ISA design philosophies are RISC (Reduced Instruction Set Computer) and CISC (Complex Instruction Set Computer). They represent fundamentally different approaches to instruction design.
RISC vs CISC: contrasting instruction set design philosophies
RISC Philosophy
RISC follows the principle: "Keep instructions simple, let the compiler optimize."
RISC Core Principles:
Simple, uniform instructions that execute in one cycle
Large register file (32+ general-purpose registers)
Hardwired control unit (faster but less flexible)
RISC Example: ARM Assembly
Adding two numbers from memory:
; Load first number from memory into R1
LDR R1, [R0] ; R0 points to first number
; Load second number into R2
LDR R2, [R0, #4] ; Next memory location
; Add them
ADD R3, R1, R2 ; R3 = R1 + R2
; Store result back to memory
STR R3, [R0, #8] ; Store at third location
Four simple instructions, each does ONE thing!
RISC Examples in the Real World
ARM — Smartphones (iPhone, Android), Apple M1/M2/M3 chips, Raspberry Pi
RISC-V — Open-source ISA, gaining traction in IoT and academia
MIPS — Network routers, PlayStation 1/2, Nintendo 64
PowerPC — PlayStation 3, Xbox 360, older Macs
CISC Philosophy
CISC follows the principle: "Build powerful instructions, reduce code size."
CISC Core Principles:
Complex instructions that do multiple operations
Variable instruction length (1-15+ bytes for x86)
Instructions can directly access memory
Fewer registers (x86 originally had just 8)
Microprogrammed control unit (flexible but potentially slower)
CISC Example: x86 Assembly
Same operation—adding two numbers:
; Single instruction does load + add + store!
ADD DWORD PTR [result], [number1] ; Not actually valid x86, but shows the idea
; Real x86 code:
MOV EAX, [number1] ; Load first number
ADD EAX, [number2] ; Add second directly from memory!
MOV [result], EAX ; Store result
Three instructions, but ADD reads from memory directly!
Modern Convergence
Today, the RISC/CISC distinction has blurred significantly:
Modern CPU Reality:
┌────────────────────────────────────────────────────────────────┐
│ Modern x86 CPU (Intel/AMD) │
│ │
│ ┌───────────────┐ ┌──────────────────────────────────┐ │
│ │ x86 ISA │ │ RISC-like Core │ │
│ │ (CISC) │ ──► │ • Fixed-length micro-ops │ │
│ │ Frontend │ │ • Out-of-order execution │ │
│ └───────────────┘ │ • Large register file │ │
│ │ • Superscalar pipeline │ │
│ Complex x86 └──────────────────────────────────┘ │
│ instructions get │
│ decoded into simple │
│ RISC-like micro-ops │
└────────────────────────────────────────────────────────────────┘
Result: x86 ISA compatibility + RISC-like internal performance!
Key Insight: Modern Intel and AMD processors are essentially RISC internally—they translate x86 CISC instructions into simple micro-operations (μops) that execute on a RISC-like core. This gives the best of both worlds: x86 compatibility plus high performance!
RISC vs CISC Comparison
Aspect
RISC
CISC
Instruction Count
~50-150 instructions
~1000+ instructions
Instruction Length
Fixed (32 bits typical)
Variable (1-15 bytes)
Memory Access
Only via LOAD/STORE
Most instructions can access memory
Registers
32+ general-purpose
8-16 general-purpose
Cycles/Instruction
~1 (design goal)
Variable (1-many)
Code Density
Lower (more instructions)
Higher (fewer, powerful instructions)
Compiler Complexity
More complex (must optimize)
Less complex
Power Efficiency
Generally better
Generally worse
Examples
ARM, RISC-V, MIPS
x86, x86-64
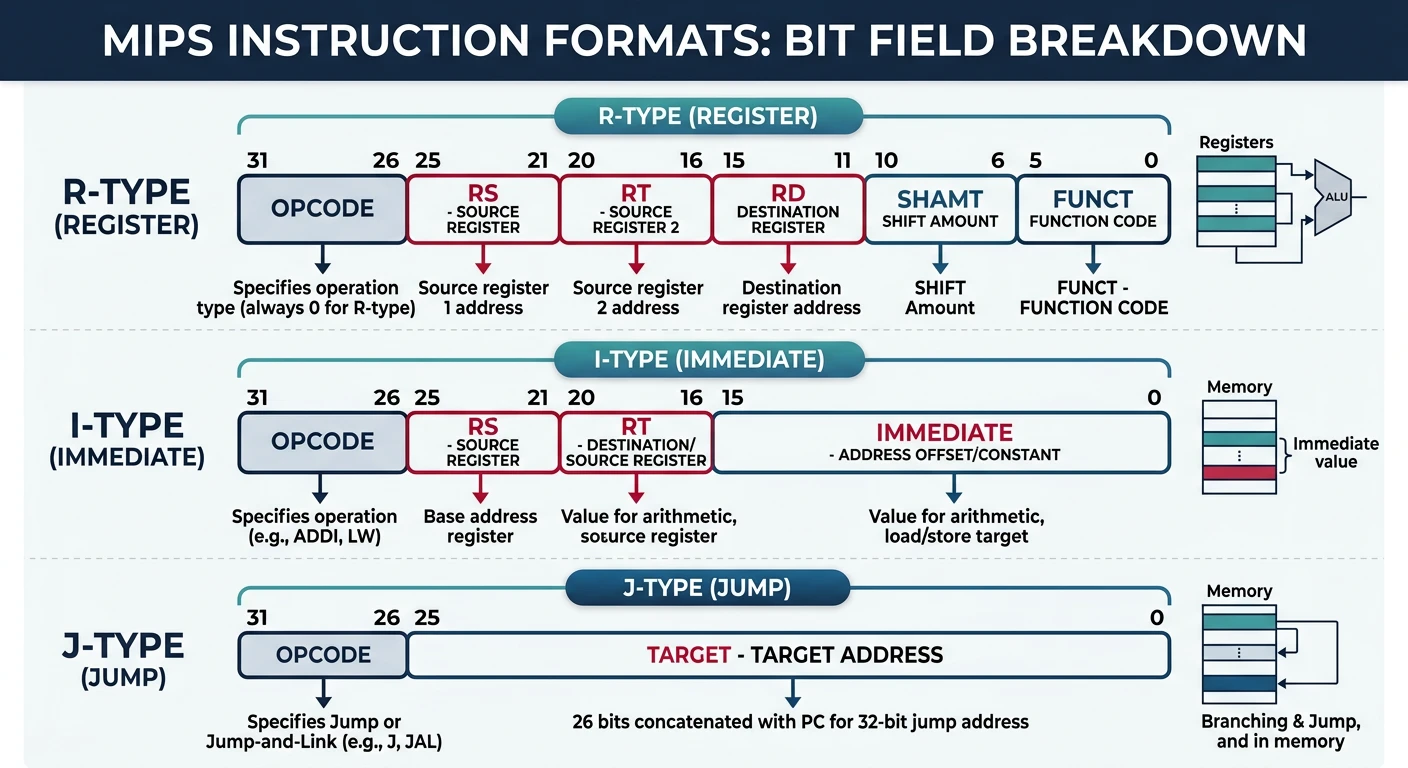
Instruction Formats
Instructions must be encoded into binary so the CPU can decode and execute them. The instruction format defines how bits are arranged to represent opcode, operands, and addressing information.
MIPS instruction format bit fields: R-type, I-type, and J-type encodings
Fixed-Length Instructions (RISC)
RISC architectures typically use fixed-length instructions, making decoding simpler and faster.
Why Fixed Length Matters: With fixed-length instructions, the CPU knows exactly where each instruction begins. It can fetch and decode multiple instructions in parallel without first figuring out their lengths!
Variable-Length Instructions (CISC)
x86 uses variable-length instructions from 1 to 15 bytes, prioritizing code density over decode simplicity.
ModR/M byte: ┌───┬─────┬─────┐
│Mod│ Reg │ R/M │
│2b │ 3b │ 3b │
└───┴─────┴─────┘
Mod = 00: Memory operand, no displacement
Mod = 01: Memory + 8-bit displacement
Mod = 10: Memory + 32-bit displacement
Mod = 11: Register operand
Reg = Which register is used
R/M = Which register or memory formula
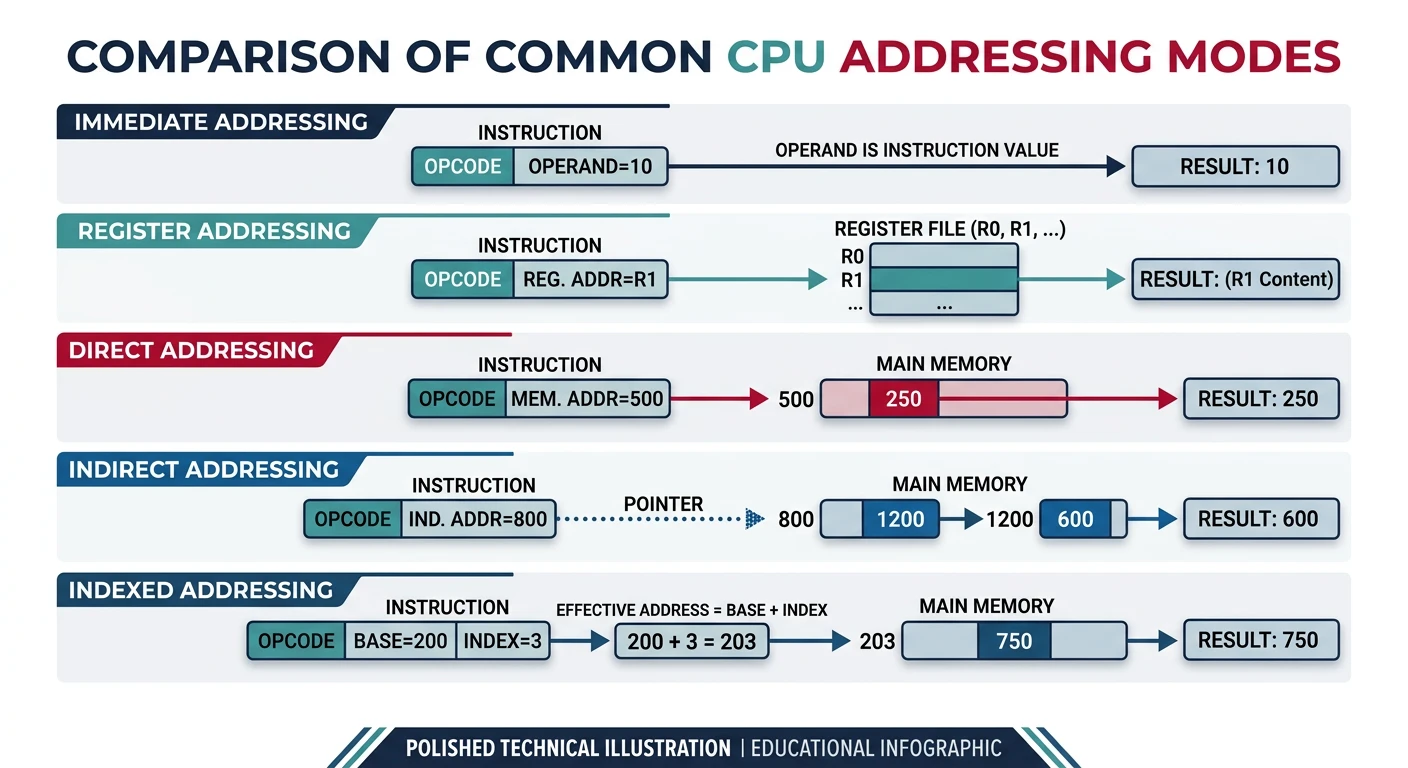
Addressing modes specify how the CPU finds the operands for an instruction. Different modes provide flexibility for accessing data in registers, memory, or as constants.
How different addressing modes locate operand data in registers and memory
Immediate Addressing
The operand value is encoded directly in the instruction itself.
Immediate Addressing:
MOV EAX, 42 ; Put the value 42 into EAX
; The 42 is stored IN the instruction itself
Instruction encoding: B8 2A 00 00 00
│ └──────────┘
│ └── 42 in little-endian (0x0000002A)
└── Opcode for MOV EAX, imm32
Advantages:
✓ Fast—no memory access needed for the operand
✓ Simple to decode
Disadvantages:
✗ Limited by instruction size (can't store large values)
✗ Value is fixed at compile time
Register Addressing
The operand is in a CPU register.
Register Addressing:
ADD EAX, EBX ; EAX = EAX + EBX
; Both operands are in registers
CPU Operation:
1. Read value from EAX
2. Read value from EBX
3. Add them
4. Write result to EAX
Advantages:
✓ Fastest access (registers are on-chip)
✓ No memory access needed
Disadvantages:
✗ Limited registers available
✗ Must load data from memory first
Memory Addressing
x86 provides rich memory addressing modes:
Memory Addressing Modes in x86:
1. Direct (Absolute):
MOV EAX, [0x1000] ; Load from address 0x1000
2. Register Indirect:
MOV EAX, [EBX] ; Load from address in EBX
3. Base + Displacement:
MOV EAX, [EBX + 8] ; Load from (EBX + 8)
; Great for struct fields!
4. Base + Index:
MOV EAX, [EBX + ECX] ; Load from (EBX + ECX)
5. Base + Index + Displacement:
MOV EAX, [EBX + ECX + 8] ; Load from (EBX + ECX + 8)
6. Scaled Index:
MOV EAX, [EBX + ECX*4] ; Load from (EBX + ECX×4)
; Perfect for array access!
; EBX = array base, ECX = index
; ×4 because each int is 4 bytes
7. Full Form (SIB addressing):
MOV EAX, [EBX + ECX*4 + 100] ; base + index×scale + disp
Formula: Address = Base + (Index × Scale) + Displacement
Scale can be: 1, 2, 4, or 8
Array Access in Action
Practical Example
Accessing array[i] where array is at 0x1000:
C code: int value = array[i];
// If array base is in EBX, index i is in ECX
// Each int is 4 bytes
MOV EAX, [EBX + ECX*4] ; EAX = array[i]
; Address = EBX + ECX × 4
Example with array at 0x1000, i = 3:
Address = 0x1000 + 3 × 4 = 0x100C
Memory: 0x1000 0x1004 0x1008 0x100C 0x1010
│ │ │ │ │
arr[0] arr[1] arr[2] arr[3] arr[4]
└── We read this!
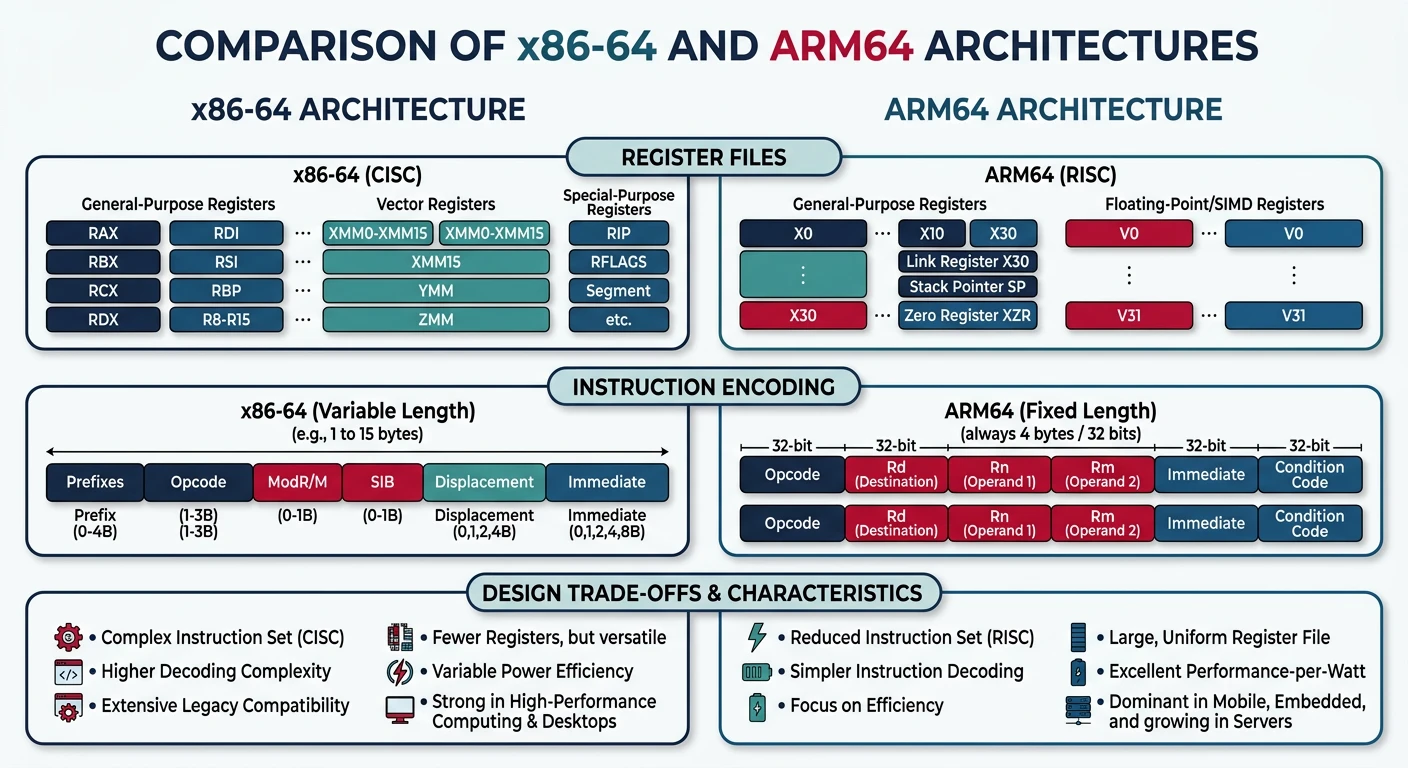
x86 vs ARM
x86 and ARM are the two dominant ISAs today. Let's compare them in detail.
x86-64 vs ARM64: register files, instruction encoding, and architectural trade-offs
x86/x86-64 Architecture
x86-64 General Purpose Registers:
64-bit 32-bit 16-bit 8-bit high/low
┌─────────────────────────────────────────────┐
│ RAX │ EAX │ AX │ AH │ AL │ Accumulator
│ RBX │ EBX │ BX │ BH │ BL │ Base
│ RCX │ ECX │ CX │ CH │ CL │ Counter
│ RDX │ EDX │ DX │ DH │ DL │ Data
│ RSI │ ESI │ SI │ - │ SIL │ Source Index
│ RDI │ EDI │ DI │ - │ DIL │ Destination Index
│ RBP │ EBP │ BP │ - │ BPL │ Base Pointer
│ RSP │ ESP │ SP │ - │ SPL │ Stack Pointer
│ R8-R15 │ R8D-.. │ R8W-.. │ - │R8B-.. │ Extended (64-bit only)
└─────────────────────────────────────────────┘
Special registers:
RIP - Instruction Pointer
RFLAGS - Status flags (zero, carry, overflow, etc.)
Segment registers (legacy): CS, DS, ES, FS, GS, SS
x86 Legacy: x86-64 maintains backward compatibility to 1978! It can run 16-bit code from the original 8086, 32-bit code from the 386, and modern 64-bit code. This compatibility comes at a cost: complex instruction decoding and wasted transistors.
Same Algorithm, Different ISAs:
// C code: int sum = a + b + c;
x86-64:
mov eax, [a]
add eax, [b] ; Can add from memory directly!
add eax, [c]
mov [sum], eax
ARM64:
ldr w0, [x1] ; Load a
ldr w1, [x2] ; Load b
ldr w2, [x3] ; Load c
add w0, w0, w1 ; a + b
add w0, w0, w2 ; + c
str w0, [x4] ; Store sum
x86: 4 instructions, 3 memory accesses embedded
ARM: 6 instructions, 3 explicit loads + 1 store
Apple Silicon: ARM Conquers Laptops
Case Study
In 2020, Apple proved ARM can compete with x86 for high-performance computing:
M1/M2/M3 — ARM-based chips matching or exceeding Intel/AMD
Rosetta 2 — Translates x86 apps to ARM with ~80% native performance
Power Efficiency — MacBook Air with 18+ hour battery life
Unified Memory — CPU and GPU share high-bandwidth memory
This shifted the narrative: ARM is no longer "just for phones"!
Exercises
Practice Exercises
Hands-On
RISC vs CISC: Why might a RISC processor have better power efficiency?
Instruction Decode: Given MIPS instruction 0x012A4020, decode it (hint: it's R-type, funct=32 is ADD)
Addressing Mode: Write the x86 instruction to load array[i*8 + 4] where array is in RBX and i is in RCX
Code Density: Why does x86 generally have higher code density than ARM?
Research: What is RISC-V and why is it gaining attention?
The ISA is the crucial interface between hardware and software. Understanding ISA design helps you write better low-level code and appreciate the trade-offs in processor design.
What You've Learned:
ISA Role — The contract between software and hardware
RISC vs CISC — Simple vs complex instruction philosophies
Modern Reality — x86 is CISC outside, RISC inside
Instruction Formats — Fixed (RISC) vs variable (CISC) length
Addressing Modes — Immediate, register, and memory addressing
x86 vs ARM — Trade-offs between compatibility and efficiency
Continue the Computer Architecture & OS Series
Part 2: Digital Logic & CPU Building Blocks
Logic gates, ALU, registers, datapath, and microarchitecture fundamentals.